前言¶
本項目使用了EcapaTdnn、ResNetSE、ERes2Net、CAM++等多種先進的聲紋識別模型,不排除以後會支持更多模型,同時本項目也支持了MelSpectrogram、Spectrogram、MFCC、Fbank等多種數據預處理方法,使用了ArcFace Loss,ArcFace loss:Additive Angular Margin Loss(加性角度間隔損失函數),對應項目中的AAMLoss,對特徵向量和權重歸一化,對θ加上角度間隔m,角度間隔比餘弦間隔在對角度的影響更加直接,除此之外,還支持AMLoss、ARMLoss、CELoss等多種損失函數。
源碼地址:VoiceprintRecognition-PaddlePaddle
使用環境:
- Anaconda 3
- Python 3.8
- PaddlePaddle 2.4.1
- Windows 10 or Ubuntu 18.04
項目特性¶
- 支持模型:EcapaTdnn、TDNN、Res2Net、ResNetSE、ERes2Net、CAM++
- 支持池化層:AttentiveStatsPool(ASP)、SelfAttentivePooling(SAP)、TemporalStatisticsPooling(TSP)、TemporalAveragePooling(TAP)、TemporalStatsPool(TSTP)
- 支持損失函數:AAMLoss、AMLoss、ARMLoss、CELoss
- 支持預處理方法:MelSpectrogram、Spectrogram、MFCC、Fbank
模型論文:
- EcapaTdnn:ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification
- TDNN:Prediction of speech intelligibility with DNN-based performance measures
- Res2Net:Res2Net: A New Multi-scale Backbone Architecture
- ResNetSE:Squeeze-and-Excitation Networks
- CAMPPlus:CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
- ERes2Net:An Enhanced Res2Net with Local and Global Feature Fusion for Speaker Verification
模型下載¶
訓練CN-Celeb數據,共有2796個說話人。¶
| 模型 | Params(M) | 預處理方法 | 數據集 | train speakers | threshold | EER | MinDCF | 模型下載 |
|---|---|---|---|---|---|---|---|---|
| CAM++ | 7.5 | Fbank | CN-Celeb | 2796 | 0.25 | 0.09485 | 0.56214 | 加入知識星球獲取 |
| ERes2Net | 8.2 | Fbank | CN-Celeb | 2796 | 0.22 | 0.09637 | 0.52627 | 加入知識星球獲取 |
| ResNetSE | 10.7 | Fbank | CN-Celeb | 2796 | 0.19 | 0.10222 | 0.57981 | 加入知識星球獲取 |
| EcapaTdnn | 6.7 | Fbank | CN-Celeb | 2796 | 0.25 | 0.10465 | 0.58521 | 加入知識星球獲取 |
| TDNN | 3.2 | Fbank | CN-Celeb | 2796 | 0.23 | 0.11804 | 0.61070 | 加入知識星球獲取 |
| Res2Net | 7.2 | Fbank | CN-Celeb | 2796 | 0.18 | 0.14126 | 0.68511 | 加入知識星球獲取 |
| CAM++ | 7.5 | Fbank | 更大數據集 | 2W+ | 0.34 | 0.07884 | 0.52738 | 加入知識星球獲取 |
| ERes2Net | 8.2 | Fbank | 其他數據集 | 20W | 0.36 | 0.02939 | 0.18355 | 加入知識星球獲取 |
| CAM++ | 7.5 | Flank | 其他數據集 | 20W | 0.29 | 0.04768 | 0.31429 | 加入知識星球獲取 |
說明:
1. 評估的測試集爲CN-Celeb的測試集,包含196個說話人。
2. 使用語速增強分類大小翻三倍speed_perturb_3_class: True。
3. 參數數量不包含了分類器的參數數量。
訓練VoxCeleb1&2數據,共有7205個說話人。¶
| 模型 | Params(M) | 預處理方法 | 數據集 | train speakers | threshold | EER | MinDCF | 模型下載 |
|---|---|---|---|---|---|---|---|---|
| CAM++ | 6.8 | Fbank | VoxCeleb1&2 | 7205 | 加入知識星球獲取 | |||
| ERes2Net | 6.6 | Fbank | VoxCeleb1&2 | 7205 | 加入知識星球獲取 | |||
| ResNetSE | 7.8 | Fbank | VoxCeleb1&2 | 7205 | 加入知識星球獲取 | |||
| EcapaTdnn | 6.1 | Fbank | VoxCeleb1&2 | 7205 | 加入知識星球獲取 | |||
| TDNN | 2.6 | Fbank | VoxCeleb1&2 | 7205 | 加入知識星球獲取 | |||
| Res2Net | 5.0 | Fbank | VoxCeleb1&2 | 7205 | 加入知識星球獲取 | |||
| CAM++ | 6.8 | Fbank | 更大數據集 | 2W+ | 加入知識星球獲取 | |||
| ERes2Net | 55.1 | Fbank | 其他數據集 | 20W+ | 加入知識星球獲取 | |||
| CAM++ | 6.8 | Fbank | 其他數據集 | 20W+ | 加入知識星球獲取 |
說明:
- 評估的測試集爲VoxCeleb1&2的測試集,包含158個說話人。
- 使用語速增強分類大小翻三倍
speed_perturb_3_class: True。 - 參數數量不包含了分類器的參數數量。
安裝環境¶
- 首先安裝的是PaddlePaddle的GPU版本,如果已經安裝過了,請跳過。
conda install paddlepaddle-gpu==2.4.1 cudatoolkit=10.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
- 安裝ppvector庫。
使用pip安裝,命令如下:
python -m pip install ppvector -U -i https://pypi.tuna.tsinghua.edu.cn/simple
建議源碼安裝,源碼安裝能保證使用最新代碼。
git clone https://github.com/yeyupiaoling/VoiceprintRecognition_PaddlePaddle.git
cd VoiceprintRecognition_PaddlePaddle/
python setup.py install
修改預處理方法¶
配置文件中默認使用的是Fbank預處理方法,如果要使用其他預處理方法,可以修改配置文件中的安裝下面方式修改,具體的值可以根據自己情況修改。如果不清楚如何設置參數,可以直接刪除該部分,直接使用默認值。
# 數據預處理參數
preprocess_conf:
# 音頻預處理方法,支持:LogMelSpectrogram、MelSpectrogram、Spectrogram、MFCC、Fbank
feature_method: 'Fbank'
# 設置API參數,更參數查看對應API,不清楚的可以直接刪除該部分,直接使用默認值
method_args:
sr: 16000
n_mels: 80
訓練模型¶
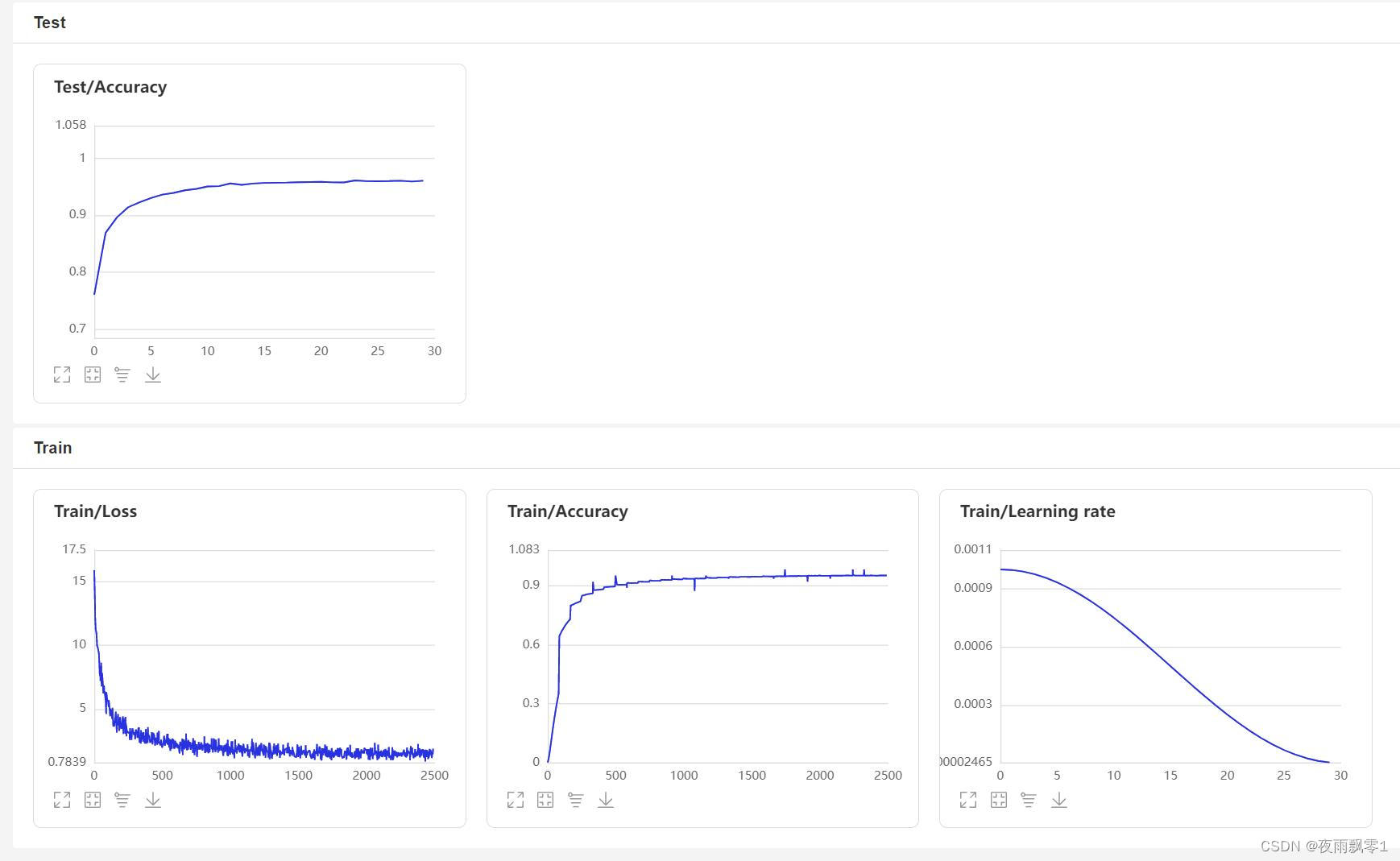
使用train.py訓練模型,本項目支持多個音頻預處理方式,通過configs/ecapa_tdnn.yml配置文件的參數preprocess_conf.feature_method可以指定,MelSpectrogram爲梅爾頻譜,Spectrogram爲語譜圖,MFCC梅爾頻譜倒譜系數。通過參數augment_conf_path可以指定數據增強方式。訓練過程中,會使用VisualDL保存訓練日誌,通過啓動VisualDL可以隨時查看訓練結果,啓動命令visualdl --logdir=log --host 0.0.0.0
# 單卡訓練
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡訓練
python -m paddle.distributed.launch --gpus '0,1' train.py
訓練輸出日誌:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 額外配置參數 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件參數 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
----------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
========================================================================================
Conv1D-2 [[1, 64, 102]] [1, 512, 98] 164,352
Conv1d-1 [[1, 64, 98]] [1, 512, 98] 0
ReLU-1 [[1, 512, 98]] [1, 512, 98] 0
BatchNorm1D-2 [[1, 512, 98]] [1, 512, 98] 2,048
BatchNorm1d-1 [[1, 512, 98]] [1, 512, 98] 0
TDNNBlock-1 [[1, 64, 98]] [1, 512, 98] 0
Conv1D-4 [[1, 512, 98]] [1, 512, 98] 262,656
Conv1d-3 [[1, 512, 98]] [1, 512, 98] 0
ReLU-2 [[1, 512, 98]] [1, 512, 98] 0
BatchNorm1D-4 [[1, 512, 98]] [1, 512, 98] 2,048
BatchNorm1d-3 [[1, 512, 98]] [1, 512, 98] 0
TDNNBlock-2 [[1, 512, 98]] [1, 512, 98] 0
··········································
SEBlock-3 [[1, 512, 98], None] [1, 512, 98] 0
SERes2NetBlock-3 [[1, 512, 98]] [1, 512, 98] 0
Conv1D-70 [[1, 1536, 98]] [1, 1536, 98] 2,360,832
Conv1d-69 [[1, 1536, 98]] [1, 1536, 98] 0
ReLU-32 [[1, 1536, 98]] [1, 1536, 98] 0
BatchNorm1D-58 [[1, 1536, 98]] [1, 1536, 98] 6,144
BatchNorm1d-57 [[1, 1536, 98]] [1, 1536, 98] 0
TDNNBlock-29 [[1, 1536, 98]] [1, 1536, 98] 0
Conv1D-72 [[1, 4608, 98]] [1, 128, 98] 589,952
Conv1d-71 [[1, 4608, 98]] [1, 128, 98] 0
ReLU-33 [[1, 128, 98]] [1, 128, 98] 0
BatchNorm1D-60 [[1, 128, 98]] [1, 128, 98] 512
BatchNorm1d-59 [[1, 128, 98]] [1, 128, 98] 0
TDNNBlock-30 [[1, 4608, 98]] [1, 128, 98] 0
Tanh-1 [[1, 128, 98]] [1, 128, 98] 0
Conv1D-74 [[1, 128, 98]] [1, 1536, 98] 198,144
Conv1d-73 [[1, 128, 98]] [1, 1536, 98] 0
AttentiveStatisticsPooling-1 [[1, 1536, 98]] [1, 3072, 1] 0
BatchNorm1D-62 [[1, 3072, 1]] [1, 3072, 1] 12,288
BatchNorm1d-61 [[1, 3072, 1]] [1, 3072, 1] 0
Conv1D-76 [[1, 3072, 1]] [1, 192, 1] 590,016
Conv1d-75 [[1, 3072, 1]] [1, 192, 1] 0
EcapaTdnn-1 [[1, 98, 64]] [1, 192] 0
SpeakerIdentification-1 [[1, 192]] [1, 9726] 1,867,392
========================================================================================
Total params: 8,039,808
Trainable params: 8,020,480
Non-trainable params: 19,328
----------------------------------------------------------------------------------------
Input size (MB): 0.02
Forward/backward pass size (MB): 35.60
Params size (MB): 30.67
Estimated Total Size (MB): 66.30
----------------------------------------------------------------------------------------
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 訓練數據:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
VisualDL頁面:
評估模型¶
訓練結束之後會保存預測模型,我們用預測模型來預測測試集中的音頻特徵,然後使用音頻特徵進行兩兩對比,計算EER和MinDCF。
python eval.py
輸出類似如下:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加載模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
開始兩兩對比音頻特徵...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
評估消耗時間:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
聲紋對比¶
下面開始實現聲紋對比,創建infer_contrast.py程序,編寫infer()函數,在編寫模型的時候,模型是有兩個輸出的,第一個是模型的分類輸出,第二個是音頻特徵輸出。所以在這裏要輸出的是音頻的特徵值,有了音頻的特徵值就可以做聲紋識別了。我們輸入兩個語音,通過預測函數獲取他們的特徵數據,使用這個特徵數據可以求他們的對角餘弦值,得到的結果可以作爲他們相識度。對於這個相識度的閾值threshold,讀者可以根據自己項目的準確度要求進行修改。
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wav
輸出類似如下:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 額外配置參數 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加載模型參數和優化方法參數:models/ecapa_tdnn/model.pdparams
audio/a_1.wav 和 audio/b_2.wav 不是同一個人,相似度爲:-0.09565544128417969
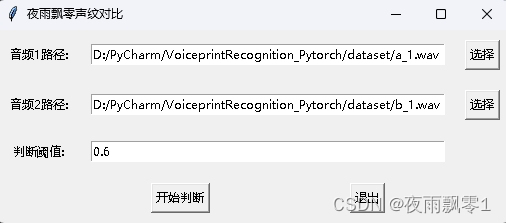
同時還提供了有GUI界面的聲紋對比程序,執行infer_contrast_gui.py啓動程序,界面如下,分別選擇兩個音頻,點擊開始判斷,就可以判斷它們是否是同一個人。
聲紋識別¶
在上面的聲紋對比的基礎上,我們創建infer_recognition.py實現聲紋識別。同樣是使用上面聲紋對比的infer()預測函數,通過這兩個同樣獲取語音的特徵數據。 不同的是筆者增加了load_audio_db()和register(),以及recognition(),第一個函數是加載聲紋庫中的語音數據,這些音頻就是相當於已經註冊的用戶,他們註冊的語音數據會存放在這裏,如果有用戶需要通過聲紋登錄,就需要拿到用戶的語音和語音庫中的語音進行聲紋對比,如果對比成功,那就相當於登錄成功並且獲取用戶註冊時的信息數據。第二個函數register()其實就是把錄音保存在聲紋庫中,同時獲取該音頻的特徵添加到待對比的數據特徵中。最後recognition()函數中,這個函數就是將輸入的語音和語音庫中的語音一一對比。
有了上面的聲紋識別的函數,讀者可以根據自己項目的需求完成聲紋識別的方式,例如筆者下面提供的是通過錄音來完成聲紋識別。首先必須要加載語音庫中的語音,語音庫文件夾爲audio_db,然後用戶回車後錄音3秒鐘,然後程序會自動錄音,並使用錄音到的音頻進行聲紋識別,去匹配語音庫中的語音,獲取用戶的信息。通過這樣方式,讀者也可以修改成通過服務請求的方式完成聲紋識別,例如提供一個API供APP調用,用戶在APP上通過聲紋登錄時,把錄音到的語音發送到後端完成聲紋識別,再把結果返回給APP,前提是用戶已經使用語音註冊,併成功把語音數據存放在audio_db文件夾中。
python infer_recognition.py
輸出類似如下:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 額外配置參數 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加載模型參數和優化方法參數:models/ecapa_tdnn/model.pdparams
Loaded 沙瑞金 audio.
Loaded 李達康 audio.
請選擇功能,0爲註冊音頻到聲紋庫,1爲執行聲紋識別:0
按下回車鍵開機錄音,錄音3秒中:
開始錄音......
錄音已結束!
請輸入該音頻用戶的名稱:夜雨飄零
請選擇功能,0爲註冊音頻到聲紋庫,1爲執行聲紋識別:1
按下回車鍵開機錄音,錄音3秒中:
開始錄音......
錄音已結束!
識別說話的爲:夜雨飄零,相似度爲:0.920434
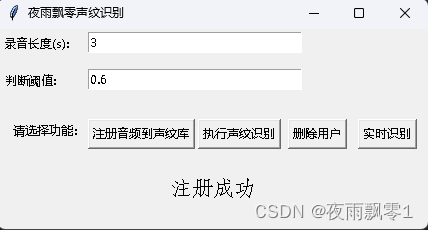
同時還提供了有GUI界面的聲紋識別程序,執行infer_recognition_gui.py啓動,點擊註冊音頻到聲紋庫按鈕,理解開始說話,錄製3秒鐘,然後輸入註冊人的名稱,之後可以執行聲紋識別按鈕,然後立即說話,錄製3秒鐘後,等待識別結果。刪除用戶按鈕可以刪除用戶。即時識別按鈕可以即時識別,可以一直錄音,一直識別。
其他版本¶
- Tensorflow:VoiceprintRecognition-Tensorflow
- Pytorch:VoiceprintRecognition-Pytorch
- Keras:VoiceprintRecognition-Keras
參考資料¶
- https://github.com/PaddlePaddle/PaddleSpeech
- https://github.com/yeyupiaoling/PaddlePaddle-MobileFaceNets
- https://github.com/yeyupiaoling/PPASR