# PPASR語音識別(進階級)
本項目將分三個階段分支,分別是入門級 、進階級 和最終級 分支,當前爲進階級,隨着級別的提升,識別準確率也隨之提升,也更適合實際項目使用,敬請關注!
PPASR(進階級)基於PaddlePaddle2實現的端到端自動語音識別,相比入門級,進階級從三個方面來提高模型的準確率,首先最主要的是更換了模型,這次採用了DeepSpeech2模型,DeepSpeech2是2015年百度發佈的語音識別模型,其論文爲《Baidu’s Deep Speech 2 paper》 。然後也修改了音頻的預處理,這次使用了在語音識別上更好的預處理,通過用FFT energy計算線性譜圖。最後修改的是解碼器,相比之前使用的貪心策略解碼器,這次增加了集束搜索解碼器,這個解碼器可以加載語言模型,對解碼的結果調整,使得預測輸出語句更合理,從而提高準確率。
使用環境:
- Anaconda 3
- Python 3.7
- PaddlePaddle 2.1.3
- Windows 10 or Ubuntu 18.04
安裝環境¶
- 首先安裝的是PaddlePaddle 2.1.3的GPU版本,如果已經安裝過了,請跳過。
conda install paddlepaddle-gpu==2.1.3 cudatoolkit=10.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
- 本項目的訓練在Windows或者Ubuntu都可以運行,安裝環境很簡單,只需要執行以下一條命令即可。
python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
如果出現LLVM版本錯誤,則執行下面的命令,然後重新執行上面的安裝命令,否則不需要執行。
cd ~
wget https://releases.llvm.org/9.0.0/llvm-9.0.0.src.tar.xz
wget http://releases.llvm.org/9.0.0/cfe-9.0.0.src.tar.xz
wget http://releases.llvm.org/9.0.0/clang-tools-extra-9.0.0.src.tar.xz
tar xvf llvm-9.0.0.src.tar.xz
tar xvf cfe-9.0.0.src.tar.xz
tar xvf clang-tools-extra-9.0.0.src.tar.xz
mv llvm-9.0.0.src llvm-src
mv cfe-9.0.0.src llvm-src/tools/clang
mv clang-tools-extra-9.0.0.src llvm-src/tools/clang/tools/extra
sudo mkdir -p /usr/local/llvm
sudo mkdir -p llvm-src/build
cd llvm-src/build
sudo cmake -G "Unix Makefiles" -DLLVM_TARGETS_TO_BUILD=X86 -DCMAKE_BUILD_TYPE="Release" -DCMAKE_INSTALL_PREFIX="/usr/local/llvm" ..
sudo make -j8
sudo make install
export LLVM_CONFIG=/usr/local/llvm/bin/llvm-config
- 在評估和預測都可以選擇不同的解碼器,如果是選擇集束搜索解碼器,就需要執行下面命令來安裝環境,該解碼器只支持Linux編譯安裝。如果使用的是Windows,那麼就只能選擇貪心策略解碼器,無需再執行下面的命令編譯安裝集束搜索解碼器。
cd decoders
pip3 install swig_decoders-1.2-cp37-cp37m-linux_x86_64.whl
注意: 如果不能正常安裝,就需要自行編譯ctc_decoders庫,該編譯只支持Ubuntu,其他Linux版本沒測試過,執行下面命令完成編譯。
cd decoders
sh setup.sh
- 下載語言模型,集束搜索解碼需要使用到語言模型,下載語言模型並放在lm目錄下。
```shell script
cd PaddlePaddle-DeepSpeech/
mkdir lm
cd lm
wget https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm
# 數據準備
1. 在`download_data`目錄下是公開數據集的下載和製作訓練數據列表和字典的,本項目提供了下載公開的中文普通話語音數據集,分別是Aishell,Free ST-Chinese-Mandarin-Corpus,THCHS-30 這三個數據集,總大小超過28G。下載這三個數據只需要執行一下代碼即可,當然如果想快速訓練,也可以只下載其中一個。
```shell script
python3 download_data/aishell.py
python3 download_data/free_st_chinese_mandarin_corpus.py
python3 download_data/thchs_30.py
- 如果開發者有自己的數據集,可以使用自己的數據集進行訓練,當然也可以跟上面下載的數據集一起訓練。自定義的語音數據需要符合一下格式:
- 語音文件需要放在
dataset/audio/目錄下,例如我們有個wav的文件夾,裏面都是語音文件,我們就把這個文件存放在dataset/audio/。 - 然後把數據列表文件存在
dataset/annotation/目錄下,程序會遍歷這個文件下的所有數據列表文件。例如這個文件下存放一個my_audio.txt,它的內容格式如下。每一行數據包含該語音文件的相對路徑和該語音文件對應的中文文本,要注意的是該中文文本只能包含純中文,不能包含標點符號、阿拉伯數字以及英文字母。
```shell script
dataset/audio/wav/0175/H0175A0171.wav 我需要把空調溫度調到二十度
dataset/audio/wav/0175/H0175A0377.wav 出彩中國人
dataset/audio/wav/0175/H0175A0470.wav 據克而瑞研究中心監測
dataset/audio/wav/0175/H0175A0180.wav 把溫度加大到十八
- 語音文件需要放在
- 執行下面的命令,創建數據列表,以及建立詞表,也就是數據字典,把所有出現的字符都存放子在`vocabulary.txt`文件中,生成的文件都存放在`dataset/`目錄下。在圖像預處理的時候需要用到均值和標準值,之後的評估和預測同樣需要用到,這些都會計算並保存在文件中。
我們來說說這些文件和數據的具體作用,創建數據列表是爲了在訓練是讀取數據,讀取數據程序通過讀取圖像列表的每一行都能得到音頻的文件路徑、音頻長度以及這句話的內容。通過路徑讀取音頻文件並進行預處理,音頻長度用於統計數據總長度,文字內容就是輸入數據的標籤,在訓練是還需要數據字典把這些文字內容轉置整型的數字,比如`是`這個字在數據字典中排在第5,那麼它的標籤就是4,標籤從0開始。至於最後生成的均值和標準值,因爲我們的數據在訓練之前還需要歸一化,因爲每個數據的分佈不一樣,不同圖像,最大最小值都是確定的,隨機採取一部分的書籍計算均值和標準值,然後把均值和標準值保存在`npy`文件中。
```shell script
python3 create_data.py
輸出結果如下:
----------- Configuration Arguments -----------
annotation_path: dataset/annotation/
count_threshold: 0
is_change_frame_rate: True
manifest_path: dataset/manifest.train
manifest_prefix: dataset/
num_samples: -1
num_workers: 8
output_path: ./dataset/mean_std.npz
vocab_path: dataset/vocabulary.txt
------------------------------------------------
開始生成數據列表...
100%|███████████████████████| 13388/13388 [00:09<00:00, 1454.08it/s]
完成生成數據列表,數據集總長度爲34.16小時!
======================================================================
開始生成噪聲數據列表...
噪聲音頻文件爲空,已跳過!
======================================================================
開始生成數據字典...
100%|██████████████████████████| 13254/13254 [00:00<00:00, 35948.64it/s]
100%|██████████████████████████| 134/134 [00:00<00:00, 35372.69it/s]
數據字典生成完成!
======================================================================
開始抽取-1條數據計算均值和標準值...
100%|█████████████████████████████| 208/208 [00:20<00:00, 9.97it/s]
計算的均值和標準值已保存在 ./dataset/mean_std.npz!
可以用使用python create_data.py --help命令查看各個參數的說明和默認值。
訓練模型¶
- 執行訓練腳本,開始訓練語音識別模型, 每訓練一輪保存一次模型,模型保存在
models/目錄下,測試使用的是貪心解碼路徑解碼方法。本項目支持多卡訓練,通過使用--gpus參數指定,如--gpus= '0,1'指定使用第1張和第2張顯卡訓練。其他的參數一般不需要改動,參數--num_workers可以數據讀取的線程數,這個參數是指定使用多少個線程讀取數據。參數--pretrained_model是指定預訓練模型所在的文件夾,使用預訓練模型,在加載的時候會自動跳過維度不一致的層。如果使用--resume恢復訓練模型,恢復模型的路徑結構應該要跟保存的時候一樣,這樣才能讀取到該模型是epoch數,並且必須使用跟預訓練配套的數據字典,原因是,其一,數據字典的大小指定了模型的輸出大小,如果使用了其他更大的數據字典,恢復訓練模型就無法完全加載。其二,數值字典定義了文字的ID,不同的數據字典文字的ID可能不一樣,這樣恢復練模型的作用就不是那麼大了。
```shell script
單卡訓練¶
python3 train.py
多卡訓練¶
python -m paddle.distributed.launch –gpus ‘0,1’ train.py
訓練輸出結果如下:
```shell
----------- Configuration Arguments -----------
augment_conf_path: conf/augmentation.json
batch_size: 16
dataset_vocab: dataset/vocabulary.txt
learning_rate: 0.0005
max_duration: 20
mean_std_path: dataset/mean_std.npz
min_duration: 0
num_conv_layers: 2
num_epoch: 50
num_rnn_layers: 3
num_workers: 8
pretrained_model: None
resume_model: None
rnn_layer_size: 1024
save_model: models/
test_manifest: dataset/manifest.test
train_manifest: dataset/manifest.train
------------------------------------------------
----------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
========================================================================================
Conv2D-1 [[1, 1, 161, 970]] [1, 32, 81, 324] 14,464
BatchNorm2D-1 [[1, 32, 81, 324]] [1, 32, 81, 324] 128
Hardtanh-1 [[1, 32, 81, 324]] [1, 32, 81, 324] 0
MaskConv-1 [[1, 32, 81, 324], [1]] [1, 32, 81, 324] 0
ConvBn-1 [[1, 1, 161, 970], [1]] [[1, 32, 81, 324], [1]] 0
Conv2D-2 [[1, 32, 81, 324]] [1, 32, 41, 324] 236,576
BatchNorm2D-2 [[1, 32, 41, 324]] [1, 32, 41, 324] 128
Hardtanh-2 [[1, 32, 41, 324]] [1, 32, 41, 324] 0
MaskConv-2 [[1, 32, 41, 324], [1]] [1, 32, 41, 324] 0
ConvBn-2 [[1, 32, 81, 324], [1]] [[1, 32, 41, 324], [1]] 0
ConvStack-1 [[1, 1, 161, 970], [1]] [[1, 32, 41, 324], [1]] 0
Linear-1 [[1, 324, 1312]] [1, 324, 3072] 4,033,536
BatchNorm1D-1 [[1, 324, 3072]] [1, 324, 3072] 12,288
GRU-1 [] [[1, 324, 2048], [2, 1, 1024]] 25,178,112
MaskRNN-1 [[1, 324, 2048], [1]] [1, 324, 2048] 0
BiGRUWithBN-1 [[1, 324, 1312], [1]] [1, 324, 2048] 0
Linear-2 [[1, 324, 2048]] [1, 324, 3072] 6,294,528
BatchNorm1D-2 [[1, 324, 3072]] [1, 324, 3072] 12,288
GRU-2 [] [[1, 324, 2048], [2, 1, 1024]] 25,178,112
MaskRNN-2 [[1, 324, 2048], [1]] [1, 324, 2048] 0
BiGRUWithBN-2 [[1, 324, 2048], [1]] [1, 324, 2048] 0
Linear-3 [[1, 324, 2048]] [1, 324, 3072] 6,294,528
BatchNorm1D-3 [[1, 324, 3072]] [1, 324, 3072] 12,288
GRU-3 [] [[1, 324, 2048], [2, 1, 1024]] 25,178,112
MaskRNN-3 [[1, 324, 2048], [1]] [1, 324, 2048] 0
BiGRUWithBN-3 [[1, 324, 2048], [1]] [1, 324, 2048] 0
RNNStack-1 [[1, 324, 1312], [1]] [1, 324, 2048] 0
BatchNorm1D-4 [[1, 324, 2048]] [1, 324, 2048] 8,192
Linear-4 [[1, 324, 2048]] [1, 324, 2882] 5,905,218
========================================================================================
Total params: 98,358,498
Trainable params: 98,313,186
Non-trainable params: 45,312
----------------------------------------------------------------------------------------
Input size (MB): 0.60
Forward/backward pass size (MB): 159.92
Params size (MB): 375.21
Estimated Total Size (MB): 535.72
----------------------------------------------------------------------------------------
[2021-09-17 10:46:03.117764] 訓練數據:13254
............
[2021-09-17 08:41:16.135825] Train epoch: [24/50], batch: [5900/6349], loss: 3.84609, learning rate: 0.00000688, eta: 10:38:40
[2021-09-17 08:41:38.698795] Train epoch: [24/50], batch: [6000/6349], loss: 0.92967, learning rate: 0.00000688, eta: 8:42:11
[2021-09-17 08:42:04.166192] Train epoch: [24/50], batch: [6100/6349], loss: 2.05670, learning rate: 0.00000688, eta: 10:59:51
[2021-09-17 08:42:26.471328] Train epoch: [24/50], batch: [6200/6349], loss: 3.03502, learning rate: 0.00000688, eta: 11:51:28
[2021-09-17 08:42:50.002897] Train epoch: [24/50], batch: [6300/6349], loss: 2.49653, learning rate: 0.00000688, eta: 12:01:30
======================================================================
[2021-09-17 08:43:01.954403] Test batch: [0/65], loss: 13.76276, cer: 0.23105
[2021-09-17 08:43:07.817434] Test epoch: 24, time/epoch: 0:24:30.756875, loss: 6.90274, cer: 0.15213
======================================================================
可以用使用python train.py --help命令查看各個參數的說明和默認值。
- 在訓練過程中,程序會使用VisualDL記錄訓練結果,可以通過以下的命令啓動VisualDL。
visualdl --logdir=log --host 0.0.0.0
- 然後再瀏覽器上訪問
http://localhost:8040可以查看結果顯示,如下。
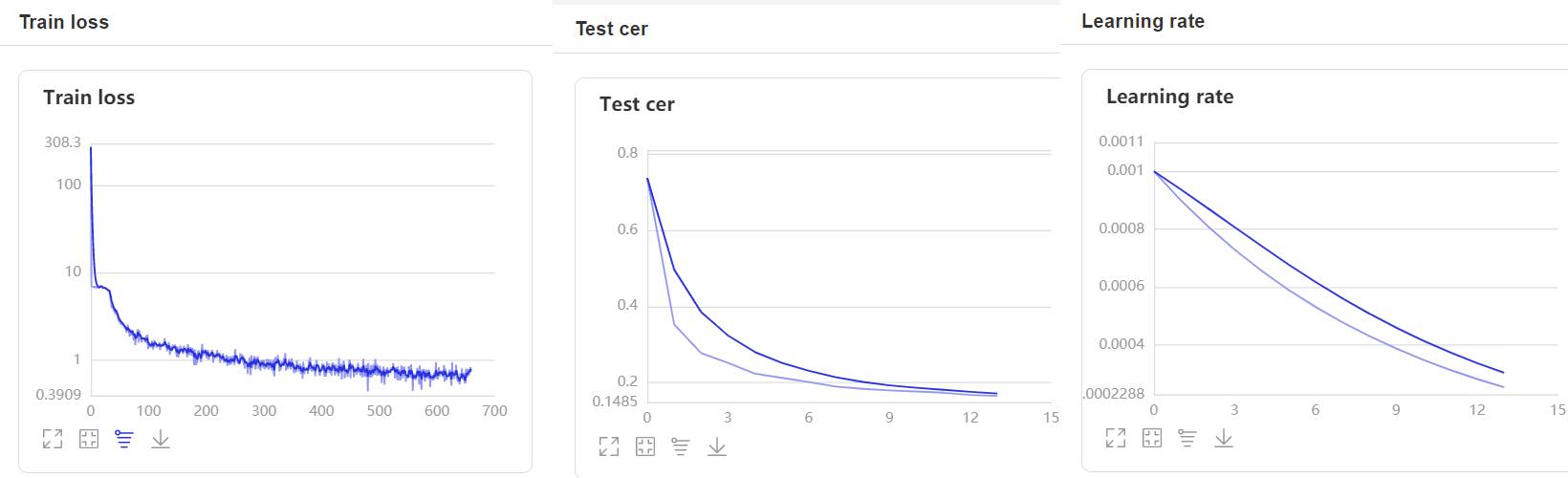
評估¶
在評估和預測中,使用--decoder參數可以指定解碼方法,當--decoder參數爲ctc_greedy對結果解碼的貪心策略解碼方法,貪心策略是在每一步選擇概率最大的輸出值,然後刪除重複字符和空索引,就得到預測結果了。當--decoder參數爲ctc_beam_search對結果解碼的集束搜索解碼方法,該方法可以加載語言模型,將模型輸出的結果在語音模型中搜索最優解。
- 我們可以使用這個腳本對模型進行評估,通過字符錯誤率來評價模型的性能。參數
--decoder默認指定集束搜索解碼方法對結果進行解碼,讀者也可以使用貪心策略解碼方法,對比他們的解碼的準確率。參數--mean_std_path指定均值和標準值得文件,這個文件需要跟訓練時使用的是同一個文件。參數--beam_size指定集束搜索方法的搜索寬度,越大解碼結果越準確,但是解碼速度就越慢。參數--model_path指定模型所在的文件夾的路徑。
```shell script
python3 eval.py –model_path=models/epoch_50/
可以用使用`python eval.py --help`命令查看各個參數的說明和默認值。
# 導出模型
在訓練時,我們保存了模型的參數,但是如何要用於推理,還需要導出預測模型,執行下面命令導出模型。模型的結構參數必須跟訓練時的一致。
```shell
python export_model.py --resume=models/epoch_50/
可以用使用python export_model.py --help命令查看各個參數的說明和默認值。
預測¶
- 我們可以使用這個腳本使用模型進行預測,通過傳遞音頻文件的路徑進行識別。參數
--decoder默認指定集束搜索解碼方法對結果進行解碼,讀者也可以使用貪心策略解碼方法,對比他們的解碼的準確率。參數--mean_std_path指定均值和標準值得文件,這個文件需要跟訓練時使用的是同一個文件。參數--beam_size指定集束搜索方法的搜索寬度,越大解碼結果越準確,但是解碼速度就越慢。參數model_path指定模型所在的文件夾的路徑,參數wav_path指定需要預測音頻文件的路徑。
shell script python3 infer.py --audio_path=dataset/test.wav
可以用使用python infer.py --help命令查看各個參數的說明和默認值。
模型下載¶
| 數據集 | 卷積層數量 | 循環神經網絡的數量 | 循環神經網絡的大小 | 測試集字錯率 | 下載地址 |
|---|---|---|---|---|---|
| aishell(179小時) | 2 | 3 | 1024 | 0.083327 | 點擊下載 |
| free_st_chinese_mandarin_corpus(109小時) | 2 | 3 | 1024 | 0.143291 | 點擊下載 |
| thchs_30(34小時) | 2 | 3 | 1024 | 0.047665 | 點擊下載 |
說明: 這裏提供的是訓練參數,如果要用於預測,還需要執行導出模型,使用的解碼方法是集束搜索。