# 前言
本文將介紹一個基於FunASR開發的語音識別界面應用,這個應用可以選擇本地音頻,也可以錄音識別。支持多種音頻格式和視頻格式,可以對識別的結果加上時間戳做成字幕。
安裝環境¶
- 安裝Pytorch,根據自己機器的情況可以選擇安裝CPU版本或者GPU版本的Pytorch。
# 安裝CPU版本的Pytorch
conda install pytorch torchvision torchaudio cpuonly -c pytorch
# 安裝GPU版本的Pytorch
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
- 安裝ffmpeg和pyaudio。
conda install ffmpeg pyaudio
- 安裝其他依賴庫。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
使用¶
執行main.py即可啓動程序,一共有四個功能,分別是短語音識別、長語音識別、錄音識別、播放音頻。
- 短音頻識別,可以選擇一個較短的音頻或者視頻,便可得到結果,這個長度沒有固定的限制,一般把小於30秒或者50秒的作爲短音頻。
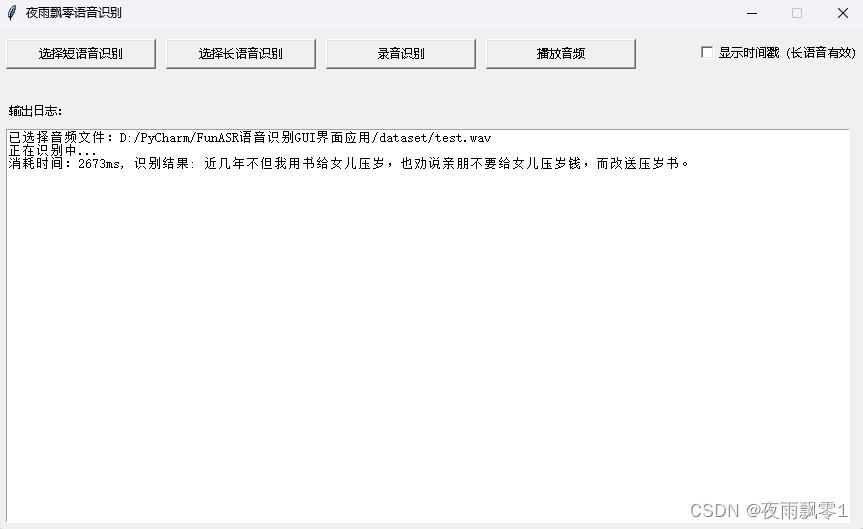
- 長音頻識別,長音頻識別有兩種模型,第一種是不添加時間戳的,全部結果拼接起來。長音頻識別的方式其實就是使用VAD模型把長音頻裁剪成多段的短音頻,然後再識別的。
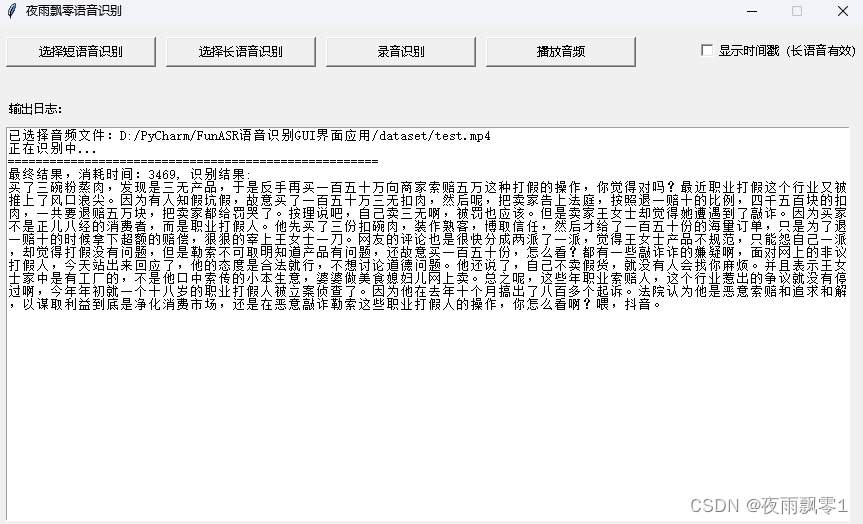
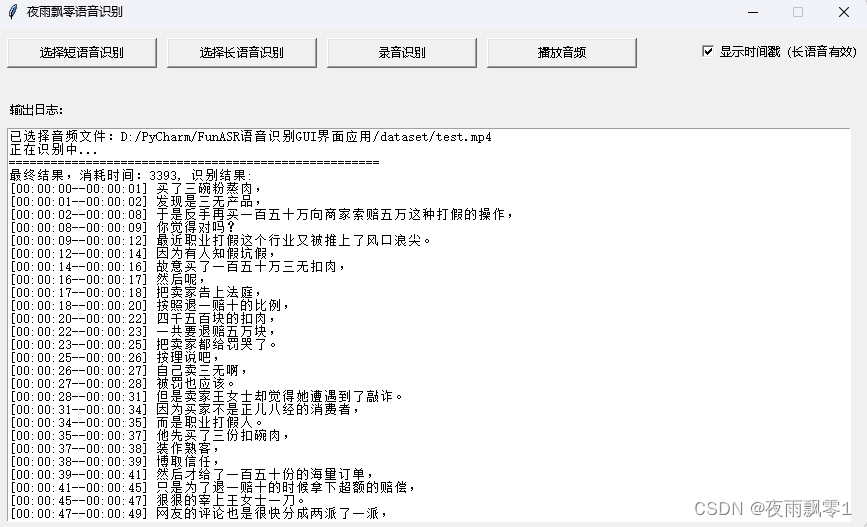
-
長音頻識別(時間戳),第二種是顯示時間戳,可以知道每句話開始的時間和結束的時間,可以用於製作字幕。
-
錄音識別,錄音識別是一邊說話一邊出結果,這種識別方式是流式的。當點擊停止錄音之後,是使用全部的錄音再次執行識別,提高最終的準確率。
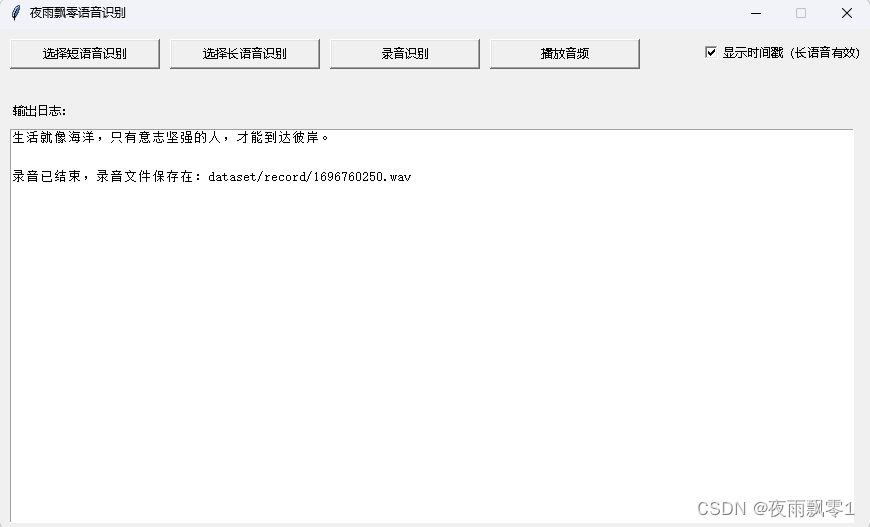
-
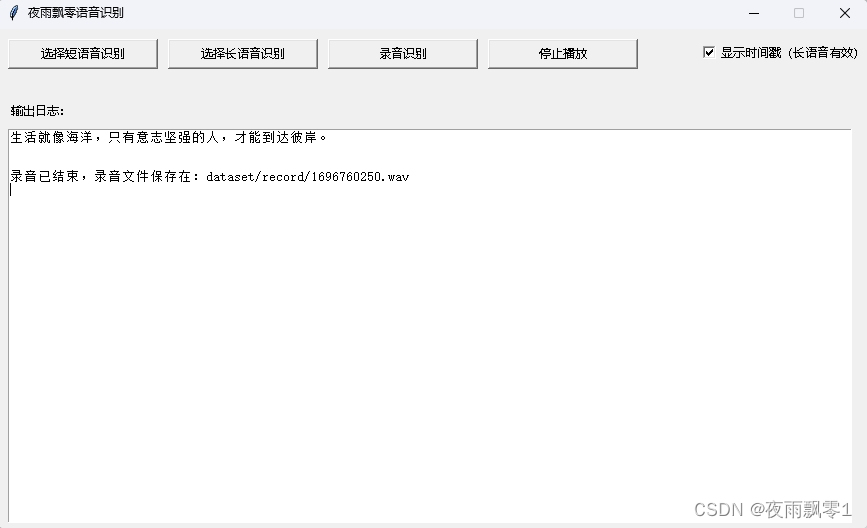
播放音頻,當選擇了音頻或者錄音識別了,可以點擊播放音頻按鈕播放音頻,只能播放音頻格式,不支持播放視頻格式。
掃碼入知識星球,搜索【FunASR語音識別GUI界面應用】獲取源碼