## 前言
OpenAI在開源了號稱其英文語音辨識能力已達到人類水準的Whisper項目,且它亦支持其它98種語言的自動語音辨識。Whisper所提供的自動語音識與翻譯任務,它們能將各種語言的語音變成文本,也能將這些文本翻譯成英文。本項目主要的目的是爲了對Whisper模型使用Lora進行微調,目前開源了好幾個模型,具體可以在openai查看,下面列出了常用的幾個模型。另外項目最後還對語音識別加速推理,使用了CTranslate2加速推理,提示一下,加速推理支持直接使用Whisper原模型轉換,並不一定需要微調。
- openai/whisper-tiny
- openai/whisper-base
- openai/whisper-small
- openai/whisper-medium
- openai/whisper-large
- openai/whisper-large-v2
源碼地址:Whisper-Finetune
使用環境:
- Anaconda 3
- Python 3.8
- Pytorch 1.13.1
- Ubuntu 18.04
- GPU A100-PCIE-40GB*1
項目主要程序介紹¶
aishell.py:製作AIShell訓練數據。finetune.py:微調模型。merge_lora.py:合併Whisper和Lora的模型。evaluation.py:評估使用微調後的模型或者Whisper原模型。infer_tfs.py:使用transformers直接調用微調後的模型或者Whisper原模型預測,只適合推理短音頻。infer_ct2.py:使用轉換爲CTranslate2的模型預測,主要參考這個程序用法。infer_gui.py:有GUI界面操作,使用轉換爲CTranslate2的模型預測。infer_server.py:使用轉換爲CTranslate2的模型部署到服務器端,提供給客戶端調用。
歡迎大家掃碼入知識星球討論,知識星球裏面提供項目的模型文件和博主其他相關項目的模型文件,也包括其他一些資源。
模型測試表¶
- 原始模型字錯率測試表。
| 使用模型 | 指定語言 | aishell_test | test_net | test_meeting | 模型獲取 |
|---|---|---|---|---|---|
| whisper-tiny | Chinese | 0.31898 | 0.40482 | 0.75332 | 加入知識星球獲取 |
| whisper-base | Chinese | 0.22196 | 0.30404 | 0.50378 | 加入知識星球獲取 |
| whisper-small | Chinese | 0.13897 | 0.18417 | 0.31154 | 加入知識星球獲取 |
| whisper-medium | Chinese | 0.09538 | 0.13591 | 0.26669 | 加入知識星球獲取 |
| whisper-large | Chinese | 0.08969 | 0.12933 | 0.23439 | 加入知識星球獲取 |
| whisper-large-v2 | Chinese | 0.08817 | 0.12332 | 0.26547 | 加入知識星球獲取 |
- 微調數據集後字錯率測試表。
| 使用模型 | 指定語言 | 數據集 | aishell_test | test_net | test_meeting | 模型獲取 |
|---|---|---|---|---|---|---|
| whisper-tiny | Chinese | AIShell | 0.13043 | 0.4463 | 0.57728 | 加入知識星球獲取 |
| whisper-base | Chinese | AIShell | 0.08999 | 0.33089 | 0.40713 | 加入知識星球獲取 |
| whisper-small | Chinese | AIShell | 0.05452 | 0.19831 | 0.24229 | 加入知識星球獲取 |
| whisper-medium | Chinese | AIShell | 0.03681 | 0.13073 | 0.16939 | 加入知識星球獲取 |
| whisper-large-v2 | Chinese | AIShell | 0.03139 | 0.12201 | 0.15776 | 加入知識星球獲取 |
| whisper-tiny | Chinese | WenetSpeech | 0.17711 | 0.24783 | 0.39226 | 加入知識星球獲取 |
| whisper-large-v2 | Chinese | WenetSpeech | 0.05443 | 0.10087 | 0.19087 | 加入知識星球獲取 |
- 未加速和加速後的推理速度測試表,使用GPU爲GTX3090(24G)。
| 使用模型 | 原生模型即時率(float16) | 轉換CTranslate2加速後即時率(float16) | 轉換CTranslate2加速後即時率(int8_float16) |
|---|---|---|---|
| whisper-tiny | 0.03 | 0.06 | 0.06 |
| whisper-base | 0.04 | 0.06 | 0.06 |
| whisper-small | 0.08 | 0.08 | 0.08 |
| whisper-medium | 0.13 | 0.10 | 0.10 |
| whisper-large-v2 | 0.19 | 0.12 | 0.12 |
- 經過處理的數據列表。
| 數據列表處理方式 | AiShell | WenetSpeech |
|---|---|---|
| 添加標點符號 | 加入知識星球獲取 | 加入知識星球獲取 |
| 添加標點符號和時間戳 | 加入知識星球獲取 | 加入知識星球獲取 |
重要說明:
1. 在評估的時候移除模型輸出的標點符號,並把繁體中文轉成簡體中文。
2. aishell_test爲AIShell的測試集,test_net和test_meeting爲WenetSpeech的測試集。
3. RTF= 所有音頻總時間(單位秒) / ASR識別所有音頻處理時間(單位秒)。
4. 測試速度的音頻爲dataset/test.wav,時長爲8秒。
5. 訓練數據使用的是帶標點符號的數據,字錯率高一點。
6. 微調AiShell數據不帶時間戳,微調WenetSpeech帶時間戳。
安裝環境¶
- 首先安裝的是Pytorch的GPU版本,如果已經安裝過了,請跳過。
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia
- 安裝所需的依賴庫。
python -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
準備數據¶
訓練的數據集如下,是一個jsonlines的數據列表,也就是每一行都是一個JSON數據,數據格式如下。Whisper是支持有標點符號的,所以訓練的數據集中可以帶有標點符號。本項目提供了一個製作AIShell數據集的程序aishell.py,執行這個程序可以自動下載並生成如下列格式的訓練集和測試集,注意: 這個程序可以通過指定AIShell的壓縮文件來跳過下載過程的,如果直接下載會非常慢,可以使用一些如迅雷等下載器下載該數據集,然後通過參數--filepath指定下載的壓縮文件路徑,如/home/test/data_aishell.tgz。如果不使用時間戳訓練,可以不包含sentences部分的數據。
{
"audio": {
"path": "dataset/0.wav"
},
"sentence": "近幾年,不但我用書給女兒壓歲,也勸說親朋不要給女兒壓歲錢,而改送壓歲書。",
"sentences": [
{
"start": 0,
"end": 1.4,
"text": "近幾年,"
},
{
"start": 1.42,
"end": 8.4,
"text": "不但我用書給女兒壓歲,也勸說親朋不要給女兒壓歲錢,而改送壓歲書。"
}
],
"duration": 7.37
}
微調模型¶
準備好數據之後,就可以開始微調模型了。訓練最重要的兩個參數分別是,--base_model指定微調的Whisper模型,這個參數值需要在HuggingFace存在的,這個不需要提前下載,啓動訓練時可以自動下載,當然也可以提前下載,那麼--base_model指定就是路徑,同時--local_files_only設置爲True。第二個--output_path是是訓練時保存的Lora檢查點路徑,因爲我們使用Lora來微調模型。如果想存足夠的話,最好將--use_8bit設置爲False,這樣訓練速度快很多。其他更多的參數請查看這個程序。
單卡訓練¶
單卡訓練命令如下,Windows系統可以不添加CUDA_VISIBLE_DEVICES參數。
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/
多卡訓練¶
多卡訓練有兩種方法,分別是torchrun和accelerate,開發者可以根據自己的習慣使用對應的方式。
- 使用torchrun啓動多卡訓練,命令如下,通過
--nproc_per_node指定使用的顯卡數量。
torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/
- 使用accelerate啓動多卡訓練,如果是第一次使用accelerate,要配置訓練參數,方式如下。
首先配置訓練參數,過程是讓開發者回答幾個問題,基本都是默認就可以,但有幾個參數需要看實際情況設置。
accelerate config
大概過程就是這樣:
----------------------------------In which compute environment are you running?
This machine
----------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
----------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
配置完成之後,可以使用以下命令查看配置。
accelerate env
開始訓練命令如下。
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/
輸出日誌如下:
{'loss': 0.9098, 'learning_rate': 0.000999046843662503, 'epoch': 0.01}
{'loss': 0.5898, 'learning_rate': 0.0009970611012927184, 'epoch': 0.01}
{'loss': 0.5583, 'learning_rate': 0.0009950753589229333, 'epoch': 0.02}
{'loss': 0.5469, 'learning_rate': 0.0009930896165531485, 'epoch': 0.02}
{'loss': 0.5959, 'learning_rate': 0.0009911038741833634, 'epoch': 0.03}
合併模型¶
微調完成之後會有兩個模型,第一個是Whisper基礎模型,第二個是Lora模型,需要把這兩個模型合併之後才能之後的操作。這個程序只需要傳遞兩個參數,--lora_model指定的是訓練結束後保存的Lora模型路徑,注意如何不是最後的checkpoint-final後面還有adapter_model文件夾,第二個--output_dir是合併後模型的保存目錄。
python merge_lora.py --lora_model=output/checkpoint-final --output_dir=models/
評估模型¶
執行以下程序進行評估模型,最重要的兩個參數分別是。第一個--model_path指定的是合併後的模型路徑,同時也支持直接使用Whisper原模型,例如直接指定openai/whisper-large-v2,第二個是--metric指定的是評估方法,例如有字錯率cer和詞錯率wer。提示: 沒有微調的模型,可能輸出帶有標點符號,影響準確率。其他更多的參數請查看這個程序。
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer
預測¶
執行以下程序進行語音識別,這個使用transformers直接調用微調後的模型或者Whisper原模型預測,只適合推理短音頻,長語音還是參考infer_ct2.py的使用方式。第一個--audio_path參數指定的是要預測的音頻路徑。第二個--model_path指定的是合併後的模型路徑,同時也支持直接使用Whisper原模型,例如直接指定openai/whisper-large-v2。其他更多的參數請查看這個程序。
python infer_tfs.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune
加速預測¶
衆所周知,直接使用Whisper模型推理是比較慢的,所以這裏提供了一個加速的方式,主要是使用了CTranslate2進行加速,首先要轉換模型,把合併後的模型轉換爲CTranslate2模型。如下命令,--model參數指定的是合併後的模型路徑,同時也支持直接使用Whisper原模型,例如直接指定openai/whisper-large-v2。--output_dir參數指定的是轉換後的CTranslate2模型路徑,--quantization參數指定的是量化模型大小,不希望量化模型的可以直接去掉這個參數。
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-ct2 --copy_files tokenizer.json --quantization float16
執行以下程序進行加速語音識別,--audio_path參數指定的是要預測的音頻路徑。--model_path指定的是轉換後的CTranslate2模型。其他更多的參數請查看這個程序。
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-ct2
輸出結果如下:
{
"language": "zh",
"duration": 8.39,
"results": [
{
"start": 0.0,
"end": 8.39,
"text": "近幾年不但我用書給女兒壓歲也勸說親朋友不要給女兒壓歲錢而改送壓歲書"
}
],
"text": "近幾年不但我用書給女兒壓歲也勸說親朋友不要給女兒壓歲錢而改送壓歲書"
}
GUI界面預測¶
這裏同樣是使用了CTranslate2進行加速,轉換模型方式看上面文檔。--model_path指定的是轉換後的CTranslate2模型。其他更多的參數請查看這個程序。
python infer_gui.py --model_path=models/whisper-tiny-ct2
啓動後界面如下:
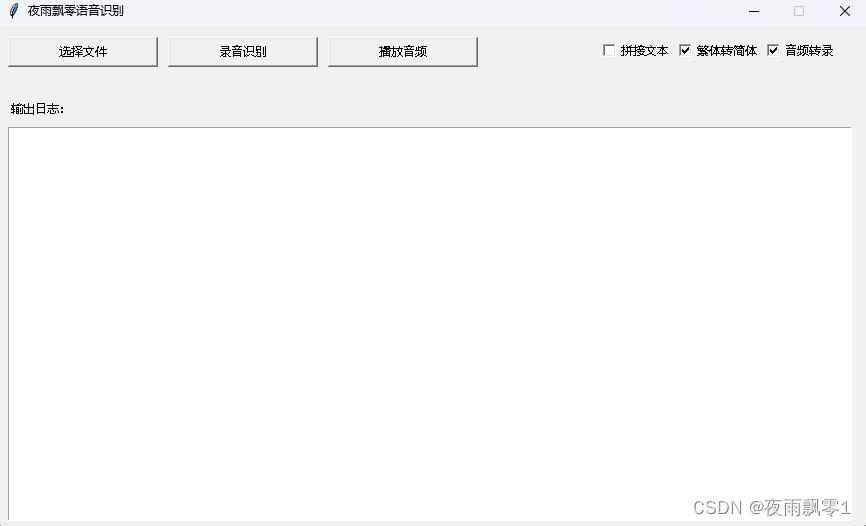
Web部署¶
Web部署同樣是使用了CTranslate2進行加速,轉換模型方式看上面文檔。--host指定服務啓動的地址,這裏設置爲0.0.0.0,即任何地址都可以訪問。--port指定使用的端口號。--model_path指定的是轉換後的CTranslate2模型。--num_workers指定是使用多少個線程併發推理,這在Web部署上很重要,當有多個併發訪問是可以同時推理。其他更多的參數請查看這個程序。
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-ct2 --num_workers=2
接口文檔¶
目前提供兩個接口,普通的識別接口/recognition和流式返回結果/recognition_stream,注意這個流式是指流式返回識別結果,同樣是上傳完整的音頻,然後流式返回識別結果,這種方式針對長語音識別體驗非常好。他們的文檔接口是完全一致的,接口參數如下。
| 字段 | 是否必須 | 類型 | 默認值 | 說明 |
|---|---|---|---|---|
| audio | 是 | File | 要識別的音頻文件 | |
| to_simple | 否 | int | 1 | 是否繁體轉簡體 |
| remove_pun | 否 | int | 0 | 是否移除標點符號 |
| task | 否 | String | transcribe | 識別任務類型,支持transcribe和translate |
爲了方便理解,這裏提供了調用Web接口的Python代碼,下面的是/recognition的調用方式。
import requests
response = requests.post(url="http://127.0.0.1:5000/recognition",
files=[("audio", ("test.wav", open("dataset/test.wav", 'rb'), 'audio/wav'))],
json={"to_simple": 1, "remove_pun": 0, "task": "transcribe"}, timeout=20)
print(response.text)
下面的是/recognition_stream的調用方式。
import json
import requests
response = requests.post(url="http://127.0.0.1:5000/recognition_stream",
files=[("audio", ("test.wav", open("dataset/test_long.wav", 'rb'), 'audio/wav'))],
json={"to_simple": 1, "remove_pun": 0, "task": "transcribe"}, stream=True, timeout=20)
for chunk in response.iter_lines(decode_unicode=False, delimiter=b"\0"):
if chunk:
result = json.loads(chunk.decode())
text = result["result"]
start = result["start"]
end = result["end"]
print(f"[{start} - {end}]:{text}")
提供的測試頁面如下:
首頁http://127.0.0.1:5000/ 的頁面如下:
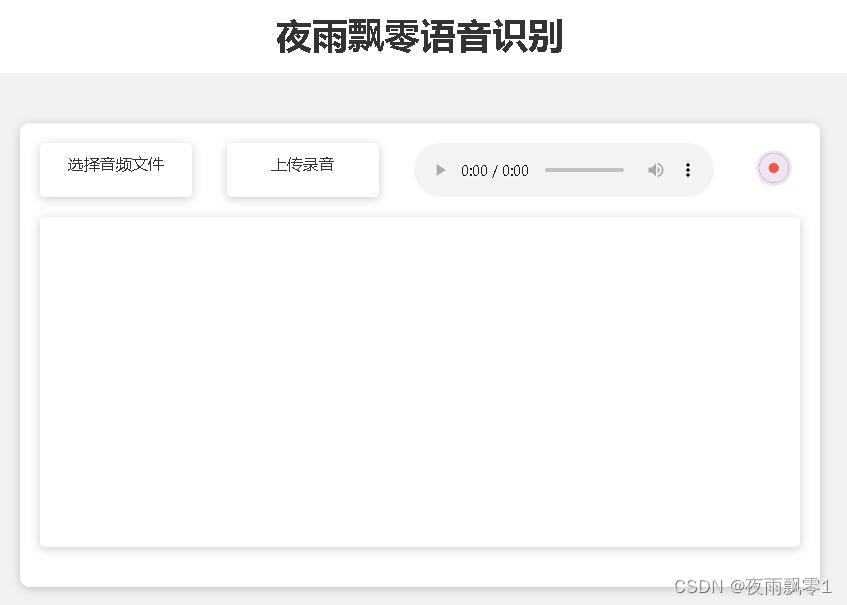
文檔頁面http://127.0.0.1:5000/docs 的頁面如下:

Android部署¶
安裝部署的源碼在AndroidDemo目錄下。
轉換模型¶
- 首先要克隆Whisper原生的源碼,因爲需要它的一些文件,請在
Whisper-Finetune項目根目錄下執行下面命令。
git clone https://github.com/openai/whisper.git
- 然後開始轉換模型,請在
Whisper-Finetune項目根目錄下執行convert-ggml.py程序,把模型轉換爲Android項目所需的ggml格式的模型,需要轉換的模型可以是原始的Transformers模型,也可以是微調的模型。
python convert-ggml.py --model_dir=models/whisper-tiny-finetune/ --whisper_dir=whisper/ --output_path=models/ggml-model.bin
- 把模型放在Android項目的
app/src/main/assets/models目錄下,然後就可以使用Android Studio打開項目了。
編譯說明¶
- 默認使用的NDK版本是
25.2.9519653,如果下面修改其他版本,要修改app/build.gradle裏面的配置。 - 注意,在真正使用時,一定要發佈
release的APK包,這樣推理速度才快。 - 本項目已經發布了
release的APK包,請在Whisper-Finetune項目主頁的最後掃碼下載。
效果圖¶
Windows桌面應用¶
程序在WhisperDesktop目錄下。該程序是使用Whisper翻譯得的,源碼可以前面該項目查看。該程序使用的模型格式是GGML格式,跟Android部署的一樣,所以需要轉換模型格式才能使用。
轉換模型¶
- 首先要克隆Whisper原生的源碼,因爲需要它的一些文件,請在
Whisper-Finetune項目根目錄下執行下面命令。
git clone https://github.com/openai/whisper.git
- 然後開始轉換模型,請在
Whisper-Finetune項目根目錄下執行convert-ggml.py程序,把模型轉換爲Android項目所需的ggml格式的模型,需要轉換的模型可以是原始的Transformers模型,也可以是微調的模型。
python convert-ggml.py --model_dir=models/whisper-tiny-finetune/ --whisper_dir=whisper/ --output_path=models/whisper-tiny-finetune-ggml.bin
效果圖¶
效果圖如下:
圖1:加載模型頁面
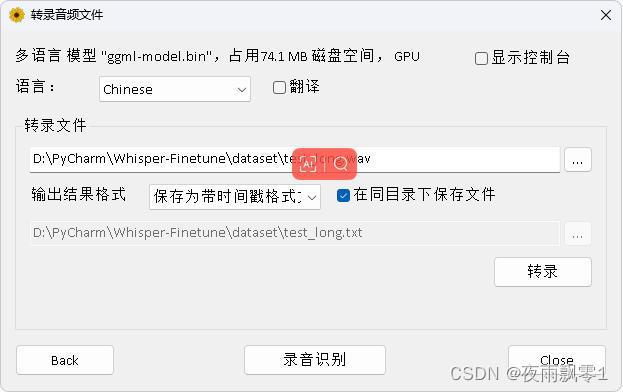
圖2:選擇音頻文件轉錄
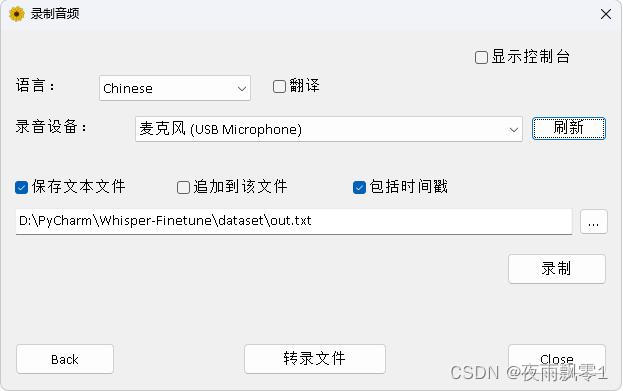
圖3:錄音轉錄
參考資料¶
- https://github.com/huggingface/peft
- https://github.com/guillaumekln/faster-whisper
- https://github.com/ggerganov/whisper.cpp
- https://github.com/Const-me/Whisper