前言¶
MediaPipe是Google開源的一個用於構建感知管道以處理視頻、音頻等時間序列數據的框架。其中MediaPipe Hands是一個高性能的手部關鍵點檢測解決方案,能夠在移動設備上即時檢測手部關鍵點。本項目主要基於MediaPipe Model Maker來訓練自定義手勢識別模型,支持石頭、剪刀、布、無手勢等多種手勢的識別。項目提供了完整的訓練和推理流程,支持圖片和視頻兩種推理模式,可以即時檢測和識別手勢。
使用環境:
- Python 3.11
- TensorFlow 2.15.1
- MediaPipe 0.10.21
- Ubuntu 22.04
項目主要程序介紹¶
train.py:訓練自定義手勢識別模型。infer.py:使用訓練好的模型進行手勢識別推理,支持圖片和視頻模式。utils.py:工具函數,包含手部關鍵點繪製和手勢信息顯示功能。models/:存放預訓練模型和自定義訓練模型的目錄。dataset/:訓練數據集目錄,包含不同手勢的圖片數據。
安裝環境¶
-
首先安裝Python環境,推薦使用Python 3.8或更高版本。
-
安裝所需的依賴庫。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
準備數據¶
訓練數據集存放在dataset/images/目錄下,按照不同的手勢類型分別存放在不同的子目錄中,自定義的數據集可以存放在這個位置,根據自己的清空創建更多的文件夾,圖片是包含一個手勢:
dataset/
- images/
- rock/ # 石頭手勢圖片
- paper/ # 布手勢圖片
- scissors/ # 剪刀手勢圖片
- none/ # 無手勢/背景圖片
每個手勢類型建議準備100-200張不同角度、不同光照條件下的圖片,以提高模型的泛化能力。圖片格式支持jpg、png等常見格式。
訓練模型¶
準備好數據之後,就可以開始訓練自定義手勢識別模型了。訓練程序會自動讀取數據集,並使用MediaPipe Model Maker進行訓練。
訓練參數說明¶
在train.py中可以調整以下主要參數:
learning_rate:學習率,默認爲0.001batch_size:批大小,默認爲2epochs:訓練輪數,默認爲10shuffle:是否打亂數據,默認爲True
開始訓練¶
訓練的代碼片段:
from mediapipe_model_maker import gesture_recognizer
# 讀取數據集
data = gesture_recognizer.Dataset.from_folder(
dirname="dataset/images",
hparams=gesture_recognizer.HandDataPreprocessingParams()
)
# 數據分割
train_data, rest_data = data.split(0.8)
validation_data, test_data = rest_data.split(0.5)
# 設置訓練參數
hparams = gesture_recognizer.HParams(
learning_rate=0.001,
batch_size=2,
epochs=10,
shuffle=True
)
# 訓練模型
model = gesture_recognizer.GestureRecognizer.create(
train_data=train_data,
validation_data=validation_data,
options=gesture_recognizer.GestureRecognizerOptions(hparams=hparams)
)
# 評估和導出
loss, acc = model.evaluate(test_data, batch_size=1)
model.export_model(model_name="custom_gesture_recognizer.task")
完整的代碼在train.py。
python train.py
訓練過程中會顯示訓練進度和損失值:
標籤列表:['none', 'paper', 'rock', 'scissors']
Model checkpoint saved at exported_model/checkpoint
Training finished.
Test loss:0.123, Test accuracy:0.95
訓練完成後,模型會自動保存到models/custom_gesture_recognizer.task。
模型推理¶
項目支持兩種推理模式:圖片推理和視頻推理。
圖片推理¶
對單張圖片進行手勢識別,簡單的代碼片段。
import cv2
import mediapipe as mp
from utils import draw_landmarks_and_connections, draw_gesture_info, HAND_CONNECTIONS
# 創建手勢識別器
BaseOptions = mp.tasks.BaseOptions
GestureRecognizer = mp.tasks.vision.GestureRecognizer
GestureRecognizerOptions = mp.tasks.vision.GestureRecognizerOptions
VisionRunningMode = mp.tasks.vision.RunningMode
options = GestureRecognizerOptions(
base_options=BaseOptions(model_asset_path='models/custom_gesture_recognizer.task'),
num_hands=2,
running_mode=VisionRunningMode.IMAGE)
with GestureRecognizer.create_from_options(options) as recognizer:
# 讀取圖片
mp_image = mp.Image.create_from_file('test.jpg')
result = recognizer.recognize(mp_image)
# 輸出識別結果
for i in range(len(result.gestures)):
print(f"第{i + 1}個手勢:{result.gestures[i][0].category_name},置信度:{result.gestures[i][0].score:.1%}")
完整代碼在infer.py
python infer.py
默認配置爲圖片模式,會對test2.jpg進行推理。可以在infer.py中修改以下參數:
mode:設置爲”image”model_asset_path:模型路徑,可選擇官方模型或自定義模型show_image_or_video:是否顯示結果圖片
視頻推理¶
對攝像頭即時視頻流進行手勢識別:
# 修改infer.py中的mode爲"video"
python infer.py
視頻模式相關參數:
mode:設置爲”video”video_path_or_id:視頻文件路徑或攝像頭ID(0爲默認攝像頭)show_image_or_video:是否顯示即時視頻窗口
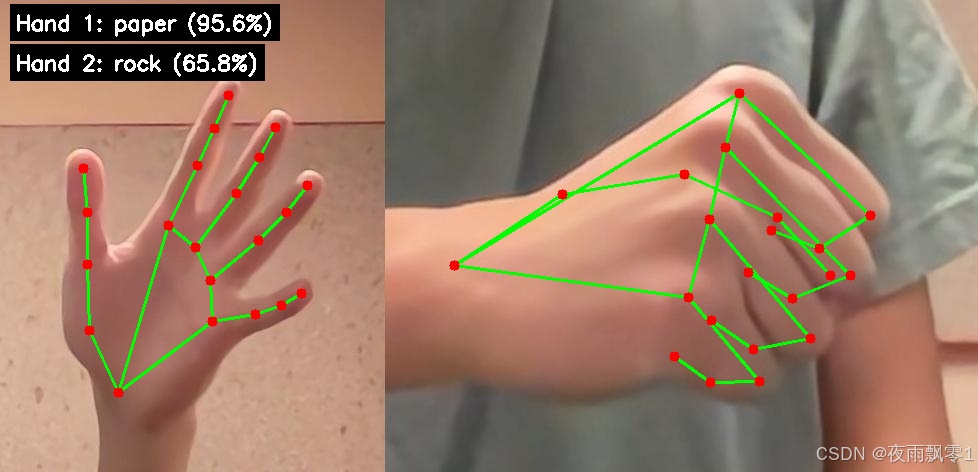
推理輸出¶
推理程序會輸出以下信息:
第1個手勢:rock,置信度:95.2%
第2個手勢:scissors,置信度:87.1%
結果圖像已保存爲 result_with_landmarks.jpg
同時會在圖片上繪製手部關鍵點和手勢識別結果。
獲取源碼¶
在微信公衆號回覆【MediaPipe自定義手勢識別訓練模型】獲取源碼