# PPASR語音識別(入門級)
本項目將分三個階段分支,分別是入門級、進階級和應用級分支,當前爲入門級,隨着級別的提升,識別準確率也隨之提升,也更適合實際項目使用,敬請關注!
PPASR基於PaddlePaddle2實現的端到端自動語音識別,本項目最大的特點簡單,在保證準確率不低的情況下,項目儘量做得淺顯易懂,能夠讓每個想入門語音識別的開發者都能夠輕鬆上手。PPASR只使用卷積神經網絡,無其他特殊網絡結構,模型簡單易懂,且是端到端的,不需要音頻對齊,因爲本項目使用了CTC Loss作爲損失函數。在傳統的語音識別的模型中,我們對語音模型進行訓練之前,往往都要將文本與語音進行嚴格的對齊操作。在傳統的語音識別的模型中,我們對語音模型進行訓練之前,往往都要將文本與語音進行嚴格的對齊操作,這種對齊非常浪費時間,而且對齊之後,模型預測出的label只是局部分類的結果,而無法給出整個序列的輸出結果,往往要對預測出的label做一些後處理纔可以得到我們最終想要的結果。基於這種情況,就出現了CTC(Connectionist temporal classification),使用CTC Loss就不需要進行音頻對齊,直接輸入是一句完整的語音數據,輸出的是整個序列結果,這種情況OCR也是同樣的情況。
在數據預處理方便,本項目主要是將音頻執行梅爾頻率倒譜系數(MFCCs)處理,然後在使用出來的數據進行訓練,在讀取音頻時,使用librosa.load(wav_path, sr=16000)函數讀取音頻文件,再使用librosa.feature.mfcc()執行數據處理。MFCC全稱梅爾頻率倒譜系數。梅爾頻率是基於人耳聽覺特性提出來的, 它與Hz頻率成非線性對應關係。梅爾頻率倒譜系數(MFCC)則是利用它們之間的這種關係,計算得到的Hz頻譜特徵,主要計算方式分別是預加重,分幀,加窗,快速傅里葉變換(FFT),梅爾濾波器組,離散餘弦變換(DCT),最後提取語音數據特徵和降低運算維度。本項目使用的全部音頻的採樣率都是16000Hz,如果其他採樣率的音頻都需要轉爲16000Hz,create_manifest.py程序也提供了把音頻轉爲16000Hz。
本項目Github地址:https://github.com/yeyupiaoling/PPASR/tree/入門級
在線運行¶
項目地址:https://aistudio.baidu.com/aistudio/projectdetail/1597936
安裝環境¶
- 本項目可以在Windows或者Ubuntu都可以運行,安裝環境很簡單,只需要執行以下一條命令即可。
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
數據準備¶
- 在
data目錄下是公開數據集的下載和製作訓練數據列表和字典的,本項目提供了下載公開的中文普通話語音數據集,分別是Aishell,Free ST-Chinese-Mandarin-Corpus,THCHS-30 這三個數據集,總大小超過28G。下載這三個數據只需要執行一下代碼即可,當然如果想快速訓練,也可以只下載其中一個。
```shell script
python3 data/aishell.py
python3 data/free_st_chinese_mandarin_corpus.py
python3 data/thchs_30.py
- 如果開發者有自己的數據集,可以使用自己的數據集進行訓練,當然也可以跟上面下載的數據集一起訓練。自定義的語音數據需要符合一下格式:
1. 語音文件需要放在`dataset/audio/`目錄下,例如我們有個`wav`的文件夾,裏面都是語音文件,我們就把這個文件存放在`dataset/audio/`。
2. 然後把數據列表文件存在`dataset/annotation/`目錄下,程序會遍歷這個文件下的所有數據列表文件。例如這個文件下存放一個`my_audio.txt`,它的內容格式如下,路徑和Label間的分隔符爲'\t',即一個Tab。每一行數據包含該語音文件的相對路徑和該語音文件對應的中文文本,要注意的是該中文文本只能包含純中文,不能包含標點符號、阿拉伯數字以及英文字母。
```shell script
dataset/audio/wav/0175/H0175A0171.wav 我需要把空調溫度調到二十度
dataset/audio/wav/0175/H0175A0377.wav 出彩中國人
dataset/audio/wav/0175/H0175A0470.wav 據克而瑞研究中心監測
dataset/audio/wav/0175/H0175A0180.wav 把溫度加大到十八
- 執行下面的命令,創建數據列表,以及建立詞表,也就是數據字典,把所有出現的字符都存放子在
zh_vocab.json文件中,生成的文件都存放在dataset/目錄下。最最最重要的是還計算了數據集的均值和標準值,計算得到的均值和標準值需要更新在訓練參數data_mean和data_std中,之後的評估和預測同樣需要用到。有幾個參數需要注意,參數is_change_frame_rate是指定在生成數據集的時候,是否要把音頻的採樣率轉換爲16000Hz,最好是使用默認值。參數min_duration和max_duration限制音頻的長度,特別是有些音頻太長,會導致顯存不足,訓練直接崩掉。
```shell script
python3 create_manifest.py
我們來說說這些文件和數據的具體作用,創建數據列表是爲了在訓練是讀取數據,讀取數據程序通過讀取圖像列表的每一行都能得到音頻的文件路徑、音頻長度以及這句話的內容。通過路徑讀取音頻文件並進行預處理,音頻長度用於統計數據總長度,文字內容就是輸入數據的標籤,在訓練是還需要數據字典把這些文字內容轉置整型的數字,比如`是`這個字在數據字典中排在第5,那麼它的標籤就是4,標籤從0開始。至於最後生成的均值和標準值,因爲我們的數據在訓練之前還需要歸一化,因爲每個數據的分佈不一樣,不同圖像,最大最小值都是確定的,所以我們要統計一批數據來計算均值和標準值,之後的數據的歸一化都使用這個均值和標準值。
輸出結果如下:
```shell
----------- Configuration Arguments -----------
annotation_path: dataset/annotation/
count_threshold: 0
is_change_frame_rate: True
manifest_path: dataset/manifest.train
manifest_prefix: dataset/
max_duration: 20
min_duration: 0
vocab_path: dataset/zh_vocab.json
------------------------------------------------
開始生成數據列表...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 141600/141600 [00:17<00:00, 8321.22it/s]
完成生成數據列表,數據集總長度爲178.97小時!
開始生成數據字典...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 140184/140184 [00:01<00:00, 89476.12it/s]
數據字典生成完成!
開始抽取1%的數據計算均值和標準值...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 140184/140184 [01:33<00:00, 1507.15it/s]
【特別重要】:均值:-3.146301, 標準值:52.998405, 請根據這兩個值修改訓練參數!
可以用使用python create_manifest.py --help命令查看各個參數的說明和默認值。
usage: create_manifest.py [-h] [----annotation_path ANNOTATION_PATH]
[--manifest_prefix MANIFEST_PREFIX]
[--is_change_frame_rate IS_CHANGE_FRAME_RATE]
[--min_duration MIN_DURATION]
[--max_duration MAX_DURATION]
[--count_threshold COUNT_THRESHOLD]
[--vocab_path VOCAB_PATH]
[--manifest_path MANIFEST_PATH]
optional arguments:
-h, --help show this help message and exit
----annotation_path ANNOTATION_PATH
標註文件的路徑 默認: dataset/annotation/.
--manifest_prefix MANIFEST_PREFIX
訓練數據清單,包括音頻路徑和標註信息 默認: dataset/.
--is_change_frame_rate IS_CHANGE_FRAME_RATE
是否統一改變音頻爲16000Hz,這會消耗大量的時間 默認: True.
--min_duration MIN_DURATION
過濾最短的音頻長度 默認: 0.
--max_duration MAX_DURATION
過濾最長的音頻長度,當爲-1的時候不限制長度 默認: 20.
--count_threshold COUNT_THRESHOLD
字符計數的截斷閾值,0爲不做限制 默認: 0.
--vocab_path VOCAB_PATH
生成的數據字典文件 默認: dataset/zh_vocab.json.
--manifest_path MANIFEST_PATH
數據列表路徑 默認: dataset/manifest.train.
訓練模型¶
- 執行訓練腳本,開始訓練語音識別模型, 每訓練一輪保存一次模型,模型保存在
models/目錄下,測試使用的是貪心解碼路徑解碼方法。本項目支持多卡訓練,在沒有指定CUDA_VISIBLE_DEVICES時,會使用全部的GPU進行執行訓練,也可以指定某幾個GPU訓練,如CUDA_VISIBLE_DEVICES=0,1指定使用第1張和第2張顯卡訓練。除了參數data_mean和data_std需要根據計算的結果修改,其他的參數一般不需要改動,參數num_workers可以更加CPU的核數修改,這個參數是指定使用多少個線程讀取數據。參數pretrained_model是指定預訓練模型所在的文件夾,如果使用訓練模型,必須使用跟預訓練配套的數據字典,原因是,其一,數據字典的大小指定了模型的輸出大小,如果使用了其他更大的數據字典,預訓練模型就無法完全加載。其二,數值字典定義了文字的ID,不同的數據字典文字的ID可能不一樣,這樣預訓練模型的作用就不是那麼大了。
```shell script
CUDA_VISIBLE_DEVICES=0,1 python3 train.py
訓練輸出結果如下:
```shell
----------- Configuration Arguments -----------
batch_size: 32
data_mean: -3.146301
data_std: 52.998405
dataset_vocab: dataset/zh_vocab.json
learning_rate: 0.001
num_epoch: 200
num_workers: 8
pretrained_model: None
save_model: models/
test_manifest: dataset/manifest.test
train_manifest: dataset/manifest.train
------------------------------------------------
I0303 16:55:39.645823 16572 nccl_context.cc:189] init nccl context nranks: 2 local rank: 0 gpu id: 0 ring id: 0
I0303 16:55:39.645821 16573 nccl_context.cc:189] init nccl context nranks: 2 local rank: 1 gpu id: 1 ring id: 0
W0303 16:55:39.905000 16572 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.0, Runtime API Version: 10.2
W0303 16:55:39.905090 16573 device_context.cc:362] Please NOTE: device: 1, GPU Compute Capability: 7.5, Driver API Version: 11.0, Runtime API Version: 10.2
W0303 16:55:39.907197 16572 device_context.cc:372] device: 0, cuDNN Version: 7.6.
W0303 16:55:39.907199 16573 device_context.cc:372] device: 1, cuDNN Version: 7.6.
input_size的第三個參數是變長的,這裏爲了能查看輸出的大小變化,指定了一個值!
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv1D-1 [[32, 128, 500]] [32, 500, 324] 3,073,000
Sigmoid-1 [[32, 250, 324]] [32, 250, 324] 0
GLU-1 [[32, 500, 324]] [32, 250, 324] 0
Dropout-1 [[32, 250, 324]] [32, 250, 324] 0
ConvBlock-1 [[32, 128, 500]] [32, 250, 324] 0
Conv1D-2 [[32, 250, 288]] [32, 500, 282] 876,000
Sigmoid-2 [[32, 250, 282]] [32, 250, 282] 0
GLU-2 [[32, 500, 282]] [32, 250, 282] 0
Dropout-2 [[32, 250, 282]] [32, 250, 282] 0
ConvBlock-2 [[32, 250, 288]] [32, 250, 282] 0
Conv1D-3 [[32, 250, 282]] [32, 2000, 251] 16,004,000
Sigmoid-3 [[32, 1000, 251]] [32, 1000, 251] 0
GLU-3 [[32, 2000, 251]] [32, 1000, 251] 0
Dropout-3 [[32, 1000, 251]] [32, 1000, 251] 0
ConvBlock-3 [[32, 250, 282]] [32, 1000, 251] 0
Conv1D-4 [[32, 1000, 251]] [32, 2000, 251] 2,004,000
Sigmoid-4 [[32, 1000, 251]] [32, 1000, 251] 0
GLU-4 [[32, 2000, 251]] [32, 1000, 251] 0
Dropout-4 [[32, 1000, 251]] [32, 1000, 251] 0
ConvBlock-4 [[32, 1000, 251]] [32, 1000, 251] 0
Conv1D-5 [[32, 1000, 251]] [32, 4323, 251] 4,331,646
===========================================================================
Total params: 26,288,646
Trainable params: 26,288,646
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 7.81
Forward/backward pass size (MB): 1222.19
Params size (MB): 100.28
Estimated Total Size (MB): 1330.28
---------------------------------------------------------------------------
Epoch 0: ExponentialDecay set learning rate to 0.001.
Epoch 0: ExponentialDecay set learning rate to 0.001.
[2021-03-03 16:56:01.754491] Train epoch 0, batch 0, loss: 269.343811
[2021-03-03 16:58:08.436214] Train epoch 0, batch 100, loss: 7.195621
[2021-03-03 16:59:54.781490] Train epoch 0, batch 200, loss: 6.914866
[2021-03-03 17:01:34.841955] Train epoch 0, batch 300, loss: 6.824973
[2021-03-03 17:03:09.492905] Train epoch 0, batch 400, loss: 6.905243
可以用使用python train.py --help命令查看各個參數的說明和默認值。
usage: train.py [-h] [--batch_size BATCH_SIZE] [--num_workers NUM_WORKERS]
[--num_epoch NUM_EPOCH] [--learning_rate LEARNING_RATE]
[--data_mean DATA_MEAN] [--data_std DATA_STD]
[--train_manifest TRAIN_MANIFEST]
[--test_manifest TEST_MANIFEST]
[--dataset_vocab DATASET_VOCAB] [--save_model SAVE_MODEL]
[--pretrained_model PRETRAINED_MODEL]
optional arguments:
-h, --help show this help message and exit
--batch_size BATCH_SIZE
訓練的批量大小 默認: 32.
--num_workers NUM_WORKERS
讀取數據的線程數量 默認: 8.
--num_epoch NUM_EPOCH
訓練的輪數 默認: 200.
--learning_rate LEARNING_RATE
初始學習率的大小 默認: 0.001.
--data_mean DATA_MEAN
數據集的均值 默認: -3.146301.
--data_std DATA_STD 數據集的標準值 默認: 52.998405.
--train_manifest TRAIN_MANIFEST
訓練數據的數據列表路徑 默認: dataset/manifest.train.
--test_manifest TEST_MANIFEST
測試數據的數據列表路徑 默認: dataset/manifest.test.
--dataset_vocab DATASET_VOCAB
數據字典的路徑 默認: dataset/zh_vocab.json.
--save_model SAVE_MODEL
模型保存的路徑 默認: models/.
--pretrained_model PRETRAINED_MODEL
預訓練模型的路徑,當爲None則不使用預訓練模型 默認: None.
- 在訓練過程中,程序會使用VisualDL記錄訓練結果,可以通過以下的命令啓動VisualDL。
visualdl --logdir=log --host 0.0.0.0
- 然後再瀏覽器上訪問
http://localhost:8040可以查看結果顯示,如下。
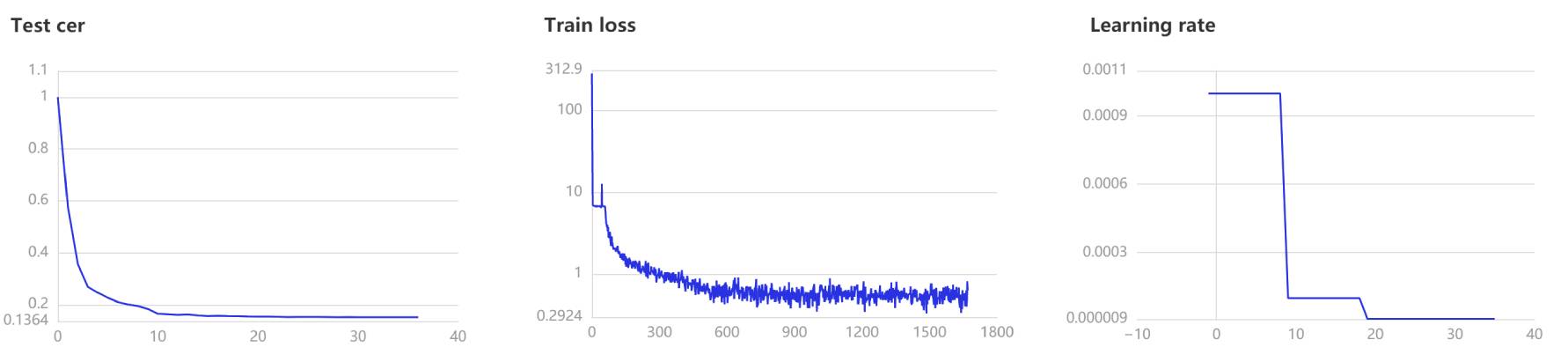
評估和預測¶
在評估和預測中,對結果解碼的貪心策略解碼方法,貪心策略是在每一步選擇概率最大的輸出值,這樣就可以得到最終解碼的輸出序列。然而,CTC網絡的輸出序列只對應了搜索空間的一條路徑,一個最終標籤可對應搜索空間的N條路徑,所以概率最大的路徑並不等於最終標籤的概率最大,即不是最優解。但貪心策略是最簡單易懂且快速地一種方法。在語音識別上使用最多的解碼方法還有定向搜索策略,這種策略準確率更高,同時也相對複雜,解碼速度也相對慢很多。
- 我們可以使用這個腳本對模型進行評估,通過字符錯誤率來評價模型的性能。目前只支持貪心策略解碼方法。在評估中音頻預處理的
mean和std需要跟訓練時一樣,但這裏不需要開發者手動指定,因爲這兩個參數在訓練的時候就已經保持在模型中,這時只需從模型中讀取這兩個參數的值就可以。參數model_path指定模型所在的文件夾的路徑。
```shell script
python3 eval.py –model_path=models/step_final/
可以用使用`python eval.py --help`命令查看各個參數的說明和默認值。
```shell
usage: eval.py [-h] [--batch_size BATCH_SIZE] [--num_workers NUM_WORKERS]
[--test_manifest TEST_MANIFEST] [--dataset_vocab DATASET_VOCAB]
[--model_path MODEL_PATH]
optional arguments:
-h, --help show this help message and exit
--batch_size BATCH_SIZE
訓練的批量大小 默認: 32.
--num_workers NUM_WORKERS
讀取數據的線程數量 默認: 8.
--test_manifest TEST_MANIFEST
測試數據的數據列表路徑 默認: dataset/manifest.test.
--dataset_vocab DATASET_VOCAB
數據字典的路徑 默認: dataset/zh_vocab.json.
--model_path MODEL_PATH
模型的路徑 默認: models/step_final/.
- 我們可以使用這個腳本使用模型進行預測,通過傳遞音頻文件的路徑進行識別。在預測中音頻預處理的
mean和std需要跟訓練時一樣,但這裏不需要開發者手動指定,因爲這兩個參數在訓練的時候就已經保持在模型中,這時只需從模型中讀取這兩個參數的值就可以。參數model_path指定模型所在的文件夾的路徑,參數wav_path指定需要預測音頻文件的路徑。
```shell script
python3 infer.py –audio_path=./dataset/test.wav
可以用使用`python infer.py --help`命令查看各個參數的說明和默認值。
```shell
usage: infer.py [-h] [--audio_path AUDIO_PATH] [--dataset_vocab DATASET_VOCAB]
[--model_path MODEL_PATH]
optional arguments:
-h, --help show this help message and exit
--audio_path AUDIO_PATH
用於識別的音頻路徑 默認: dataset/test.wav.
--dataset_vocab DATASET_VOCAB
數據字典的路徑 默認: dataset/zh_vocab.json.
--model_path MODEL_PATH
模型的路徑 默認: models/step_final/.
模型下載¶
| 數據集 | 字錯率 | 下載地址 |
|---|---|---|
| AISHELL | 0.151082 | 點擊下載 |
| free_st_chinese_mandarin_corpus | 0.214240 | 點擊下載 |
| thchs30 | 0.081742 | 點擊下載 |