> 原文博客:Doi技術團隊
鏈接地址:https://blog.doiduoyi.com/authors/1584446358138
初心:記錄優秀的Doi技術團隊學習經歷
*本篇文章基於 PaddlePaddle 0.11.0、Python 2.7
數據集的介紹¶
本次項目中使用的是一個32*32的彩色圖像的數據集CIFAR-10,CIFAR-10數據集包含10個類的60000個32x32彩色圖像,每個類有6000個圖像。有50000個訓練圖像和10000個測試圖像。數據集分爲五個訓練batch和一個測試batch,每個batch有10000個圖像。測試batch包含來自每個類1000個隨機選擇的圖像。訓練batch按照隨機順序包含剩餘的圖像,但是一些訓練batch可能包含比另一個更多的圖像。在他們之間,訓練的batch包含每個類別正好5000張圖片。

下表是數據集文件內部的結構,如上所說,有五個訓練batch和一個測試batch:
|文件名稱|大小|說明|
| :—: |:—:| :—:|
|test_batch|31.0M|10000個測試圖像|
|data_batch_1|31.0M|10000個訓練圖像|
|data_batch_2|31.0M|10000個訓練圖像|
|data_batch_3|31.0M|10000個訓練圖像|
|data_batch_4|31.0M|10000個訓練圖像|
|data_batch_5|31.0M|10000個訓練圖像|
整個文件的說明:
|文件名稱|大小|說明|
| :—: |:—:| :—:|
|cifar-10-python.tar.gz|170.5M|10個類別,60000個彩色圖像,其中50000個訓練圖像,10000個測試圖像|
同樣的,在訓練時開發者不需要單獨去下載該數據集,PaddlePaddle已經幫我們封裝好了,在我們調用paddle.dataset.cifar的時候,會自動在下載到緩存目錄/home/username/.cache/paddle/dataset/cifar下,當以後再使用的時候,可以直接在緩存中獲取,就不會去下載了.
開始訓練模型¶
定義神經網絡模型¶
我們這裏使用的是VGG神經網絡,這個模型是牛津大學VGG(Visual Geometry Group)組在2014年ILSVRC提出的,VGG神經模型的核心是五組卷積操作,每兩組之間做Max-Pooling空間降維。同一組內採用多次連續的3X3卷積,卷積核的數目由較淺組的64增多到最深組的512,同一組內的卷積核數目是一樣的。卷積之後接兩層全連接層,之後是分類層。由於每組內卷積層的不同,有11、13、16、19層這幾種模型,在本章文章中使用到的是VGG16。VGG神經網絡也是在ImageNet上首次公開超過人眼識別的模型。
這個VGG不是原來設的VGG神經模型,由於CIFAR10圖片大小和數量相比ImageNet數據小很多,因此這裏的模型針對CIFAR10數據做了一定的適配,卷積部分引入了BN層和Dropout操作。conv_with_batchnorm可以設置是否說使用BN層。BN層全稱爲:Batch Normalization,在沒有使用BN層之前:
- 參數的更新,使得每層的輸入輸出分佈發生變化,稱作ICS(Internal Covariate Shift)
- 差異hui會隨着網絡深度增大而增大
- 需要更小的學習率和較好的參數進行初始化
加入了BN層之後:
- 可以使用較大的學習率
- 可以減少對參數初始化的依賴
- 可以擬製梯度的彌散
- 可以起到正則化的作用
- 可以加速模型收斂速度
以下就是vgg.py的文件中定義VGG神經網絡模型的Python代碼:
# coding=utf-8
import paddle.v2 as paddle
# ***********************定義VGG卷積神經網絡模型***************************************
def vgg_bn_drop(datadim):
# 獲取輸入數據大小
img = paddle.layer.data(name="image",
type=paddle.data_type.dense_vector(datadim))
def conv_block(ipt, num_filter, groups, dropouts, num_channels=None):
return paddle.networks.img_conv_group(
input=ipt,
num_channels=num_channels,
pool_size=2,
pool_stride=2,
conv_num_filter=[num_filter] * groups,
conv_filter_size=3,
conv_act=paddle.activation.Relu(),
conv_with_batchnorm=True,
conv_batchnorm_drop_rate=dropouts,
pool_type=paddle.pooling.Max())
conv1 = conv_block(img, 64, 2, [0.3, 0], 3)
conv2 = conv_block(conv1, 128, 2, [0.4, 0])
conv3 = conv_block(conv2, 256, 3, [0.4, 0.4, 0])
conv4 = conv_block(conv3, 512, 3, [0.4, 0.4, 0])
conv5 = conv_block(conv4, 512, 3, [0.4, 0.4, 0])
drop = paddle.layer.dropout(input=conv5, dropout_rate=0.5)
fc1 = paddle.layer.fc(input=drop, size=512, act=paddle.activation.Linear())
bn = paddle.layer.batch_norm(input=fc1,
act=paddle.activation.Relu(),
layer_attr=paddle.attr.Extra(drop_rate=0.5))
fc2 = paddle.layer.fc(input=bn, size=512, act=paddle.activation.Linear())
# 通過神經網絡模型再使用Softmax獲得分類器(全連接)
out = paddle.layer.fc(input=fc2,
size=10,
act=paddle.activation.Softmax())
return out
然後創建一個train.py的Python文件來編寫訓練的代碼
導入依賴包¶
首先要先導入依賴包,其中就包含了最重要的PaddlePaddle的V2包
# coding:utf-8
import sys
import paddle.v2 as paddle
from PIL import Image
import numpy as np
import os
初始化Paddle¶
然後我們創建一個類,再在類中創建一個初始化函數,在初始化函數中來初始化我們的PaddlePaddle
class TestCIFAR:
# ***********************初始化操作***************************************
def __init__(self):
# 初始化paddpaddle,只是用CPU,把GPU關閉
paddle.init(use_gpu=False, trainer_count=2)
獲取參數¶
訓練參數可以通過使用損失函數創建一個訓練參數,也可以通過使用之前訓練好的參數初始化訓練參數,使用訓練好的參數來初始化訓練參數,不僅可以使用之前的訓練好的參數作爲在此之上再繼續訓練,而且在某種情況下還防止出現浮點異常,比如SSD神經網絡很容易出現浮點異常,就可以使用預訓練的參數作爲初始化訓練參數,來解決出現浮點異常的問題。
該函數可以通過輸入是否是參數文件路徑,或者是損失函數,如果是參數文件路徑,就使用之前訓練好的參數生產參數。如果不傳入參數文件路徑,那就使用傳入的損失函數生成參數。
# **********************獲取參數***************************************
def get_parameters(self, parameters_path=None, cost=None):
if not parameters_path:
# 使用cost創建parameters
if not cost:
print "請輸入cost參數"
else:
# 根據損失函數創建參數
parameters = paddle.parameters.create(cost)
return parameters
else:
# 使用之前訓練好的參數
try:
# 使用訓練好的參數
with open(parameters_path, 'r') as f:
parameters = paddle.parameters.Parameters.from_tar(f)
return parameters
except Exception as e:
raise NameError("你的參數文件錯誤,具體問題是:%s" % e)
創建訓練器¶
創建訓練器要3個參數,分別是損失函數,參數,優化方法.通過圖像的標籤信息和分類器生成損失函數。
參數可以選擇是使用之前訓練好的參數,然後在此基礎上再進行訓練,又或者是使用損失函數生成初始化參數。
然後再生成優化方法.就可以創建一個訓練器了.
# ***********************獲取訓練器***************************************
def get_trainer(self):
# 數據大小
datadim = 3 * 32 * 32
# 獲得圖片對於的信息標籤
lbl = paddle.layer.data(name="label",
type=paddle.data_type.integer_value(10))
# 獲取全連接層,也就是分類器
out = vgg_bn_drop(datadim=datadim)
# 獲得損失函數
cost = paddle.layer.classification_cost(input=out, label=lbl)
# 使用之前保存好的參數文件獲得參數
# parameters = self.get_parameters(parameters_path="../model/model.tar")
# 使用損失函數生成參數
parameters = self.get_parameters(cost=cost)
'''
定義優化方法
learning_rate 迭代的速度
momentum 跟前面動量優化的比例
regularzation 正則化,防止過擬合
'''
momentum_optimizer = paddle.optimizer.Momentum(
momentum=0.9,
regularization=paddle.optimizer.L2Regularization(rate=0.0002 * 128),
learning_rate=0.1 / 128.0,
learning_rate_decay_a=0.1,
learning_rate_decay_b=50000 * 100,
learning_rate_schedule="discexp")
'''
創建訓練器
cost 分類器
parameters 訓練參數,可以通過創建,也可以使用之前訓練好的參數
update_equation 優化方法
'''
trainer = paddle.trainer.SGD(cost=cost,
parameters=parameters,
update_equation=momentum_optimizer)
return trainer
開始訓練¶
要啓動訓練要4個參數,分別是訓練數據,訓練的輪數,訓練過程中的事件處理,輸入數據和標籤的對應關係.
訓練數據:PaddlePaddle已經有封裝好的API,可以直接獲取CIFAR的數據.
訓練輪數:表示我們要訓練多少輪,次數越多準確率越高,最終會穩定在一個固定的準確率上.不得不說的是這個會比MNIST數據集的速度慢很多
事件處理:訓練過程中的一些事件處理,比如會在每個batch打印一次日誌,在每個pass之後保存一下參數和測試一下測試數據集的預測準確率.
輸入數據和標籤的對應關係:說明輸入數據是第0維度,標籤是第1維度
# ***********************開始訓練***************************************
def start_trainer(self):
# 獲得數據
reader = paddle.batch(reader=paddle.reader.shuffle(reader=paddle.dataset.cifar.train10(),
buf_size=50000),
batch_size=128)
# 指定每條數據和padd.layer.data的對應關係
feeding = {"image": 0, "label": 1}
# 定義訓練事件
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print "\nPass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics)
else:
sys.stdout.write('.')
sys.stdout.flush()
# 每一輪訓練完成之後
if isinstance(event, paddle.event.EndPass):
# 保存訓練好的參數
model_path = '../model'
if not os.path.exists(model_path):
os.makedirs(model_path)
with open(model_path + '/model.tar', 'w') as f:
trainer.save_parameter_to_tar(f)
# 測試準確率
result = trainer.test(reader=paddle.batch(reader=paddle.dataset.cifar.test10(),
batch_size=128),
feeding=feeding)
print "\nTest with Pass %d, %s" % (event.pass_id, result.metrics)
# 獲取訓練器
trainer = self.get_trainer()
'''
開始訓練
reader 訓練數據
num_passes 訓練的輪數
event_handler 訓練的事件,比如在訓練的時候要做一些什麼事情
feeding 說明每條數據和padd.layer.data的對應關係
'''
trainer.train(reader=reader,
num_passes=100,
event_handler=event_handler,
feeding=feeding)
然後在main入口中調用該函數就可以開始訓練了
if __name__ == '__main__':
testCIFAR = TestCIFAR()
# 開始訓練
testCIFAR.start_trainer()
在訓練過程中會輸出這樣的日誌:
Pass 0, Batch 0, Cost 2.427227, {'classification_error_evaluator': 0.8984375}
...................................................................................................
Pass 0, Batch 100, Cost 2.115308, {'classification_error_evaluator': 0.78125}
...................................................................................................
Pass 0, Batch 200, Cost 2.081666, {'classification_error_evaluator': 0.8359375}
...................................................................................................
Pass 0, Batch 300, Cost 1.866330, {'classification_error_evaluator': 0.734375}
..........................................................................................
Test with Pass 0, {'classification_error_evaluator': 0.8687999844551086}
我們還可以使用PaddlePaddle提供的可視化日誌輸出接口paddle.v2.plot,以折線圖的方式顯示Train cost和Test cost,不過這個程序要在jupyter筆記本上運行,代碼已在train.ipynb中提供。折線圖如下,這張圖是訓練的56個pass之後的收斂情況。這個過程筆者爲了使訓練速度更快,筆者使用了2個GPU進行訓練,訓練56個pass共消耗6個小時,幾乎已經完全收斂了:
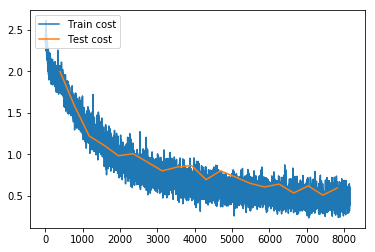
此時它測試輸出的日誌如下,可以看到預測錯誤率爲0.1477999985218048:
Test with Pass 56, {'classification_error_evaluator': 0.1477999985218048}
使用參數預測¶
編寫一個infer.py的Python程序文件編寫下面的代碼,用於測試數據。
在PaddlePaddle使用之前,都要初始化PaddlePaddle。
def __init__(self):
# 初始化paddpaddle,只是用CPU,把GPU關閉
paddle.init(use_gpu=False, trainer_count=2)
然後加載訓練是保存的模型,從保存的模型文件中讀取模型參數。
def get_parameters(self, parameters_path):
with open(parameters_path, 'r') as f:
parameters = paddle.parameters.Parameters.from_tar(f)
return parameters
該函數需要輸入3個參數:
- 第一個是需要預測的圖像,圖像傳入之後,會經過
load_image函數處理,大小會變成32*32大小,訓練是輸入數據的大小一樣. - 第二個就是訓練好的參數
- 第三個是通過神經模型生成的分類器
def to_prediction(self, image_path, parameters, out):
# 獲取圖片
def load_image(file):
im = Image.open(file)
im = im.resize((32, 32), Image.ANTIALIAS)
im = np.array(im).astype(np.float32)
# PIL打開圖片存儲順序爲H(高度),W(寬度),C(通道)。
# PaddlePaddle要求數據順序爲CHW,所以需要轉換順序。
im = im.transpose((2, 0, 1))
# CIFAR訓練圖片通道順序爲B(藍),G(綠),R(紅),
# 而PIL打開圖片默認通道順序爲RGB,因爲需要交換通道。
im = im[(2, 1, 0), :, :] # BGR
im = im.flatten()
im = im / 255.0
return im
# 獲得要預測的圖片
test_data = []
test_data.append((load_image(image_path),))
# 獲得預測結果
probs = paddle.infer(output_layer=out,
parameters=parameters,
input=test_data)
# 處理預測結果
lab = np.argsort(-probs)
# 返回概率最大的值和其對應的概率值
return lab[0][0], probs[0][(lab[0][0])]
在main入口中調用預測函數
if __name__ == '__main__':
testCIFAR = TestCIFAR()
# 開始預測
out = testCIFAR.get_out(3 * 32 * 32)
parameters = testCIFAR.get_parameters("../model/model.tar")
image_path = "../images/airplane1.png"
result,probability = testCIFAR.to_prediction(image_path=image_path, out=out, parameters=parameters)
print '預測結果爲:%d,可信度爲:%f' % (result,probability)
輸出的預測結果是:
預測結果爲:0,可信度爲:0.965155
使用其他神經模型¶
在上面的訓練中,只是使用到了VGG神經模型,而目前的ResNet可以說最火的,因爲該神經模型可以通過增加網絡的深度達到提高識別率,而不會像其他過去的神經模型那樣,當網絡繼續加深時,反而會損失精度.ResNet神經網絡resnet.py定義如下:
# coding=utf-8
import paddle.v2 as paddle
# ***********************定義ResNet卷積神經網絡模型***************************************
def resnet_cifar10(datadim,depth=32):
# 獲取輸入數據大小
ipt = paddle.layer.data(name="image",
type=paddle.data_type.dense_vector(datadim))
def conv_bn_layer(input, ch_out, filter_size, stride, padding, active_type=paddle.activation.Relu(),
ch_in=None):
tmp = paddle.layer.img_conv(input=input,
filter_size=filter_size,
num_channels=ch_in,
num_filters=ch_out,
stride=stride,
padding=padding,
act=paddle.activation.Linear(),
bias_attr=False)
return paddle.layer.batch_norm(input=tmp, act=active_type)
def shortcut(ipt, n_in, n_out, stride):
if n_in != n_out:
return conv_bn_layer(ipt, n_out, 1, stride, 0, paddle.activation.Linear())
else:
return ipt
def basicblock(ipt, ch_out, stride):
ch_in = ch_out * 2
tmp = conv_bn_layer(ipt, ch_out, 3, stride, 1)
tmp = conv_bn_layer(tmp, ch_out, 3, 1, 1, paddle.activation.Linear())
short = shortcut(ipt, ch_in, ch_out, stride)
return paddle.layer.addto(input=[tmp, short],
act=paddle.activation.Relu())
def layer_warp(block_func, ipt, features, count, stride):
tmp = block_func(ipt, features, stride)
for i in range(1, count):
tmp = block_func(tmp, features, 1)
return tmp
assert (depth - 2) % 6 == 0
n = (depth - 2) / 6
nStages = {16, 64, 128}
conv1 = conv_bn_layer(ipt, ch_in=3, ch_out=16, filter_size=3, stride=1, padding=1)
res1 = layer_warp(basicblock, conv1, 16, n, 1)
res2 = layer_warp(basicblock, res1, 32, n, 2)
res3 = layer_warp(basicblock, res2, 64, n, 2)
pool = paddle.layer.img_pool(
input=res3, pool_size=8, stride=1, pool_type=paddle.pooling.Avg())
# 通過神經網絡模型再使用Softmax獲得分類器(全連接)
out = paddle.layer.fc(input=pool,
size=10,
act=paddle.activation.Softmax())
return out
如果要使用上面的殘差神經網絡,只要把這行代碼:
out = vgg_bn_drop(datadim=datadim)
換成中殘差神經網絡中獲取分類器就可以了:
out = resnet_cifar10(datadim=datadim)
所有代碼¶
爲了讓讀者更直觀閱讀代碼,這張貼出所有的代碼。筆者這也代碼同步到GitHub上,GitHub的地址章文章的最後,讀者可以clone代碼到自己的電腦閱讀。
vgg.py,VGG16神經網絡的代碼:
# coding=utf-8
import paddle.v2 as paddle
# ***********************定義VGG卷積神經網絡模型***************************************
def vgg_bn_drop(datadim):
# 獲取輸入數據大小
img = paddle.layer.data(name="image",
type=paddle.data_type.dense_vector(datadim))
def conv_block(ipt, num_filter, groups, dropouts, num_channels=None):
return paddle.networks.img_conv_group(
input=ipt,
num_channels=num_channels,
pool_size=2,
pool_stride=2,
conv_num_filter=[num_filter] * groups,
conv_filter_size=3,
conv_act=paddle.activation.Relu(),
conv_with_batchnorm=True,
conv_batchnorm_drop_rate=dropouts,
pool_type=paddle.pooling.Max())
conv1 = conv_block(img, 64, 2, [0.3, 0], 3)
conv2 = conv_block(conv1, 128, 2, [0.4, 0])
conv3 = conv_block(conv2, 256, 3, [0.4, 0.4, 0])
conv4 = conv_block(conv3, 512, 3, [0.4, 0.4, 0])
conv5 = conv_block(conv4, 512, 3, [0.4, 0.4, 0])
drop = paddle.layer.dropout(input=conv5, dropout_rate=0.5)
fc1 = paddle.layer.fc(input=drop, size=512, act=paddle.activation.Linear())
bn = paddle.layer.batch_norm(input=fc1,
act=paddle.activation.Relu(),
layer_attr=paddle.attr.Extra(drop_rate=0.5))
fc2 = paddle.layer.fc(input=bn, size=512, act=paddle.activation.Linear())
# 通過神經網絡模型再使用Softmax獲得分類器(全連接)
out = paddle.layer.fc(input=fc2,
size=10,
act=paddle.activation.Softmax())
return out
resnet.py,殘差神經網絡的代碼:
# coding=utf-8
import paddle.v2 as paddle
# ***********************定義ResNet卷積神經網絡模型***************************************
def resnet_cifar10(datadim,depth=32):
# 獲取輸入數據大小
ipt = paddle.layer.data(name="image",
type=paddle.data_type.dense_vector(datadim))
def conv_bn_layer(input, ch_out, filter_size, stride, padding, active_type=paddle.activation.Relu(),
ch_in=None):
tmp = paddle.layer.img_conv(input=input,
filter_size=filter_size,
num_channels=ch_in,
num_filters=ch_out,
stride=stride,
padding=padding,
act=paddle.activation.Linear(),
bias_attr=False)
return paddle.layer.batch_norm(input=tmp, act=active_type)
def shortcut(ipt, n_in, n_out, stride):
if n_in != n_out:
return conv_bn_layer(ipt, n_out, 1, stride, 0, paddle.activation.Linear())
else:
return ipt
def basicblock(ipt, ch_out, stride):
ch_in = ch_out * 2
tmp = conv_bn_layer(ipt, ch_out, 3, stride, 1)
tmp = conv_bn_layer(tmp, ch_out, 3, 1, 1, paddle.activation.Linear())
short = shortcut(ipt, ch_in, ch_out, stride)
return paddle.layer.addto(input=[tmp, short],
act=paddle.activation.Relu())
def layer_warp(block_func, ipt, features, count, stride):
tmp = block_func(ipt, features, stride)
for i in range(1, count):
tmp = block_func(tmp, features, 1)
return tmp
assert (depth - 2) % 6 == 0
n = (depth - 2) / 6
nStages = {16, 64, 128}
conv1 = conv_bn_layer(ipt, ch_in=3, ch_out=16, filter_size=3, stride=1, padding=1)
res1 = layer_warp(basicblock, conv1, 16, n, 1)
res2 = layer_warp(basicblock, res1, 32, n, 2)
res3 = layer_warp(basicblock, res2, 64, n, 2)
pool = paddle.layer.img_pool(
input=res3, pool_size=8, stride=1, pool_type=paddle.pooling.Avg())
# 通過神經網絡模型再使用Softmax獲得分類器(全連接)
out = paddle.layer.fc(input=pool,
size=10,
act=paddle.activation.Softmax())
return out
train.py,訓練模型的代碼:
# coding:utf-8
import os
import sys
import paddle.v2 as paddle
from vgg import vgg_bn_drop
from resnet import resnet_cifar10
class TestCIFAR:
# ***********************初始化操作***************************************
def __init__(self):
# 初始化paddpaddle,只是用CPU,把GPU關閉
paddle.init(use_gpu=False, trainer_count=2)
# **********************獲取參數***************************************
def get_parameters(self, parameters_path=None, cost=None):
if not parameters_path:
# 使用cost創建parameters
if not cost:
print "請輸入cost參數"
else:
# 根據損失函數創建參數
parameters = paddle.parameters.create(cost)
return parameters
else:
# 使用之前訓練好的參數
try:
# 使用訓練好的參數
with open(parameters_path, 'r') as f:
parameters = paddle.parameters.Parameters.from_tar(f)
return parameters
except Exception as e:
raise NameError("你的參數文件錯誤,具體問題是:%s" % e)
# ***********************獲取訓練器***************************************
def get_trainer(self):
# 數據大小
datadim = 3 * 32 * 32
# 獲得圖片對於的信息標籤
lbl = paddle.layer.data(name="label",
type=paddle.data_type.integer_value(10))
# 獲取全連接層,也就是分類器
#
out = vgg_bn_drop(datadim=datadim)
# out = resnet_cifar10(datadim=datadim)
# 獲得損失函數
cost = paddle.layer.classification_cost(input=out, label=lbl)
# 使用之前保存好的參數文件獲得參數
# parameters = self.get_parameters(parameters_path="../model/model.tar")
# 使用損失函數生成參數
parameters = self.get_parameters(cost=cost)
''' 定義優化方法
learning_rate 迭代的速度
momentum 跟前面動量優化的比例
regularzation 正則化,防止過擬合
'''
momentum_optimizer = paddle.optimizer.Momentum(
momentum=0.9,
regularization=paddle.optimizer.L2Regularization(rate=0.0002 * 128),
learning_rate=0.1 / 128.0,
learning_rate_decay_a=0.1,
learning_rate_decay_b=50000 * 100,
learning_rate_schedule="discexp")
'''
創建訓練器
cost 分類器
parameters 訓練參數,可以通過創建,也可以使用之前訓練好的參數
update_equation 優化方法
'''
trainer = paddle.trainer.SGD(cost=cost,
parameters=parameters,
update_equation=momentum_optimizer)
return trainer
# ***********************開始訓練***************************************
def start_trainer(self):
# 獲得數據
reader = paddle.batch(reader=paddle.reader.shuffle(reader=paddle.dataset.cifar.train10(),
buf_size=50000),
batch_size=128)
# 指定每條數據和padd.layer.data的對應關係
feeding = {"image": 0, "label": 1}
# 定義訓練事件,輸出日誌
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print "\nPass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics)
else:
sys.stdout.write('.')
sys.stdout.flush()
# 每一輪訓練完成之後
if isinstance(event, paddle.event.EndPass):
# 保存訓練好的參數
model_path = '../model'
if not os.path.exists(model_path):
os.makedirs(model_path)
with open(model_path + '/model.tar', 'w') as f:
trainer.save_parameter_to_tar(f)
# 測試準確率
result = trainer.test(reader=paddle.batch(reader=paddle.dataset.cifar.test10(),
batch_size=128),
feeding=feeding)
print "\nTest with Pass %d, %s" % (event.pass_id, result.metrics)
# 獲取訓練器
trainer = self.get_trainer()
'''
開始訓練
reader 訓練數據
num_passes 訓練的輪數
event_handler 訓練的事件,比如在訓練的時候要做一些什麼事情
feeding 說明每條數據和padd.layer.data的對應關係
'''
trainer.train(reader=reader,
num_passes=100,
event_handler=event_handler,
feeding=feeding)
if __name__ == '__main__':
testCIFAR = TestCIFAR()
# 開始訓練
testCIFAR.start_trainer()
train.ipynb,在jupyter中使用的代碼,會輸出訓練時cost的折線圖:
# coding:utf-8
import os
import sys
import paddle.v2 as paddle
from paddle.v2.plot import Ploter
from vgg import vgg_bn_drop
step = 0
class TestCIFAR:
# ***********************初始化操作***************************************
def __init__(self):
# 初始化paddpaddle,只是用CPU,把GPU關閉
paddle.init(use_gpu=False, trainer_count=2)
# **********************獲取參數***************************************
def get_parameters(self, parameters_path=None, cost=None):
if not parameters_path:
# 使用cost創建parameters
if not cost:
print "請輸入cost參數"
else:
# 根據損失函數創建參數
parameters = paddle.parameters.create(cost)
return parameters
else:
# 使用之前訓練好的參數
try:
# 使用訓練好的參數
with open(parameters_path, 'r') as f:
parameters = paddle.parameters.Parameters.from_tar(f)
return parameters
except Exception as e:
raise NameError("你的參數文件錯誤,具體問題是:%s" % e)
# ***********************獲取訓練器***************************************
def get_trainer(self):
# 數據大小
datadim = 3 * 32 * 32
# 獲得圖片對於的信息標籤
lbl = paddle.layer.data(name="label",
type=paddle.data_type.integer_value(10))
# 獲取全連接層,也就是分類器
out = vgg_bn_drop(datadim=datadim)
# 獲得損失函數
cost = paddle.layer.classification_cost(input=out, label=lbl)
# 使用之前保存好的參數文件獲得參數
# parameters = self.get_parameters(parameters_path="../model/model.tar")
# 使用損失函數生成參數
parameters = self.get_parameters(cost=cost)
'''
定義優化方法
learning_rate 迭代的速度
momentum 跟前面動量優化的比例
regularzation 正則化,防止過擬合
'''
momentum_optimizer = paddle.optimizer.Momentum(
momentum=0.9,
regularization=paddle.optimizer.L2Regularization(rate=0.0002 * 128),
learning_rate=0.1 / 128.0,
learning_rate_decay_a=0.1,
learning_rate_decay_b=50000 * 100,
learning_rate_schedule="discexp")
'''
創建訓練器
cost 分類器
parameters 訓練參數,可以通過創建,也可以使用之前訓練好的參數
update_equation 優化方法
'''
trainer = paddle.trainer.SGD(cost=cost,
parameters=parameters,
update_equation=momentum_optimizer)
return trainer
# ***********************開始訓練***************************************
def start_trainer(self):
# 獲得數據
reader = paddle.batch(reader=paddle.reader.shuffle(reader=paddle.dataset.cifar.train10(),
buf_size=50000),
batch_size=128)
# 指定每條數據和padd.layer.data的對應關係
feeding = {"image": 0, "label": 1}
train_title = "Train cost"
test_title = "Test cost"
cost_ploter = Ploter(train_title, test_title)
# 定義訓練事件,畫出折線圖,該事件的圖可以在notebook上顯示,命令行不會正常輸出
def event_handler_plot(event):
global step
if isinstance(event, paddle.event.EndIteration):
if step % 1 == 0:
cost_ploter.append(train_title, step, event.cost)
cost_ploter.plot()
step += 1
if isinstance(event, paddle.event.EndPass):
# 保存訓練好的參數
model_path = '../model'
if not os.path.exists(model_path):
os.makedirs(model_path)
with open(model_path + '/model_%d.tar' % event.pass_id, 'w') as f:
trainer.save_parameter_to_tar(f)
result = trainer.test(
reader=paddle.batch(
paddle.dataset.cifar.test10(), batch_size=128),
feeding=feeding)
cost_ploter.append(test_title, step, result.cost)
# 獲取訓練器
trainer = self.get_trainer()
'''
開始訓練
reader 訓練數據
num_passes 訓練的輪數
event_handler 訓練的事件,比如在訓練的時候要做一些什麼事情
feeding 說明每條數據和padd.layer.data的對應關係
'''
trainer.train(reader=reader,
num_passes=100,
event_handler=event_handler_plot,
feeding=feeding)
if __name__ == '__main__':
testCIFAR = TestCIFAR()
# 開始訓練
testCIFAR.start_trainer()
infer.py,使用訓練好的模型預測數據的代碼:
# coding:utf-8
from paddle.v2.plot import Ploter
import sys
import paddle.v2 as paddle
from PIL import Image
import numpy as np
import os
from vgg import vgg_bn_drop
class TestCIFAR:
# ***********************初始化操作***************************************
def __init__(self):
# 初始化paddpaddle,只是用CPU,把GPU關閉
paddle.init(use_gpu=False, trainer_count=2)
# **********************獲取參數***************************************
def get_parameters(self, parameters_path):
with open(parameters_path, 'r') as f:
parameters = paddle.parameters.Parameters.from_tar(f)
return parameters
# ***********************使用訓練好的參數進行預測***************************************
def to_prediction(self, image_path, parameters, out):
# 獲取圖片
def load_image(file):
im = Image.open(file)
im = im.resize((32, 32), Image.ANTIALIAS)
im = np.array(im).astype(np.float32)
# PIL打開圖片存儲順序爲H(高度),W(寬度),C(通道)。
# PaddlePaddle要求數據順序爲CHW,所以需要轉換順序。
im = im.transpose((2, 0, 1))
# CIFAR訓練圖片通道順序爲B(藍),G(綠),R(紅),
# 而PIL打開圖片默認通道順序爲RGB,因爲需要交換通道。
im = im[(2, 1, 0), :, :] # BGR
im = im.flatten()
im = im / 255.0
return im
# 獲得要預測的圖片
test_data = []
test_data.append((load_image(image_path),))
# 獲得預測結果
probs = paddle.infer(output_layer=out,
parameters=parameters,
input=test_data)
# 處理預測結果
lab = np.argsort(-probs)
# 返回概率最大的值和其對應的概率值
return lab[0][0], probs[0][(lab[0][0])]
if __name__ == '__main__':
testCIFAR = TestCIFAR()
# 開始預測
out = vgg_bn_drop(3 * 32 * 32)
parameters = testCIFAR.get_parameters("../model/model.tar")
image_path = "../images/airplane1.png"
result,probability = testCIFAR.to_prediction(image_path=image_path, out=out, parameters=parameters)
print '預測結果爲:%d,可信度爲:%f' % (result,probability)
上一章:《我的PaddlePaddle學習之路》筆記二——MNIST手寫數字識別¶
下一章:《我的PaddlePaddle學習之路》筆記四——自定義圖像數據集的識別¶
項目代碼¶
GitHub地址:https://github.com/yeyupiaoling/LearnPaddle
參考資料¶
- http://paddlepaddle.org/
- https://www.cs.toronto.edu/~kriz/cifar.html
- https://arxiv.org/abs/1405.3531