# 前言
在語音對話識別中,一般使用VAD檢測用戶時候結束說話,但是這個結束時間長度設置多少合適,這很難抉擇,太短了,用戶說話慢就容易打斷,太長了用戶等待時間久。還有常見的情況,用戶在說話的時候,中途停頓了一下思考,如果只是使用VAD檢測,有可能就會認爲說話結束,但是用戶還沒有說話,這句話也不完整。這種情況可以配合文本端點檢測,在使用VAD檢測的時候,配合文本端點檢測,從而保證用戶表達完整。
原理¶
使用大語言模型檢測一句話是否完整,其實原理很簡單,就是利用了大語言模型的文本生成功能,讓模型推理下一個token是否爲結束符即可,或者下一個token是結束符的概率是多少。
如下兩個例子,輸入一個缺少結束符<|im_end|>的文本,讓模型預測下一個字符,如果是結束字符,就代表這句話已經說完。模型之所以能夠這樣輸出,是因爲我們微調模型的時候輸入的格式都是<|im_start|><|user|>你叫什麼名字<|im_end|><|im_start|><|assistant|>我叫夜雨飄零<|im_end|>,所以模型可以按照這個格式推理輸出。
未結束的一段話,模型識別情況
# 例如輸入的文本如下:
<|im_start|><|user|>你叫什麼名
# 模型輸出
<|im_start|><|user|>你叫什麼名字
完整的一句,模型識別的情況。
# 例如輸入的文本如下:
<|im_start|><|user|>你叫什麼名字
# 模型輸出
<|im_start|><|user|>你叫什麼名字<|im_end|>
準備數據¶
這裏可以推薦一個數據集alpaca_gpt4_zh,但這個數據還需要處理一下,訓練的數據格式與平時微調大語言模型的數據格式一樣,不過爲了訓練更快,和更適合使用情況,主要做以下一下調整:
instruction字段不要太長,一般用戶輸入也會長篇大論。output字段可以設置爲空,這一步可以使得輸入數據大大縮短,提高訓練速度。
例子數據如下:
[
{
"instruction": "我們如何在日常生活中減少用水",
"input": "",
"output": ""
},
{
"instruction": "編輯文章使其更吸引讀者",
"input": "",
"output": ""
},
]
微調模型¶
微調模型博主使用工具是LLaMA-Factory,具體怎麼使用,開發者們可以自行查看官方文檔,這裏就不贅述了,只介紹需要的數據格式和幾個訓練注意事項。
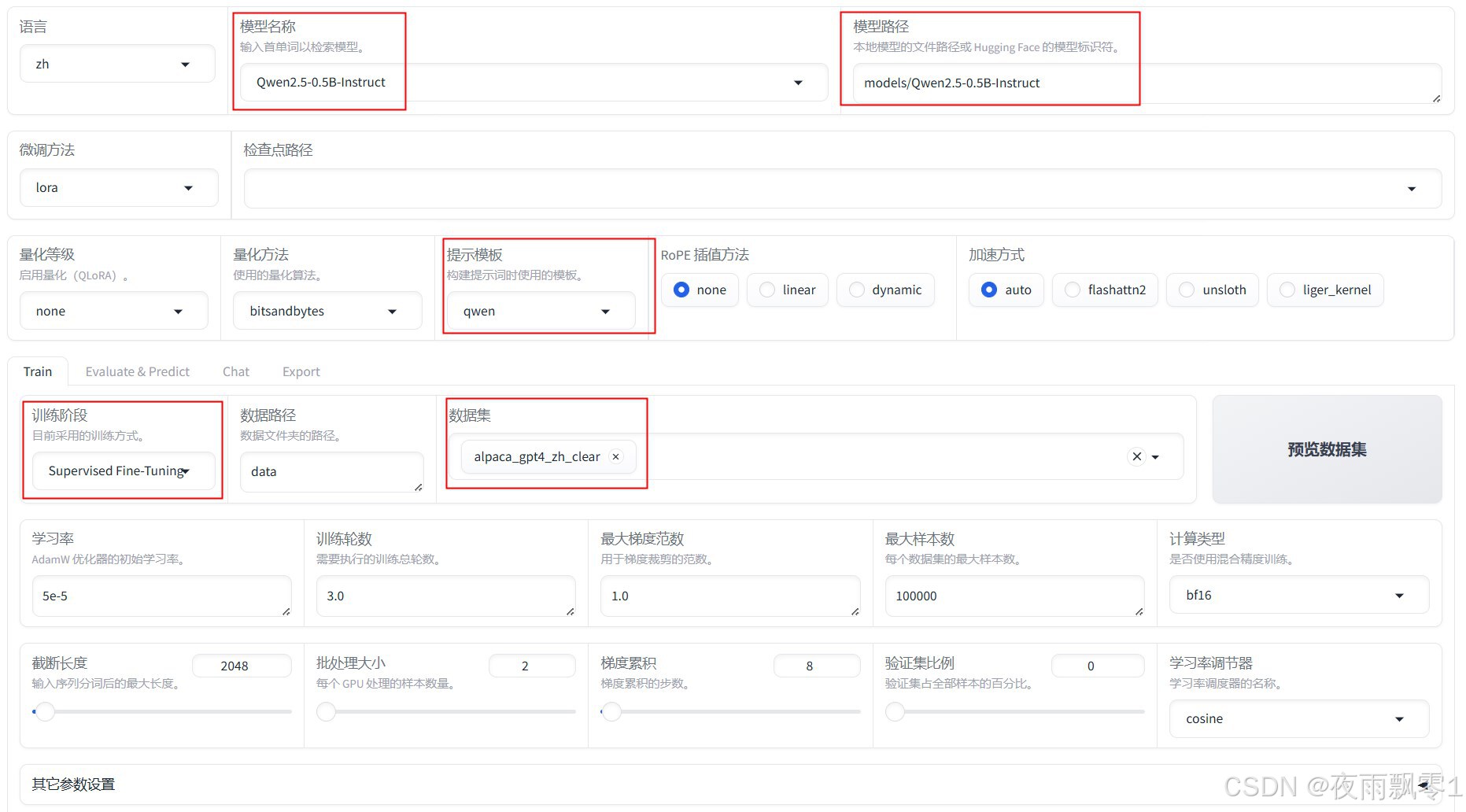
如圖所示,這裏選擇了一個非常小的Qwen模型,因爲要追求推理速度。然後是選擇提示模板,這個很重要,不同的模型的模板不一樣。
最後就是選擇自己處理後的數據。
訓練結束之後,記得要選擇檢查點路徑,並導出模型。
量化模型¶
爲了CPU下追求更快的速度,可以導出爲ONNX模型,同時也量化模型,注意Windows使用量化模型推理結果可能不準確。
轉換代碼如下,這裏通過轉換爲量化和未量化的ONNX模型。
import argparse
from optimum.onnxruntime import ORTQuantizer, ORTModelForCausalLM
from optimum.onnxruntime.configuration import AutoQuantizationConfig
from transformers import AutoTokenizer
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--model", type=str, default="models/Qwen2.5-0.5B-Instruct")
parser.add_argument("--save_dir", type=str, default="models/Qwen2.5-0.5B-Instruct-onnx")
args = parser.parse_args()
# Load a model from transformers and export it to ONNX
ort_model = ORTModelForCausalLM.from_pretrained(args.model,
export=True,
task="text-generation-with-past")
tokenizer = AutoTokenizer.from_pretrained(args.model)
ort_model.save_pretrained(args.save_dir)
tokenizer.save_pretrained(args.save_dir)
dqconfig = AutoQuantizationConfig.avx2(is_static=False,
per_channel=False,
use_symmetric_activations=True)
print("量化模型...")
quantizer = ORTQuantizer.from_pretrained(ort_model)
model_quantized_path = quantizer.quantize(save_dir=args.save_dir + "-quantize",
quantization_config=dqconfig)
文本端點檢測¶
使用代碼如下,如原理介紹部分所說,讓模型推理下一個token,並獲取該token爲結束符<|im_end|>得分是多少,通過這個得分判斷是否爲文本結束,博主建議閾值爲0.15,當然也可以使用其他值。
import numpy as np
import torch
from loguru import logger
from optimum.onnxruntime import ORTModelForCausalLM
from sklearn.utils.extmath import softmax
from transformers import AutoTokenizer
class TurnDetector:
def __init__(self, model_path):
self.model = ORTModelForCausalLM.from_pretrained(model_path)
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.eou_index = self.tokenizer.encode("<|im_end|>")[-1]
logger.info(f"結束符的token爲:{self.eou_index}")
def __call__(self, text):
messages = [{"role": "user", "content": text}]
text = self.tokenizer.apply_chat_template(messages,
add_generation_prompt=False,
add_special_tokens=False,
tokenize=False)
ix = text.rfind("<|im_end|>")
text = text[:ix]
model_inputs = self.tokenizer(text, return_tensors="pt")
position_ids = torch.arange(model_inputs['input_ids'].shape[1], dtype=torch.int64)[None, :]
model_inputs['position_ids'] = position_ids
outputs = self.model(**model_inputs).logits.numpy()
logits = outputs[0, -1, :]
probs = softmax(logits[np.newaxis, :])[0]
eou_probability = probs[self.eou_index]
return eou_probability
if __name__ == '__main__':
turn_detector = TurnDetector("models/Qwen2.5-0.5B-Instruct-finetune-onnx")
s = "你叫什"
result = turn_detector(s)
print(f'[{s}] 識別結果爲:{result:.3f}')
s = "你叫什麼名字"
result = turn_detector(s)
print(f'[{s}] 識別結果爲:{result:.3f}')
輸出結果:
2025-01-17 20:16:57.416 | INFO | __main__:__init__:14 - 結束符的token爲:151645
[你叫什] 識別結果爲:0.000
[你叫什麼名字] 識別結果爲:0.571