> 原文博客:Doi技術團隊
鏈接地址:https://blog.doiduoyi.com/authors/1584446358138
初心:記錄優秀的Doi技術團隊學習經歷
*本篇文章基於 PaddlePaddle 0.11.0、Python 2.7
前言¶
目標檢測的使用範圍很廣,比如我們使用相機拍照時,要正確檢測人臉的位置,從而做進一步處理,比如美顏等等。在目標檢測的深度學習領域上,從2014年到2016年,先後出現了R-CNN,Fast R-CNN, Faster R-CNN, ION, HyperNet, SDP-CRC, YOLO,G-CNN, SSD等神經網絡模型,使得目標檢測不管是在準確度上,還是速度上都有很大提高,幾乎可以達到即時檢測。
VOC數據集¶
VOC數據集介紹¶
PASCAL VOC挑戰賽是視覺對象的分類識別和檢測的一個基準測試,提供了檢測算法和學習性能的標準圖像註釋數據集和標準的評估系統。
PASCAL VOC圖片集包括20個目錄:
- 人類; 動物(鳥、貓、牛、狗、馬、羊);
- 交通工具(飛機、自行車、船、公共汽車、小轎車、摩托車、火車);
- 室內(瓶子、椅子、餐桌、盆栽植物、沙發、電視)。
這些類別在data/label_list文件中都有列出來,但這個文件中多了一個類別,就是背景(background)
下載VOC數據集¶
可以通過以下命令下載數據集
# 切換到項目的數據目錄
cd data
# 下載2007年的訓練數據
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
# 下載2007年的測試數據
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# 下載2012年的訓練數據
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
解壓數據集¶
下載完成之後,要解壓數據集到當前目錄
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtrainval_11-May-2012.tar
解壓之後會得到一個目錄,其中我們實質只用到Annotations(標註文件)和JPEGImages(圖像文件)下的文件。
VOCdevkit
|____VOC2007
| |____Annotations(標註文件)
| |____JPEGImages(圖像文件)
| |____ImageSets
| |____SegmentationClass
| |____SegmentationObject
|
|____VOC2012
|____Annotations(標註文件)
|____JPEGImages(圖像文件)
|____ImageSets
|____SegmentationClass
|____SegmentationObject
生成圖像列表¶
我們要編寫一個程序data/prepare_voc_data.py,把這些數據生成一個圖像列表,就像之前的圖像列表差不多,每一行對應的是圖像的路徑和標籤。這次有點不同的是對應的不是int類型的label了,是一個xml的標註文件。其部分代碼片段如下:
def prepare_filelist(devkit_dir, years, output_dir):
trainval_list = []
test_list = []
# 獲取兩個年份的數據
for year in years:
trainval, test = walk_dir(devkit_dir, year)
trainval_list.extend(trainval)
test_list.extend(test)
# 打亂訓練數據
random.shuffle(trainval_list)
# 保存訓練圖像列表
with open(os.path.join(output_dir, 'trainval.txt'), 'w') as ftrainval:
for item in trainval_list:
ftrainval.write(item[0] + ' ' + item[1] + '\n')
# 保存測試圖像列表
with open(os.path.join(output_dir, 'test.txt'), 'w') as ftest:
for item in test_list:
ftest.write(item[0] + ' ' + item[1] + '\n')
if __name__ == '__main__':
# 數據存放的位置
devkit_dir = 'VOCdevkit'
# 數據的年份
years = ['2007', '2012']
prepare_filelist(devkit_dir, years, '.')
通過上面的程序,就可以生成一個圖像列表,列表片段如下:
VOCdevkit/VOC2007/JPEGImages/000001.jpg VOCdevkit/VOC2007/Annotations/000001.xml
VOCdevkit/VOC2007/JPEGImages/000002.jpg VOCdevkit/VOC2007/Annotations/000002.xml
VOCdevkit/VOC2007/JPEGImages/000003.jpg VOCdevkit/VOC2007/Annotations/000003.xml
VOCdevkit/VOC2007/JPEGImages/000004.jpg VOCdevkit/VOC2007/Annotations/000004.xml
數據集的操作就到這裏了
數據預處理¶
在之前的文章中可以知道,訓練和測試的數據都是一個reader數據格式,所以我們要對我們的VOC數據集做一些處理。跟之前最大的不同是這次的標籤不是簡單的int或者是一個字符串,而是一個標註XML文件。而且訓練的圖像大小必須是統一大小的,但是實際的圖像的大小是不固定的,如果改變了圖像的大小,那麼圖像的標註信息就不正確了,所以對圖像的大小修改同時,也要對標註信息做對應的變化。
獲取標註信息的代碼片段:
# 保存列表的結構: label | xmin | ymin | xmax | ymax | difficult
if mode == 'train' or mode == 'test':
# 保存每個標註框
bbox_labels = []
# 開始讀取標註信息
root = xml.etree.ElementTree.parse(label_path).getroot()
# 查詢每個標註的信息
for object in root.findall('object'):
# 每個標註框的信息
bbox_sample = []
# start from 1
bbox_sample.append(
float(
settings.label_list.index(
object.find('name').text)))
bbox = object.find('bndbox')
difficult = float(object.find('difficult').text)
# 獲取標註信息,並計算比例保存
bbox_sample.append(
float(bbox.find('xmin').text) / img_width)
bbox_sample.append(
float(bbox.find('ymin').text) / img_height)
bbox_sample.append(
float(bbox.find('xmax').text) / img_width)
bbox_sample.append(
float(bbox.find('ymax').text) / img_height)
bbox_sample.append(difficult)
# 將整個框的信息保存
bbox_labels.append(bbox_sample)
獲取了標註信息並計算保存了標註信息,然後根據圖像的原始大小和標註信息的比例,可以裁剪圖像的標註信息對應的圖像。
def crop_image(img, bbox_labels, sample_bbox, image_width, image_height):
'''
裁剪圖像
:param img: 圖像
:param bbox_labels: 所有的標註信息
:param sample_bbox: 對應一個的標註信息
:param image_width: 圖像原始的寬
:param image_height: 圖像原始的高
:return:裁剪好的圖像和其對應的標註信息
'''
sample_bbox = clip_bbox(sample_bbox)
xmin = int(sample_bbox.xmin * image_width)
xmax = int(sample_bbox.xmax * image_width)
ymin = int(sample_bbox.ymin * image_height)
ymax = int(sample_bbox.ymax * image_height)
sample_img = img[ymin:ymax, xmin:xmax]
sample_labels = transform_labels(bbox_labels, sample_bbox)
return sample_img, sample_labels
然後使用這些圖像就可以使用訓練或者測試要使用的reader的了,代碼片段如下:
def reader():
img = Image.fromarray(img)
# 設置圖像大小
img = img.resize((settings.resize_w, settings.resize_h),
Image.ANTIALIAS)
img = np.array(img)
if mode == 'train':
mirror = int(random.uniform(0, 2))
if mirror == 1:
img = img[:, ::-1, :]
for i in xrange(len(sample_labels)):
tmp = sample_labels[i][1]
sample_labels[i][1] = 1 - sample_labels[i][3]
sample_labels[i][3] = 1 - tmp
if len(img.shape) == 3:
img = np.swapaxes(img, 1, 2)
img = np.swapaxes(img, 1, 0)
img = img.astype('float32')
img -= settings.img_mean
img = img.flatten()
if mode == 'train' or mode == 'test':
if mode == 'train' and len(sample_labels) == 0: continue
yield img.astype('float32'), sample_labels
elif mode == 'infer':
yield img.astype('float32')
return reader
最後通過調用PaddlePaddle的藉口就可以生成訓練和測試使用的最終reader,代碼如下:
# 創建訓練數據
train_reader = paddle.batch(
data_provider.train(data_args, train_file_list),
batch_size=cfg.TRAIN.BATCH_SIZE)
# 創建測試數據
dev_reader = paddle.batch(
data_provider.test(data_args, dev_file_list),
batch_size=cfg.TRAIN.BATCH_SIZE)
SSD神經網絡¶
SSD原理¶
SSD使用一個卷積神經網絡實現“端到端”的檢測:輸入爲原始圖像,輸出爲檢測結果,無需藉助外部工具或流程進行特徵提取、候選框生成等。論文中SSD使用VGG16作爲基礎網絡進行圖像特徵提取。但SSD對原始VGG16網絡做了一些改變:
- 將最後的fc6、fc7全連接層變爲卷積層,卷積層參數通過對原始fc6、fc7參數採樣得到。
- 將pool5層的參數由2x2-s2(kernel大小爲2x2,stride size爲2)更改爲3x3-s1-p1(kernel大小爲3x3,stride size爲1,padding size爲1)。
- 在conv4_3、conv7、conv8_2、conv9_2、conv10_2及pool11層後面接了priorbox層,priorbox層的主要目的是根據輸入的特徵圖(feature map)生成一系列的矩形候選框。
下圖爲模型(輸入圖像尺寸:300x300)的總體結構:
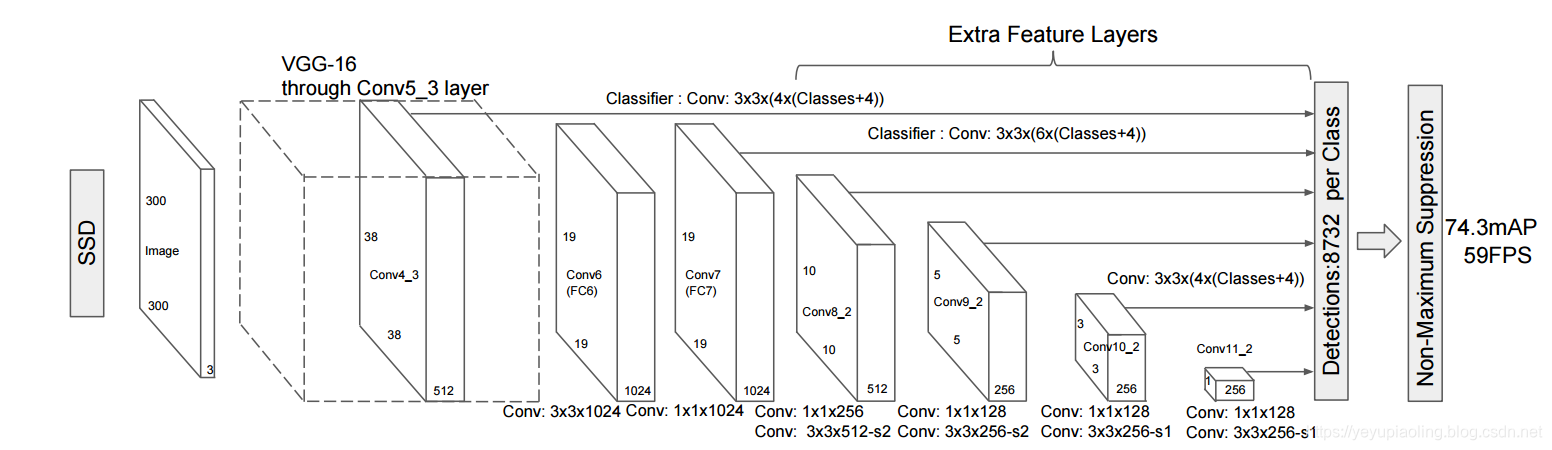
圖1. SSD 網絡結構
圖中每個矩形盒子代表一個卷積層,最後兩個矩形框分別表示彙總各卷積層輸出結果和後處理階段。在預測階段,網絡會輸出一組候選矩形框,每個矩形包含:位置和類別得分。圖中倒數第二個矩形框即表示網絡的檢測結果的彙總處理。由於候選矩形框數量較多且很多矩形框重疊嚴重,這時需要經過後處理來篩選出質量較高的少數矩形框,主要方法有非極大值抑制(Non-maximum Suppression)。
從SSD的網絡結構可以看出,候選矩形框在多個特徵圖(feature map)上生成,不同的feature map具有的感受野不同,這樣可以在不同尺度掃描圖像,相對於其他檢測方法可以生成更豐富的候選框,從而提高檢測精度;另一方面SSD對VGG16的擴展部分以較小的代價實現對候選框的位置和類別得分的計算,整個過程只需要一個卷積神經網絡完成,所以速度較快。
以上介紹摘自PaddlePaddle官網的教程
SSD代碼介紹¶
如上介紹所說,SSD使用VGG16作爲基礎網絡進行圖像特徵提取
# 卷積神經網絡
def conv_group(stack_num, name_list, input, filter_size_list, num_channels,
num_filters_list, stride_list, padding_list,
common_bias_attr, common_param_attr, common_act):
conv = input
in_channels = num_channels
for i in xrange(stack_num):
conv = paddle.layer.img_conv(
name=name_list[i],
input=conv,
filter_size=filter_size_list[i],
num_channels=in_channels,
num_filters=num_filters_list[i],
stride=stride_list[i],
padding=padding_list[i],
bias_attr=common_bias_attr,
param_attr=common_param_attr,
act=common_act)
in_channels = num_filters_list[i]
return conv
# VGG神經網絡
def vgg_block(idx_str, input, num_channels, num_filters, pool_size,
pool_stride, pool_pad):
layer_name = "conv%s_" % idx_str
stack_num = 3
name_list = [layer_name + str(i + 1) for i in xrange(3)]
conv = conv_group(stack_num, name_list, input, [3] * stack_num,
num_channels, [num_filters] * stack_num,
[1] * stack_num, [1] * stack_num, default_bias_attr,
get_param_attr(1, default_l2regularization),
paddle.activation.Relu())
pool = paddle.layer.img_pool(
input=conv,
pool_size=pool_size,
num_channels=num_filters,
pool_type=paddle.pooling.CudnnMax(),
stride=pool_stride,
padding=pool_pad)
return conv, pool
將最後的fc6、fc7全連接層變爲卷積層,卷積層參數通過對原始fc6、fc7參數採樣得到:
fc7 = conv_group(stack_num, ['fc6', 'fc7'], pool5, [3, 1], 512, [1024] *
stack_num, [1] * stack_num, [1, 0], default_bias_attr,
get_param_attr(1, default_l2regularization),
paddle.activation.Relu())
將pool5層的參數由2x2-s2(kernel大小爲2x2,stride size爲2)更改爲3x3-s1-p1(kernel大小爲3x3,stride size爲1,padding size爲1):
def mbox_block(layer_idx, input, num_channels, filter_size, loc_filters,
conf_filters):
mbox_loc_name = layer_idx + "_mbox_loc"
mbox_loc = paddle.layer.img_conv(
name=mbox_loc_name,
input=input,
filter_size=filter_size,
num_channels=num_channels,
num_filters=loc_filters,
stride=1,
padding=1,
bias_attr=default_bias_attr,
param_attr=get_param_attr(1, default_l2regularization),
act=paddle.activation.Identity())
mbox_conf_name = layer_idx + "_mbox_conf"
mbox_conf = paddle.layer.img_conv(
name=mbox_conf_name,
input=input,
filter_size=filter_size,
num_channels=num_channels,
num_filters=conf_filters,
stride=1,
padding=1,
bias_attr=default_bias_attr,
param_attr=get_param_attr(1, default_l2regularization),
act=paddle.activation.Identity())
return mbox_loc, mbox_conf
最後要獲取到訓練和預測使用到的損失函數和檢查輸出層
if mode == 'train' or mode == 'eval':
bbox = paddle.layer.data(
name='bbox', type=paddle.data_type.dense_vector_sequence(6))
loss = paddle.layer.multibox_loss(
input_loc=loc_loss_input,
input_conf=conf_loss_input,
priorbox=mbox_priorbox,
label=bbox,
num_classes=cfg.CLASS_NUM,
overlap_threshold=cfg.NET.MBLOSS.OVERLAP_THRESHOLD,
neg_pos_ratio=cfg.NET.MBLOSS.NEG_POS_RATIO,
neg_overlap=cfg.NET.MBLOSS.NEG_OVERLAP,
background_id=cfg.BACKGROUND_ID,
name="multibox_loss")
paddle.evaluator.detection_map(
input=detection_out,
label=bbox,
overlap_threshold=cfg.NET.DETMAP.OVERLAP_THRESHOLD,
background_id=cfg.BACKGROUND_ID,
evaluate_difficult=cfg.NET.DETMAP.EVAL_DIFFICULT,
ap_type=cfg.NET.DETMAP.AP_TYPE,
name="detection_evaluator")
return loss, detection_out
elif mode == 'infer':
return detection_out
關於SSD神經網絡介紹就到這裏,如果讀者想跟詳細瞭解SSD神經網絡,可以閱讀SSD的論文 SSD: Single shot multibox detector
訓練模型¶
訓練流程圖¶
訓練的流程圖:
flowchat
st=>start: 開始
e=>end: 結束
get_trainer=>operation: 創建訓練器
start_trainer=>operation: 開始訓練
st->get_trainer->start_trainer->e
創建訓練器¶
創建訓練器,代碼片段如下:
# 創建優化方法
optimizer = paddle.optimizer.Momentum(
momentum=cfg.TRAIN.MOMENTUM,
learning_rate=cfg.TRAIN.LEARNING_RATE,
regularization=paddle.optimizer.L2Regularization(
rate=cfg.TRAIN.L2REGULARIZATION),
learning_rate_decay_a=cfg.TRAIN.LEARNING_RATE_DECAY_A,
learning_rate_decay_b=cfg.TRAIN.LEARNING_RATE_DECAY_B,
learning_rate_schedule=cfg.TRAIN.LEARNING_RATE_SCHEDULE)
# 通過神經網絡模型獲取損失函數和額外層
cost, detect_out = vgg_ssd_net.net_conf('train')
# 通過損失函數創建訓練參數
parameters = paddle.parameters.create(cost)
# 如果有訓練好的模型,可以使用訓練好的模型再訓練
if not (init_model_path is None):
assert os.path.isfile(init_model_path), 'Invalid model.'
parameters.init_from_tar(gzip.open(init_model_path))
# 創建訓練器
trainer = paddle.trainer.SGD(cost=cost,
parameters=parameters,
extra_layers=[detect_out],
update_equation=optimizer)
開始訓練¶
有了訓練器,我們纔可以開始訓練。如果單純讓它訓練,沒做一些數據保存處理,這種訓練是沒有意義的,所以我們要定義一個訓練事件,讓它在訓練過程中保存我們需要的模型參數,同時輸出一些日誌信息,方便我們查看訓練的效果,訓練事件的代碼片段:
# 定義訓練事件
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 1 == 0:
print "\nPass %d, Batch %d, TrainCost %f, Detection mAP=%f" % \
(event.pass_id,
event.batch_id,
event.cost,
event.metrics['detection_evaluator'])
else:
sys.stdout.write('.')
sys.stdout.flush()
if isinstance(event, paddle.event.EndPass):
with gzip.open('../models/params_pass.tar.gz', 'w') as f:
trainer.save_parameter_to_tar(f)
result = trainer.test(reader=dev_reader, feeding=feeding)
print "\nTest with Pass %d, TestCost: %f, Detection mAP=%g" % \
(event.pass_id,
result.cost,
result.metrics['detection_evaluator'])
最後就可以進行訓練了,訓練的代碼爲:
# 開始訓練
trainer.train(
reader=train_reader,
event_handler=event_handler,
num_passes=cfg.TRAIN.NUM_PASS,
feeding=feeding)
具體調用方法如下,train_file_list爲訓練數據;dev_file_list爲測試數據;data_args爲數據集的設置;init_model_path爲初始化模型參數,在第三章CIFAR彩色圖像識別我們就談到SSD神經網絡很容易發生浮點異常,所以我們要一個預訓練的模型來提供初始化訓練參數,筆者使用的是PaddlePaddle官方提供的預訓練的模型:
if __name__ == "__main__":
# 初始化PaddlePaddle
paddle.init(use_gpu=True, trainer_count=2)
# 設置數據參數
data_args = data_provider.Settings(
data_dir='../data',
label_file='../data/label_list',
resize_h=cfg.IMG_HEIGHT,
resize_w=cfg.IMG_WIDTH,
mean_value=[104, 117, 124])
# 開始訓練
train(
train_file_list='../data/trainval.txt',
dev_file_list='../data/test.txt',
data_args=data_args,
init_model_path='../models/vgg_model.tar.gz')
在訓練過程中會輸出以下訓練日誌:
Pass 0, Batch 0, TrainCost 17.445816, Detection mAP=0.000000
...................................................................................................
Pass 0, Batch 100, TrainCost 8.544815, Detection mAP=2.871136
...................................................................................................
Pass 0, Batch 200, TrainCost 7.434404, Detection mAP=3.337185
...................................................................................................
Pass 0, Batch 300, TrainCost 7.404398, Detection mAP=7.070700
...................................................................................................
Pass 0, Batch 400, TrainCost 7.023655, Detection mAP=3.080483
評估模型¶
我們訓練好的模型之後,在使用模式進行預測,可以對模型進行評估。評估模型的方法跟訓練是使用到的Test是一樣的,只是我們專門把它提取處理,用於評估模型而已。
同樣是要先創建訓練器,代碼片段如下:
# 通過神經網絡模型獲取損失函數和額外層
cost, detect_out = vgg_ssd_net.net_conf(mode='eval')
# 檢查模型模型路徑是否正確
assert os.path.isfile(model_path), 'Invalid model.'
# 通過訓練好的模型生成參數
parameters = paddle.parameters.Parameters.from_tar(gzip.open(model_path))
# 創建優化方法
optimizer = paddle.optimizer.Momentum()
# 創建訓練器
trainer = paddle.trainer.SGD(cost=cost,
parameters=parameters,
extra_layers=[detect_out],
update_equation=optimizer)
然後是去掉訓練過程,只留下Test部分,所得的代碼片段如下:
# 定義數據層之間的關係
feeding = {'image': 0, 'bbox': 1}
# 生成要訓練的數據
reader = paddle.batch(
data_provider.test(data_args, eval_file_list), batch_size=batch_size)
# 獲取測試結果
result = trainer.test(reader=reader, feeding=feeding)
# 打印模型的測試信息
print "TestCost: %f, Detection mAP=%g" % \
(result.cost, result.metrics['detection_evaluator'])
具體調用方法如下,可以看到使用的的數據集還是我們在訓練時候使用到的測試數據:
if __name__ == "__main__":
paddle.init(use_gpu=True, trainer_count=2)
# 設置數據參數
data_args = data_provider.Settings(
data_dir='../data',
label_file='../data/label_list',
resize_h=cfg.IMG_HEIGHT,
resize_w=cfg.IMG_WIDTH,
mean_value=[104, 117, 124])
# 開始評估
eval(eval_file_list='../data/test.txt',
batch_size=4,
data_args=data_args,
model_path='../models/params_pass.tar.gz')
評估模型輸出的日誌如下:
TestCost: 7.185788, Detection mAP=1.07462
預測數據¶
預測並保存預測結果¶
獲得模型參數之後,就可以使用它來做目標檢測了,比如我們要把下面這張圖像做目標檢測:

預測的代碼片段如下:
# 通過網絡模型獲取輸出層
detect_out = vgg_ssd_net.net_conf(mode='infer')
# 檢查模型路徑是否正確
assert os.path.isfile(model_path), 'Invalid model.'
# 加載訓練好的參數
parameters = paddle.parameters.Parameters.from_tar(gzip.open(model_path))
# 或預測器
inferer = paddle.inference.Inference(
output_layer=detect_out, parameters=parameters)
# 獲取預測數據
reader = data_provider.infer(data_args, eval_file_list)
all_fname_list = [line.strip() for line in open(eval_file_list).readlines()]
# 獲取預測原始結果
infer_res = inferer.infer(input=infer_data)
獲得預測結果之後,我們可以將預測的結果保存的一個文件中,保存這些文件方便之後使用這些數據:
# 獲取圖像的idx
img_idx = int(det_res[0])
# 獲取圖像的label
label = int(det_res[1])
# 獲取預測的得分
conf_score = det_res[2]
# 獲取目標的框
xmin = det_res[3] * img_w[img_idx]
ymin = det_res[4] * img_h[img_idx]
xmax = det_res[5] * img_w[img_idx]
ymax = det_res[6] * img_h[img_idx]
# 將預測結果寫入到文件中
fout.write(fname_list[img_idx] + '\t' + str(label) + '\t' + str(
conf_score) + '\t' + str(xmin) + ' ' + str(ymin) + ' ' + str(xmax) +
' ' + str(ymax))
fout.write('\n')
具體調用方法,eval_file_list是要預測的數據的路徑文件,save_path保存預測結果的路徑,resize_h和resize_w指定圖像的寬和高,batch_size只能設置爲1,否則會數據丟失,model_path模型的路徑,threshold是篩選最低得分。
if __name__ == "__main__":
paddle.init(use_gpu=True, trainer_count=2)
# 設置數據參數
data_args = data_provider.Settings(
data_dir='../images',
label_file='../data/label_list',
resize_h=cfg.IMG_HEIGHT,
resize_w=cfg.IMG_WIDTH,
mean_value=[104, 117, 124])
# 開始預測,batch_size只能設置爲1,否則會數據丟失
infer(
eval_file_list='../images/infer.txt',
save_path='../images/infer.res',
data_args=data_args,
batch_size=1,
model_path='../models/params_pass.tar.gz',
threshold=0.3)
預測的結果會保存在images/infer.res中,每一行對應的是一個目標框,格式爲:圖像的路徑 分類的標籤 目標框的得分 xmin ymin xmax ymax,每個圖像可以有多個類別,所以會有多個框。
infer/00001.jpg 7 0.7000513 287.25091552734375 265.18829345703125 599.12451171875 539.6732330322266
infer/00002.jpg 7 0.53912574 664.7453212738037 240.53946733474731 1305.063714981079 853.0169785022736
infer/00002.jpg 11 0.6429965 551.6539978981018 204.59033846855164 1339.9816703796387 843.807926774025
infer/00003.jpg 12 0.7647844 133.20248904824257 45.33928334712982 413.9954067468643 266.06680154800415
infer/00004.jpg 12 0.66517526 117.327481508255 251.13083073496819 550.8465766906738 665.4091544151306
顯示畫出的框¶
有了以上的預測文件,並不能很直觀看到預測的結果,我們可以編寫一個程序,讓它在原圖像上畫上預測出來的框,這樣就更直接看到結果了。核心代碼如下:
# 讀取每張圖像
for img_path in all_img_paht:
im = cv2.imread('../images/' + img_path)
# 爲每張圖像畫上所有的框
for label_1 in all_labels:
label_img_path = label_1[0]
# 判斷是否是統一路徑
if img_path == label_img_path:
xmin, ymin, xmax, ymax = label_1[3].split(' ')
# 類型轉換
xmin = float(xmin)
ymin = float(ymin)
xmax = float(xmax)
ymax = float(ymax)
# 畫框
cv2.rectangle(im, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (0, 255, 0), 3)
# 保存畫好的圖像
names = img_path.strip().split('/')
name = names[len(names)-1]
cv2.imwrite('../images/result/%s' % name, im)
最後通過在入口調用該方法就可以,代碼如下:
if __name__ == '__main__':
# 預測的圖像路徑文件
img_path_list = '../images/infer.txt'
# 預測結果的文件路徑
result_data_path = '../images/infer.res'
# 保存畫好的圖像路徑
save_path = '../images/result'
show(img_path_list, result_data_path, save_path)
畫好的圖像如下:

上一章:《我的PaddlePaddle學習之路》筆記八——場景文字識別¶
下一章:《我的PaddlePaddle學習之路》筆記十——自定義圖像數據集實現目標檢測¶
項目代碼¶
GitHub地址:https://github.com/yeyupiaoling/LearnPaddle
參考資料¶
- http://paddlepaddle.org/
- https://github.com/PaddlePaddle/models/tree/develop/ssd
- https://zhuanlan.zhihu.com/p/22045213
- https://arxiv.org/abs/1512.02325