# 前言
之前的文章紹一個準確率非常高的語音識別框架,但那個只能識別即時的短音頻,如果想要識別一個非常長的音頻,幾十分鐘,甚至幾個小時,那之前的那個是做不到的所以就有了本文。本文介紹搭建一個長語音識別服務,可以把任意長度的音視頻到識別結果。而且識別結果中,可以包含每句話的開始時間和結束時間,可以用來做字幕等等。
視頻教程: 三行命令搭建語音識別服務,竟如此輕鬆識別幾個小時的音視頻!
啓動Docker服務¶
需要把整個文件夾上傳到服務器上,並在該目錄執行以下命令:
編譯Docker容器:
sudo docker build -t offline_asr .
修改權限:
sudo chmod +x run_server.sh
在項目根目錄執行啓動命令:
sudo docker run -p 10095:10095 -itd --privileged=true --name offline_asr -v $PWD/:/workspace/websocket offline_asr
重新啓動服務,如果之前因爲一些原因關閉了docker服務,可以執行下面命令重新啓動,需要開機自啓動的,把下面命令複製到開機自啓動腳本中/etc/rc.local:
sudo docker start offline_asr
測試服務¶
使用上面服務之後,可以執行下面命令測試一下服務是否正常啓動可用。
python client.py --wav_path=test.wav
輸出結果如下,可以看到輸出的結果中,每句話都帶有開始和結束的時間戳,單位毫秒:
【../data/test.wav】結果: [{'text': '近幾年,', 'start': '710', 'end': '1569'}, {'text': '不但我用書給女兒壓歲,', 'start': '1569', 'end': '3550'}, {'text': '也勸說親朋不要給女兒壓歲錢而改送壓歲書。', 'start': '3550', 'end': '7935'}]
搭建HTTP服務¶
上面搭建的是websocket的服務,使用起來非常不方便,所以下面提供了一個Websockt轉http服務的程序,並且提供了網頁可以上傳音視頻獲取識別結果,啓動HTTP服務命令如下。
python server.py
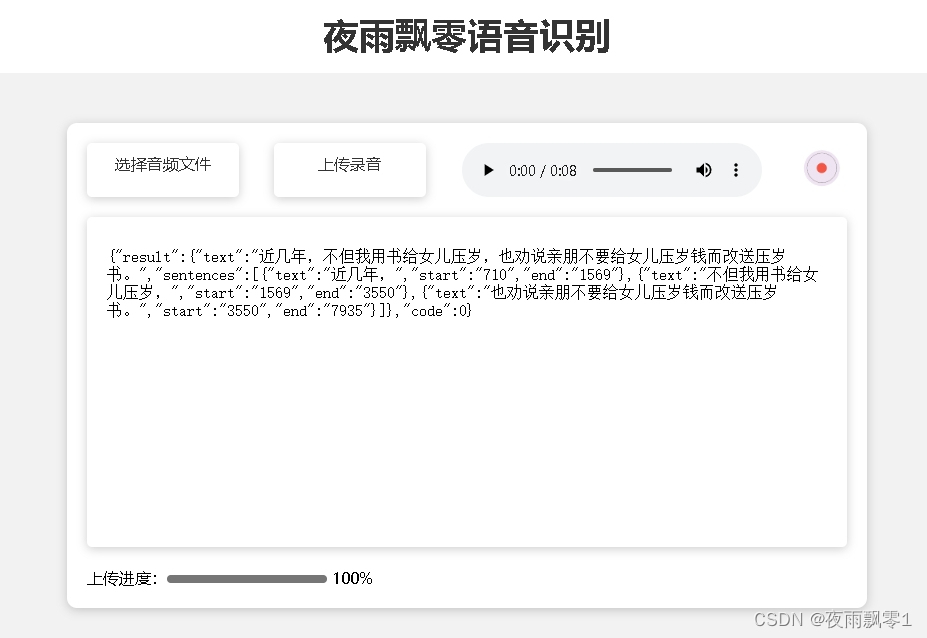
訪問http://192.168.0.100:6060打開頁面,可以上傳WAV、MP3、MP4等多種格式,同時也支持錄製識別,返回的同樣是每句話都有時間戳。
{
"result": {
"text": "近幾年,不但我用書給女兒壓歲,也勸說親朋不要給女兒壓歲錢而改送壓歲書。",
"sentences": [
{
"text": "近幾年,",
"start": "710",
"end": "1569"
},
{
"text": "不但我用書給女兒壓歲,",
"start": "1569",
"end": "3550"
},
{
"text": "也勸說親朋不要給女兒壓歲錢而改送壓歲書。",
"start": "3550",
"end": "7935"
}
]
},
"code": 0
}
頁面截圖:
掃碼入知識星球,搜索【FunASR語音識別長音頻視頻服務】獲取源碼