# DeepSpeech2中文語音識別
本項目是基於PaddlePaddle的DeepSpeech 項目開發的,做了較大的修改,方便訓練中文自定義數據集,同時也方便測試和使用。DeepSpeech2是基於PaddlePaddle實現的端到端自動語音識別(ASR)引擎,其論文爲《Baidu’s Deep Speech 2 paper》 ,本項目同時還支持各種數據增強方法,以適應不同的使用場景。支持在Windows,Linux下訓練和預測,支持Nvidia Jetson等開發板推理預測。
本項目使用的環境:
- Python 3.7
- PaddlePaddle 2.1.2
- Windows or Ubuntu
本教程源碼:https://github.com/yeyupiaoling/PaddlePaddle-DeepSpeech
模型下載¶
| 數據集 | 卷積層數量 | 循環神經網絡的數量 | 循環神經網絡的大小 | 測試集字錯率 | 下載地址 |
|---|---|---|---|---|---|
| aishell(179小時) | 2 | 3 | 1024 | 0.084532 | 點擊下載 |
| free_st_chinese_mandarin_corpus(109小時) | 2 | 3 | 1024 | 0.170260 | 點擊下載 |
| thchs_30(34小時) | 2 | 3 | 1024 | 0.026838 | 點擊下載 |
說明: 這裏提供的是訓練參數,如果要用於預測,還需要執行導出模型,使用的解碼方法是集束搜索。
有問題歡迎提 issue 交流
搭建環境¶
本人用的就是本地環境和使用Anaconda,並創建了Python3.7的虛擬環境,建議讀者也本地環境,方便交流,出現安裝問題,隨時提issue 。
- 首先安裝的是PaddlePaddle 2.1.2的GPU版本,如果已經安裝過了,請跳過。
conda install paddlepaddle-gpu==2.1.2 cudatoolkit=10.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
- 安裝其他依賴庫。
python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
數據準備¶
- 在
download_data目錄下是公開數據集的下載和製作訓練數據列表和詞彙表的,本項目提供了下載公開的中文普通話語音數據集,分別是Aishell,Free ST-Chinese-Mandarin-Corpus,THCHS-30 這三個數據集,總大小超過28G。下載這三個數據只需要執行一下代碼即可,當然如果想快速訓練,也可以只下載其中一個。注意:noise.py可下載可不下載,這是用於訓練時數據增強的,如果不想使用噪聲數據增強,可以不用下載。
```shell script
cd download_data/
python aishell.py
python free_st_chinese_mandarin_corpus.py
python thchs_30.py
python noise.py
**注意:** 以上代碼只支持在Linux下執行,如果是Windows的話,可以獲取程序中的`DATA_URL`單獨下載,建議用迅雷等下載工具,這樣下載速度快很多。然後把`download()`函數改爲文件的絕對路徑,如下,我把`aishell.py`的文件單獨下載,然後替換`download()`函數,再執行該程序,就會自動解壓文件文本生成數據列表。
```python
# 把這行代碼
filepath = download(url, md5sum, target_dir)
# 修改爲
filepath = "D:\\Download\\data_aishell.tgz"
- 如果開發者有自己的數據集,可以使用自己的數據集進行訓練,當然也可以跟上面下載的數據集一起訓練。自定義的語音數據需要符合以下格式,另外對於音頻的採樣率,本項目默認使用的是16000Hz,在
create_data.py中也提供了統一音頻數據的採樣率轉換爲16000Hz,只要is_change_frame_rate參數設置爲True就可以。- 語音文件需要放在
PaddlePaddle-DeepSpeech/dataset/audio/目錄下,例如我們有個wav的文件夾,裏面都是語音文件,我們就把這個文件存放在PaddlePaddle-DeepSpeech/dataset/audio/。 - 然後把數據列表文件存在
PaddlePaddle-DeepSpeech/dataset/annotation/目錄下,程序會遍歷這個文件下的所有數據列表文件。例如這個文件下存放一個my_audio.txt,它的內容格式如下。每一行數據包含該語音文件的相對路徑和該語音文件對應的中文文本,要注意的是該中文文本只能包含純中文,不能包含標點符號、阿拉伯數字以及英文字母。
```shell script
dataset/audio/wav/0175/H0175A0171.wav 我需要把空調溫度調到二十度
dataset/audio/wav/0175/H0175A0377.wav 出彩中國人
dataset/audio/wav/0175/H0175A0470.wav 據克而瑞研究中心監測
dataset/audio/wav/0175/H0175A0180.wav 把溫度加大到十八
- 語音文件需要放在
3. 最後執行下面的數據集處理腳本,這個是把我們的數據集生成三個JSON格式的數據列表,分別是`manifest.test、manifest.train、manifest.noise`。然後建立詞彙表,把所有出現的字符都存放子在`zh_vocab.txt`文件中,一行一個字符。最後計算均值和標準差用於歸一化,默認使用全部的語音計算均值和標準差,並將結果保存在`mean_std.npz`中。以上生成的文件都存放在`PaddlePaddle-DeepSpeech/dataset/`目錄下。
```shell script
# 生成數據列表
python create_data.py
訓練模型¶
- 執行訓練腳本,開始訓練語音識別模型, 每訓練一輪和每2000個batch都會保存一次模型,模型保存在
PaddlePaddle-DeepSpeech/models/param/目錄下,默認會使用數據增強訓練,如何不想使用數據增強,只需要將參數augment_conf_path設置爲None即可。關於數據增強,請查看數據增強部分。如果沒有關閉測試,在每一輪訓練結果之後,都會執行一次測試計算模型在測試集的準確率。執行訓練時,如果是Linux下,通過CUDA_VISIBLE_DEVICES可以指定多卡訓練。
```shell script
CUDA_VISIBLE_DEVICES=0,1 python train.py
- 在訓練過程中,程序會使用VisualDL記錄訓練結果,可以通過以下的命令啓動VisualDL。
```shell
visualdl --logdir=log --host=0.0.0.0
- 然後再瀏覽器上訪問
http://localhost:8040可以查看結果顯示,如下。
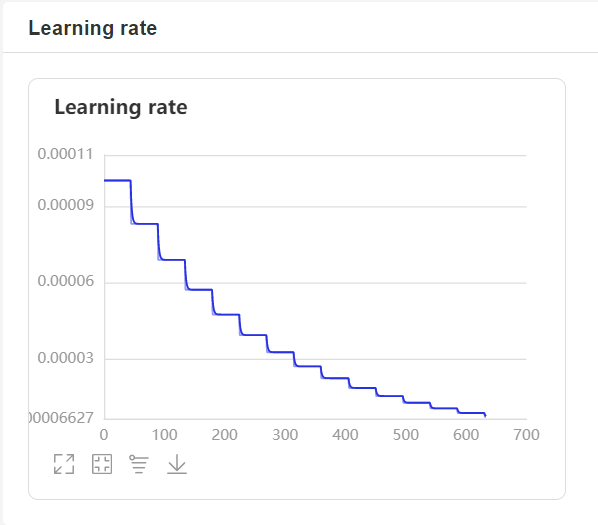
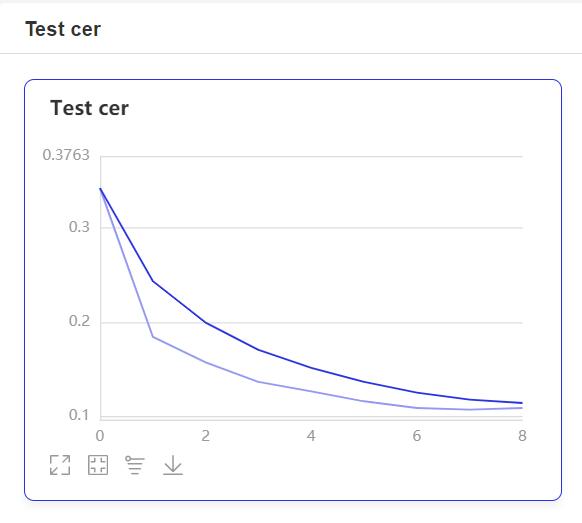
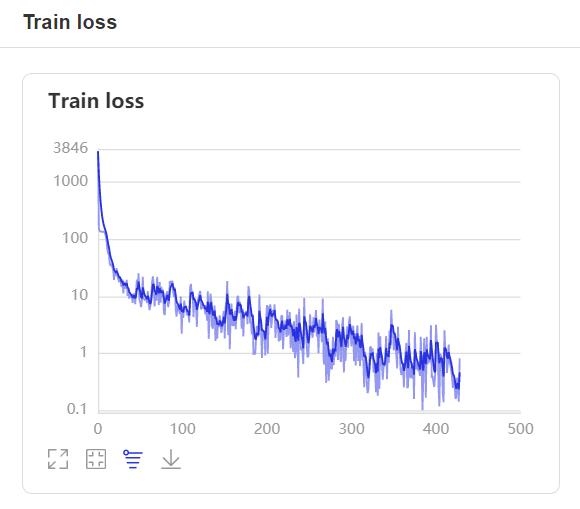
評估¶
執行下面這個腳本對模型進行評估,通過字符錯誤率來評價模型的性能。
python eval.py --resume_model=./models/param/50.pdparams
輸出結果:
----------- Configuration Arguments -----------
alpha: 1.2
batch_size: 64
beam_size: 10
beta: 0.35
cutoff_prob: 1.0
cutoff_top_n: 40
decoding_method: ctc_greedy
error_rate_type: cer
lang_model_path: ./lm/zh_giga.no_cna_cmn.prune01244.klm
mean_std_path: ./dataset/mean_std.npz
resume_model: ./models/param/50.pdparams
num_conv_layers: 2
num_proc_bsearch: 8
num_rnn_layers: 3
rnn_layer_size: 1024
test_manifest: ./dataset/manifest.test
use_gpu: True
vocab_path: ./dataset/zh_vocab.txt
------------------------------------------------
W0318 16:38:49.200599 19032 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 75, Driver API Version: 11.0, Runtime API Version: 10.0
W0318 16:38:49.242089 19032 device_context.cc:260] device: 0, cuDNN Version: 7.6.
[INFO 2021-03-18 16:38:53,689 eval.py:83] 開始評估 ...
錯誤率:[cer] (64/284) = 0.077040
錯誤率:[cer] (128/284) = 0.062989
錯誤率:[cer] (192/284) = 0.055674
錯誤率:[cer] (256/284) = 0.054918
錯誤率:[cer] (284/284) = 0.055882
消耗時間:44526ms, 總錯誤率:[cer] (284/284) = 0.055882
[INFO 2021-03-18 16:39:38,215 eval.py:117] 完成評估!
導出模型¶
訓練保存的或者下載作者提供的模型都是模型參數,我們要將它導出爲預測模型,這樣可以直接使用模型,不再需要模型結構代碼,同時使用Inference接口可以加速預測,在一些設備也可以使用TensorRT加速。
python export_model.py --resume_model=./models/param/50.pdparams
輸出結果:
成功加載了預訓練模型:./models/param/50.pdparams
----------- Configuration Arguments -----------
mean_std_path: ./dataset/mean_std.npz
num_conv_layers: 2
num_rnn_layers: 3
rnn_layer_size: 1024
pretrained_model: ./models/param/50.pdparams
save_model_path: ./models/infer/
use_gpu: True
vocab_path: ./dataset/zh_vocab.txt
------------------------------------------------
成功導出模型,模型保存在:./models/infer/
本地預測¶
我們可以使用這個腳本使用模型進行預測,如果如何還沒導出模型,需要執行導出模型操作把模型參數導出爲預測模型,通過傳遞音頻文件的路徑進行識別,通過參數--wav_path指定需要預測的音頻路徑。支持中文數字轉阿拉伯數字,將參數--to_an設置爲True即可,默認爲True。
```shell script
python infer_path.py –wav_path=./dataset/test.wav
輸出結果:
----------- Configuration Arguments -----------
alpha: 1.2
beam_size: 10
beta: 0.35
cutoff_prob: 1.0
cutoff_top_n: 40
decoding_method: ctc_greedy
enable_mkldnn: False
is_long_audio: False
lang_model_path: ./lm/zh_giga.no_cna_cmn.prune01244.klm
mean_std_path: ./dataset/mean_std.npz
model_dir: ./models/infer/
to_an: True
use_gpu: True
vocab_path: ./dataset/zh_vocab.txt
wav_path: ./dataset/test.wav
消耗時間:132, 識別結果: 近幾年不但我用書給女兒兒壓歲也勸說親朋不要給女兒壓歲錢而改送壓歲書, 得分: 94
# 長語音預測
通過參數`--is_long_audio`可以指定使用長語音識別方式,這種方式通過VAD分割音頻,再對短音頻進行識別,拼接結果,最終得到長語音識別結果。
```shell script
python infer_path.py --wav_path=./dataset/test_vad.wav --is_long_audio=True
Web部署¶
在服務器執行下面命令通過創建一個Web服務,通過提供HTTP接口來實現語音識別。啓動服務之後,如果在本地運行的話,在瀏覽器上訪問http://localhost:5000,否則修改爲對應的 IP地址。打開頁面之後可以選擇上傳長音或者短語音音頻文件,也可以在頁面上直接錄音,錄音完成之後點擊上傳,播放功能只支持錄音的音頻。支持中文數字轉阿拉伯數字,將參數--to_an設置爲True即可,默認爲True。
```shell script
python infer_server.py
打開頁面如下:
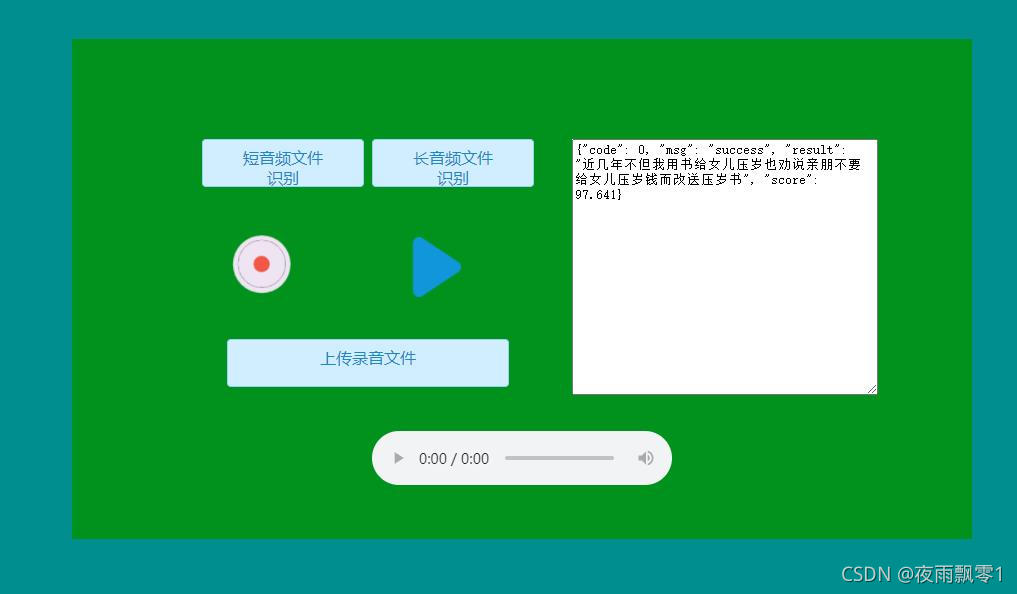
# GUI界面部署
通過打開頁面,在頁面上選擇長語音或者短語音進行識別,也支持錄音識別,同時播放識別的音頻。默認使用的是貪心解碼策略,如果需要使用集束搜索方法的話,需要在啓動參數的時候指定。
```shell script
python infer_gui.py
打開界面如下:
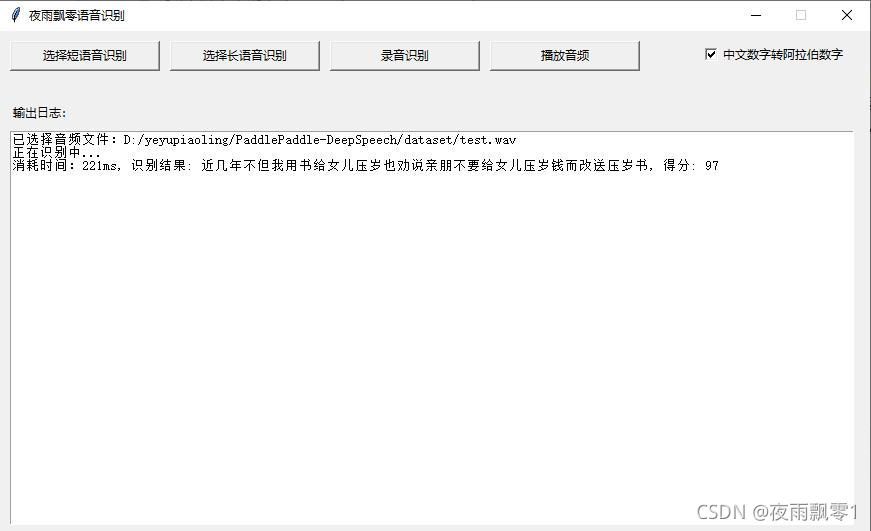
相關項目¶
- 基於PaddlePaddle實現的聲紋識別:VoiceprintRecognition-PaddlePaddle
- 基於PaddlePaddle 2.0實現的語音識別:PPASR
- 基於Pytorch實現的語音識別:MASR