Introduction¶
MediaPipe is an open-source framework developed by Google for building perception pipelines to process time-series data such as video and audio. Among its components, MediaPipe Hands is a high-performance hand keypoint detection solution capable of real-time hand keypoint detection on mobile devices. This project primarily uses MediaPipe Model Maker to train a custom gesture recognition model, supporting recognition of multiple gestures including Rock, Paper, Scissors, and No Gesture. The project provides a complete training and inference workflow, supporting both image and video inference modes for real-time gesture detection and recognition.
Environment:
- Python 3.11
- TensorFlow 2.15.1
- MediaPipe 0.10.21
- Ubuntu 22.04
Project Overview¶
train.py: Trains a custom gesture recognition model.infer.py: Performs gesture recognition inference using the trained model, supporting both image and video modes.utils.py: Utility functions including drawing hand landmarks and displaying gesture information.models/: Directory for storing pre-trained and custom-trained models.dataset/: Directory for training datasets, containing image data for different gestures.
Environment Setup¶
- First, install a Python environment, Python 3.8 or higher is recommended.
- Install required dependencies:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
Data Preparation¶
Training data is stored in the dataset/images/ directory, with subdirectories for different gesture types. Custom datasets can be placed here; create additional folders as needed. Each subdirectory contains images of one gesture:
dataset/
- images/
- rock/ # Images of Rock gesture
- paper/ # Images of Paper gesture
- scissors/ # Images of Scissors gesture
- none/ # No Gesture/background images
It is recommended to prepare 100-200 images per gesture type under varying angles and lighting conditions to enhance the model’s generalization ability. Supported image formats include common types like jpg and png.
Model Training¶
Once the data is prepared, training the custom gesture recognition model can begin. The training program automatically reads the dataset and uses MediaPipe Model Maker for training.
Training Parameters¶
Adjust the following key parameters in train.py:
- learning_rate: Learning rate, default 0.001
- batch_size: Batch size, default 2
- epochs: Number of training epochs, default 10
- shuffle: Whether to shuffle data, default True
Starting Training¶
Sample training code:
from mediapipe_model_maker import gesture_recognizer
# Load dataset
data = gesture_recognizer.Dataset.from_folder(
dirname="dataset/images",
hparams=gesture_recognizer.HandDataPreprocessingParams()
)
# Data splitting
train_data, rest_data = data.split(0.8)
validation_data, test_data = rest_data.split(0.5)
# Training parameters
hparams = gesture_recognizer.HParams(
learning_rate=0.001,
batch_size=2,
epochs=10,
shuffle=True
)
# Train model
model = gesture_recognizer.GestureRecognizer.create(
train_data=train_data,
validation_data=validation_data,
options=gesture_recognizer.GestureRecognizerOptions(hparams=hparams)
)
# Evaluation and export
loss, acc = model.evaluate(test_data, batch_size=1)
model.export_model(model_name="custom_gesture_recognizer.task")
Full code is in train.py. Run with:
python train.py
During training, progress and loss values will be displayed:
Label list: ['none', 'paper', 'rock', 'scissors']
Model checkpoint saved at exported_model/checkpoint
Training finished.
Test loss:0.123, Test accuracy:0.95
After training, the model is automatically saved to models/custom_gesture_recognizer.task.
Model Inference¶
The project supports two inference modes: image inference and video inference.
Image Inference¶
For single-image gesture recognition, the code snippet is:
import cv2
import mediapipe as mp
from utils import draw_landmarks_and_connections, draw_gesture_info, HAND_CONNECTIONS
# Initialize gesture recognizer
BaseOptions = mp.tasks.BaseOptions
GestureRecognizer = mp.tasks.vision.GestureRecognizer
GestureRecognizerOptions = mp.tasks.vision.GestureRecognizerOptions
VisionRunningMode = mp.tasks.vision.RunningMode
options = GestureRecognizerOptions(
base_options=BaseOptions(model_asset_path='models/custom_gesture_recognizer.task'),
num_hands=2,
running_mode=VisionRunningMode.IMAGE)
with GestureRecognizer.create_from_options(options) as recognizer:
# Read image
mp_image = mp.Image.create_from_file('test.jpg')
result = recognizer.recognize(mp_image)
# Output results
for i in range(len(result.gestures)):
print(f"Gesture {i + 1}: {result.gestures[i][0].category_name}, Confidence: {result.gestures[i][0].score:.1%}")
Full code in infer.py. Run with:
python infer.py
Default configuration is image mode, processing test2.jpg. Modify parameters in infer.py:
- mode: Set to “image”
- model_asset_path: Model path (official or custom)
- show_image_or_video: Whether to display results
Video Inference¶
For real-time video stream gesture recognition:
# Set mode to "video" in infer.py
python infer.py
Video mode parameters:
- mode: Set to “video”
- video_path_or_id: Video file path or camera ID (0 for default camera)
- show_image_or_video: Whether to display the real-time video window
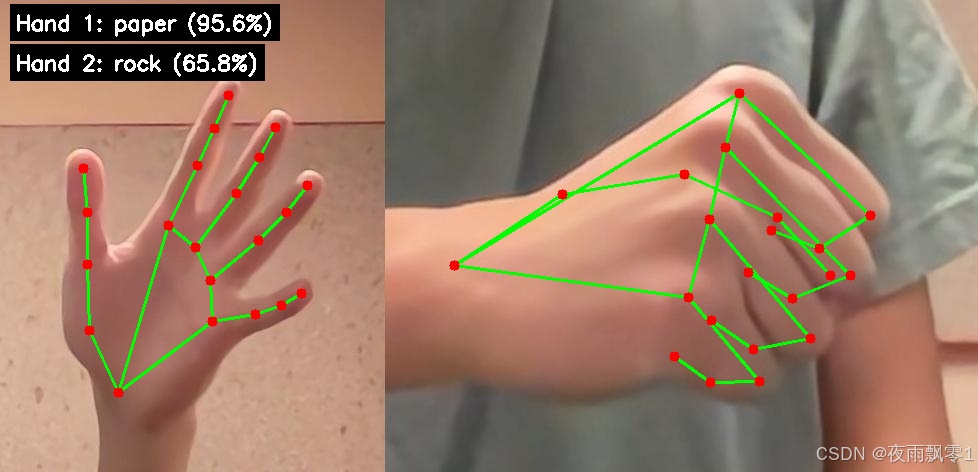
Inference Output¶
Inference results will be printed:
Gesture 1: rock, Confidence: 95.2%
Gesture 2: scissors, Confidence: 87.1%
Result image saved as result_with_landmarks.jpg
Hand landmarks and recognition results are drawn on the image.
Source Code Download¶
Reply “MediaPipe Custom Gesture Recognition Training Model” in the WeChat official account to obtain the source code.