# 目錄
@[toc]
深度學習的實踐方面¶
- 如果有10,000,000個例子,數據集拆分一般是98%訓練,1%驗證,1%測試。
- 驗證和測試的數據集通常是來自同樣的分配。
- 如果神經網絡模型有很大的差異,一般的解決辦法是增加數據集和添加正則。
- 當訓練集錯誤較小,而驗證集較大時,通常是增加正則lambda、增加數據集。
- 當增加正則化超參數lambda時,權重會被推向更小,接近0.
- 將參數keep_prob從(比如說)0.5增加到0.6可能會導致減少正則效應、最終導致更小的訓練集數據的錯誤。
- 增加訓練集、添加Dropout、加正則可以減少方差(減少過度擬合)。
- 權重衰減是一種正則化技術(如L2正規化), 導致梯度下降在每次迭代中收縮權重。
- 我們歸一化輸入的X,是因爲這個可以使得損失函數更快地進行優化。
- 在測試使用反向dropout方法時,不要使用dropout(不要使用隨機消除單位),也不要在訓練中使用計算中保留的1/keep_prob因子。
優化算法¶
- 當輸入是來自第8個小批次的第7個示例時,表示第3層的激活的符合是:\(a^{[3]\{8\}(7)}\)。
- 小批量梯度下降(在單個小批量上計算)的一次迭代比批量梯度下降的迭代快。
- 最好的小批量大小通常不是1而不是m,而是介於兩者之間。一、如果最小批量爲1,則會小批量樣本中失去向量化的好處。二、如果最小批量爲m,則最終會產生批量梯度下降,該批量梯度下降處理完成之前必須處理整個訓練集。
- 假設學習算法的成本\(J\),繪製爲迭代次數的函數,如下所示:
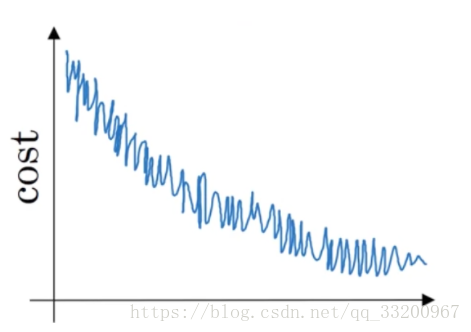
從圖中可以得知如果是使用小批量梯度下降法,看來是可以接受的,如果是使用批量梯度下降,有些事情是錯誤的。 - 假設1月前三天卡薩布蘭卡的氣溫相同:
1月1日:\(\theta_1 = 10^o C\)
1月2日: \(\theta_2 = 10^o C\)
假設使用指數加權平均\(\beta=0.5\)跟蹤溫度:\(v_0 = 0, v_t = \beta v_{t-1} +(1-\beta)\theta_t\)。可以得到2天后的值:\(v_2 = 7.5\),以及其修正偏差的值是:\(v_2^{corrected} = 10\)。 - \(\alpha = e^t \alpha_0\)不是一個好的學習率衰退的方法,其中t是epoch號碼。比較好的方法有:\(\alpha = 0.95^t \alpha_0\),\(\alpha = \frac{1}{\sqrt{t}} \alpha_0\),\(\alpha = \frac{1}{1+2*t} \alpha_0\) 這些。
- 倫敦溫度數據集上使用指數加權平均值。使用以下來跟蹤溫度:\(v_{t} = \beta v_{t-1} + (1-\beta)\theta_t\)。下面的紅線是用來計算的\(\beta=0.9\)。
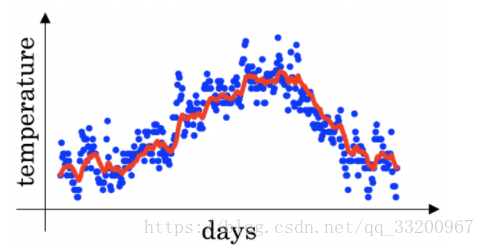
增加\(\beta\)會將紅線稍微向右移;降低\(\beta\)將在紅線內產生更多的振盪。 - 圖中:
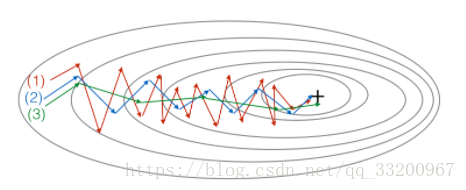
這個圖是梯度下降、動量梯度下降(\(\beta = 0.5\))和動量梯度下降(\(\beta= 0.9\))產生的。其中(1)是梯度下降。(2)是動量梯度下降(小\(\beta\))。(3)是動量梯度下降(大\(\beta\)) - 假設深度網絡中的批量梯度下降時間過長,爲找到對於成本函數實現較小值的參數值\(\mathcal{J}(W^{[1]},b^{[1]},..., W^{[L]},b^{[L]})\)。可以使用以下技術找到取得較小值的參數值\(\mathcal{J}\):一、嘗試調整學習率\(\alpha\);二、嘗試更好的隨機初始化權重;三、嘗試使用小批量梯度下降;四、嘗試使用Adam。
- 關於Adam的一些正確的說法:一、學習速率超參數\(\alpha\)在Adam通常需要調整;二、我們通常使用\(\beta_1,\beta_2\)和\(\varepsilon\)作爲Adam (\(\beta_1=0.9, \beta_2=0.999, \varepsilon = 10^{-8}\))超參數的默認值;三、Adam結合了RMSProp的優點和動量。
超參數調整,批量標準化,編程框架¶
- 在大量超參數中進行搜索,通常使用隨機值而不是網格中的值。
- 不是每個超參數都會對訓練產生巨大的負面影響,比如學習率,比其他參數更重要。
- 在超參數搜索過程中,無論您是嘗試照顧一個模型(“熊貓”策略)還是平行訓練大量模型(“魚子醬”),主要取決於可以訪問的計算能力的數量。
- 如果\(\beta\)(動量超參數)介於0.9和0.99之間,推薦使用以下方法用於對\(\beta\)值進行抽樣:
r = np.random.rand()
beta = 1-10**(- r - 1)
- 當找到非常好的超參數之後,並不是一勞永逸的,當網絡或者其他超參數改變之後,還要再次重新調整它們的。
- 在批量標準化中,如果將其應用於\(l\)你的神經網絡的第一層,\(z^{[l]}\)是規範化的公式。
- 在規範化公式中\(z_{norm}^{(i)} = \frac{z^{(i)} - \mu}{\sqrt{\sigma^2 + \varepsilon}}\),使用epsilon是避免\(z^{(i)} - \mu\)被零除。
- 在關於\(gamma\)和\(beta\)在批准規範中,他們可以使用Adam,動量梯度下降或RMSprop,而不僅僅是漸變下降來學習;他們設置線性變量的均值和方差是從\(z^{[l]}\)的給定圖層。
- 執行必要的規範化時,使用\(\mu\)
和\(\sigma^2\)估計在訓練期間的小批量的指數加權平均。 - 在深度學習框架中,即使項目目前是開源的,項目的良好治理也有助於確保項目長期保持開放,而不是被封閉或修改爲只有一家公司受益;通過編程框架,用戶可以使用比高級級語言(如Python)更少的代碼行編寫深度學習算法。