# CRNN
本項目是PaddlePaddle 2.0動態圖實現的CRNN文字識別模型,可支持長短不一的圖片輸入。CRNN是一種端到端的識別模式,不需要通過分割圖片即可完成圖片中全部的文字識別。CRNN的結構主要是CNN+RNN+CTC,它們分別的作用是,使用深度CNN,對輸入圖像提取特徵,得到特徵圖。使用雙向RNN(BLSTM)對特徵序列進行預測,對序列中的每個特徵向量進行學習,並輸出預測標籤(真實值)分佈。使用 CTC Loss,把從循環層獲取的一系列標籤分佈轉換成最終的標籤序列。
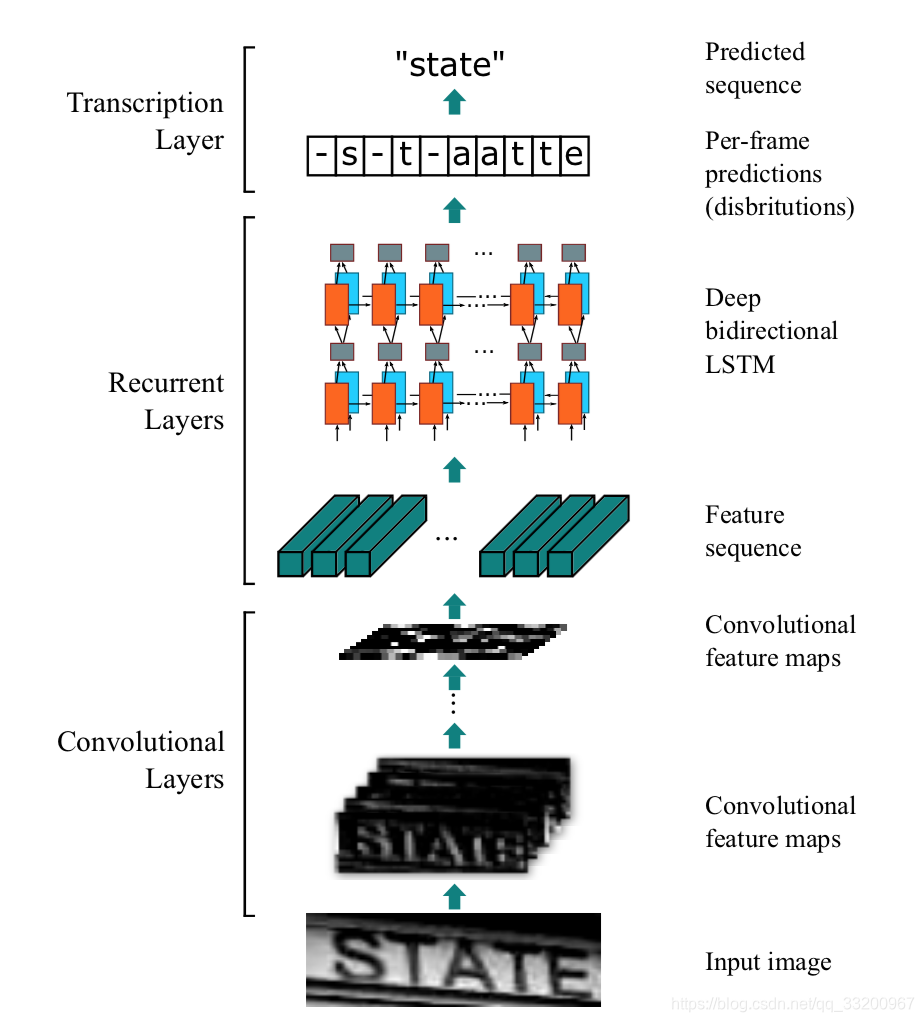
CRNN的結構如下,一張高爲32的圖片,寬度隨意,一張圖片經過多層卷積之後,高度就變成了1,經過paddle.squeeze()就去掉了高度,也就說從輸入的圖片BCHW經過卷積之後就成了BCW。然後把特徵順序從BCW改爲WBC輸入到RNN中,經過兩次的RNN之後,模型的最終輸入爲(W, B, Class_num)。這恰好是CTCLoss函數的輸入。
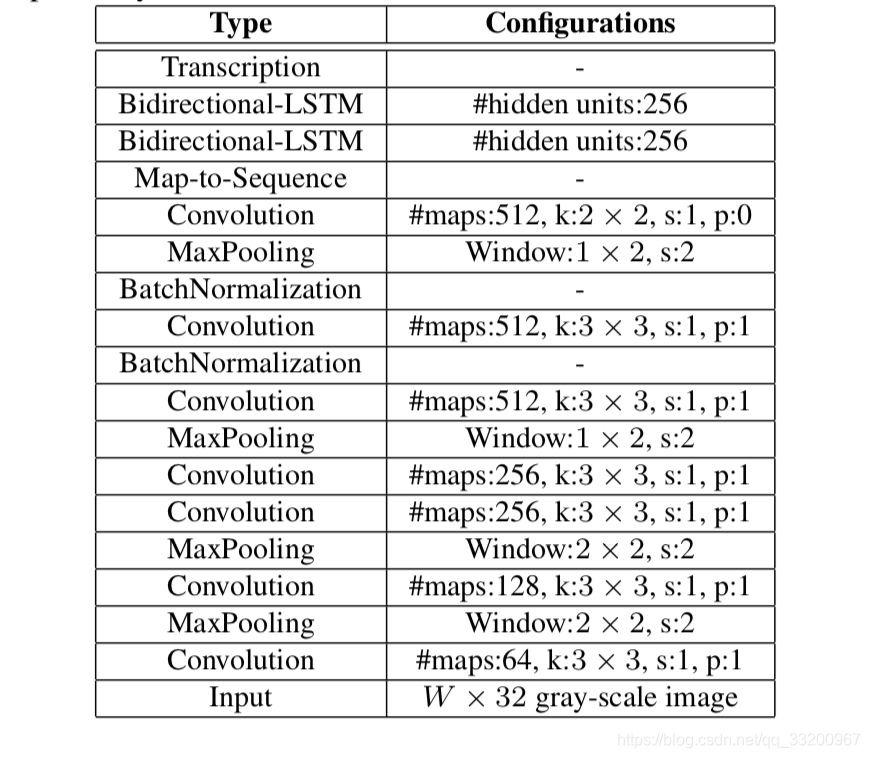
使用環境:
- PaddlePaddle 2.0.1
- Python 3.7
源碼地址:https://github.com/yeyupiaoling/PaddlePaddle-CRNN
在線運行一下:https://aistudio.baidu.com/aistudio/projectdetail/1751953
準備數據集¶
- 貼心的筆者準備了一個生成長度不一的驗證碼圖片作爲數據集,該程序可以自動生成圖片以及數據列表和數據詞彙表,需要讀者修改自己字體文件的路徑
font_path,網上下載一搜一大把,筆者用的是這個字體點擊下載 。
```shell script
python create_image.py
執行上面程序生成的圖片會放在`dataset/images`目錄下,生成的訓練數據列表和測試數據列表分別放在`dataset/train_list.txt`和`dataset/test_list.txt`,最後還有個數據詞彙表`dataset/vocabulary.txt`。
數據列表的格式如下,左邊是圖片的路徑,右邊是文字標籤。
```shell script
dataset/images/1617420021182_c1dw.jpg c1dw
dataset/images/1617420021204_uvht.jpg uvht
dataset/images/1617420021227_hb30.jpg hb30
dataset/images/1617420021266_4nkx.jpg 4nkx
dataset/images/1617420021296_80nv.jpg 80nv
以下是數據集詞彙表的格式,一行一個字符,第一行是空格,不代表任何字符。
```shell script
f
s
2
7
3
n
d
w
**訓練自定義數據,參考上面的格式即可。**
# 訓練
不管你是自定義數據集還是使用上面生成的數據,只要文件路徑正確,即可開始進行訓練。該訓練支持長度不一的圖片輸入,但是每一個batch的數據的數據長度還是要一樣的,這種情況下,筆者就用了`collate_fn()`函數,該函數可以把數據最長的找出來,然後把其他的數據補0,加到相同的長度。同時該函數還要輸出它其中每條數據標籤的實際長度,因爲損失函數需要輸入標籤的實際長度。
```shell script
python train.py
- 在訓練過程中,程序會使用VisualDL記錄訓練結果,可以通過以下的命令啓動VisualDL。
visualdl --logdir=log --host=0.0.0.0
- 然後再瀏覽器上訪問
http://localhost:8040可以查看結果顯示,如下。
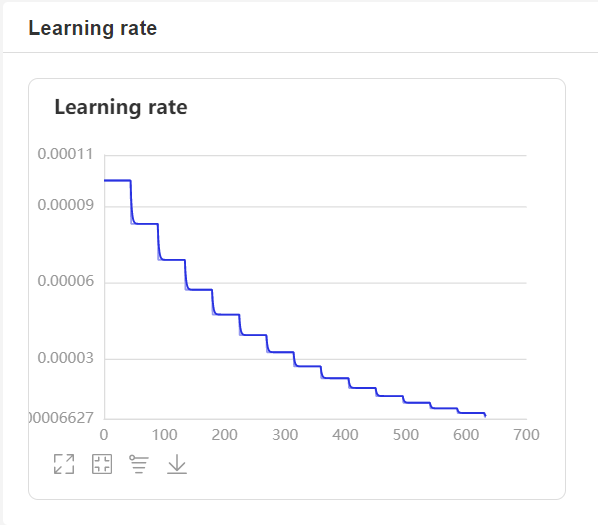
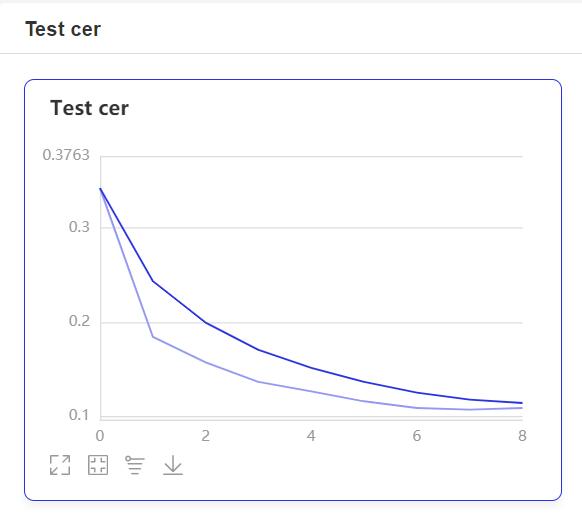
預測¶
訓練結束之後,使用保存的模型進行預測。通過修改image_path指定需要預測的圖片路徑,解碼方法,筆者使用了一個最簡單的貪心策略。
```shell script
python infer.py
輸出如下:
預測結果:2gmnt93e
```