前言¶
CrowdNet模型是2016年提出的人流密度估計模型,論文爲《CrowdNet: A Deep Convolutional Network for DenseCrowd Counting》,CrowdNet模型主要有深層卷積神經網絡和淺層卷積神經組成,通過輸入原始圖像和高斯濾波器得到的密度圖進行訓練,最終得到的模型估計圖像中的行人的數量。當然這不僅僅可以用於人流密度估計,理論上其他的動物等等的密度估計應該也可以。
項目開源地址: https://github.com/yeyupiaoling/PaddlePaddle-CrowdNet.git
本項目開發環境爲:
- Windows 10
- Python 3.7
- PaddlePaddle 2.0.0a0
CrowdNet模型實現¶
以下是CrowdNet模型的結構圖,從結構圖中可以看出,CrowdNet模型是深層卷積網絡(Deep Network)和淺層卷積網絡(Shallow Network)組成,兩組網絡通過拼接成一個網絡,接着輸入到一個卷積核數量和大小都是1的卷積層,最後通過插值方式得到一個密度圖數據,通過統計這個密度就可以得到估計人數
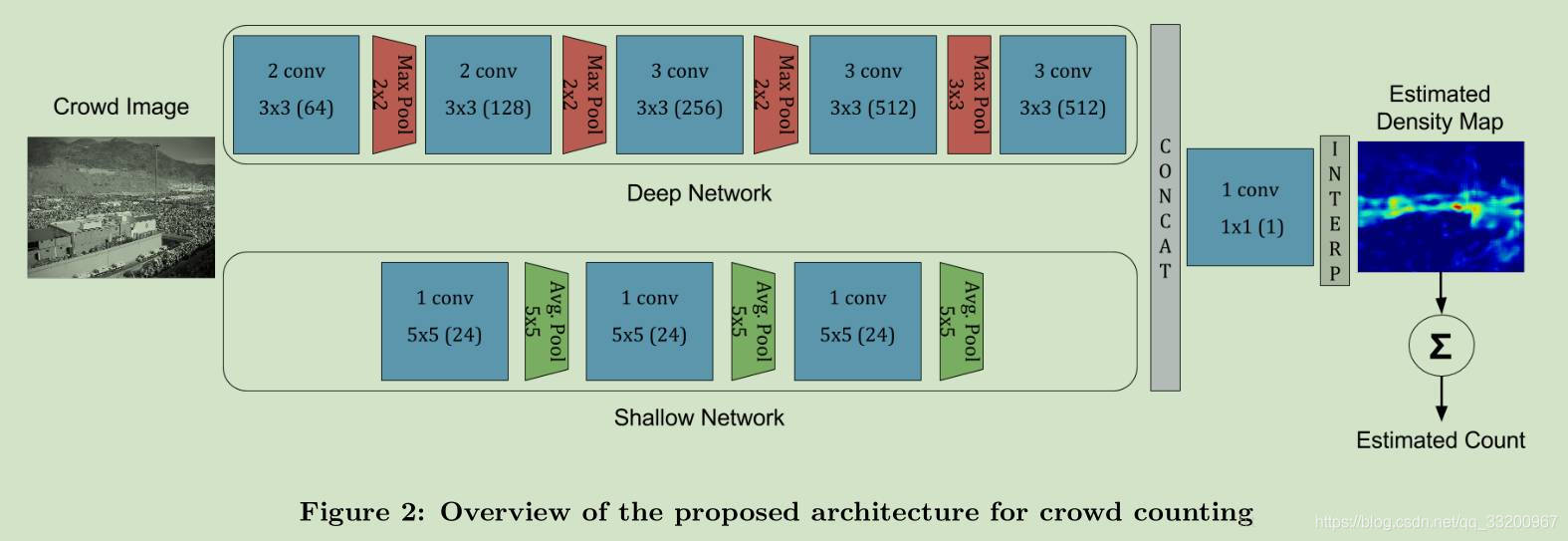
在PaddlePaddle中,通過以下代碼判斷即可實現上面的CrowdNet模型,在深層卷積網絡和淺層卷積網絡的卷積層都使用conv_bn卷積層,這個是通過把卷積層和batch_norm組合在一起的。在本項目中,輸入的圖像大小[3, 640, 480],密度圖大小爲[1, 80, 60],所以深層卷積網絡輸出的shape爲[512, 80, 60],淺層神經網絡的輸出爲[24, 80, 60]。兩個網絡的輸出通過fluid.layers.concat()接口進行拼接,拼接後輸入到fluid.layers.conv2d(),最後通過fluid.layers.resize_bilinear() 雙向性插值法輸出一個密度圖,最後使用的fluid.layers.reduce_sum()是爲了方便在預測時直接輸出估計人數。
def deep_network(img):
x = img
x = conv_bn(input=x, num_filters=64, filter_size=3, padding=1, act='relu')
x = conv_bn(input=x, num_filters=64, filter_size=3, padding=1, act='relu')
x = fluid.layers.pool2d(input=x, pool_size=2, pool_stride=2)
x = fluid.layers.dropout(x=x, dropout_prob=0.25)
x = conv_bn(input=x, num_filters=128, filter_size=3, padding=1, act='relu')
x = conv_bn(input=x, num_filters=128, filter_size=3, padding=1, act='relu')
x = fluid.layers.pool2d(input=x, pool_size=2, pool_stride=2)
x = fluid.layers.dropout(x=x, dropout_prob=0.25)
x = conv_bn(input=x, num_filters=256, filter_size=3, padding=1, act='relu')
x = conv_bn(input=x, num_filters=256, filter_size=3, padding=1, act='relu')
x = conv_bn(input=x, num_filters=256, filter_size=3, padding=1, act='relu')
x = fluid.layers.pool2d(input=x, pool_size=2, pool_stride=2)
x = fluid.layers.dropout(x=x, dropout_prob=0.5)
x = conv_bn(input=x, num_filters=512, filter_size=3, padding=1, act='relu')
x = conv_bn(input=x, num_filters=512, filter_size=3, padding=1, act='relu')
x = conv_bn(input=x, num_filters=512, filter_size=3, padding=1, act='relu')
x = fluid.layers.pool2d(input=x, pool_size=3, pool_stride=1, pool_padding=1)
x = conv_bn(input=x, num_filters=512, filter_size=3, padding=1, act='relu')
x = conv_bn(input=x, num_filters=512, filter_size=3, padding=1, act='relu')
x = conv_bn(input=x, num_filters=512, filter_size=3, padding=1)
x = fluid.layers.dropout(x=x, dropout_prob=0.5)
return x
def shallow_network(img):
x = img
x = conv_bn(input=x, num_filters=24, filter_size=5, padding=3, act='relu')
x = fluid.layers.pool2d(input=x, pool_size=5, pool_type='avg', pool_stride=2)
x = conv_bn(input=x, num_filters=24, filter_size=5, padding=3, act='relu')
x = fluid.layers.pool2d(input=x, pool_size=5, pool_type='avg', pool_stride=2)
x = conv_bn(input=x, num_filters=24, filter_size=5, padding=4, act='relu')
x = fluid.layers.pool2d(input=x, pool_size=5, pool_type='avg', pool_stride=2)
return x
# 創建CrowdNet網絡模型
net_out1 = deep_network(images)
net_out2 = shallow_network(images)
concat_out = fluid.layers.concat([net_out1, net_out2], axis=1)
conv_end = fluid.layers.conv2d(input=concat_out, num_filters=1, filter_size=1)
# 雙向性插值
map_out = fluid.layers.resize_bilinear(conv_end, out_shape=(80, 60))
# 避開Batch維度求和
sum_ = fluid.layers.reduce_sum(map_out, dim=[1, 2, 3])
sum_ = fluid.layers.reshape(sum_, [-1, 1])
通過上面實現的CrowdNet模型,它的結構如下圖所示:

訓練模型¶
本項目使用的是百度公開的一個人流密度數據集,數據集下載鏈接:https://aistudio.baidu.com/aistudio/datasetdetail/1917,下載之後,執行下面操作:
- 把train.json文件存放在data目錄
- 把test_new.zip解壓到data目錄
- 把train_new.zip解壓到data目錄
本項目提供了一個腳本create_list.py可以把百度公開的數據集數據標準文件生成本項目所需要的標註格式,通過執行腳本可以生成類似以下格式的數據列表,每一行的前面是圖像路徑,後面的是人的座標點,中間用製表符\t分開。如果開發者要訓練自己的數據集,將圖像標註數據生成以下格式即可。
data/train/4c93da45f7dc854a31a4f75b1ee30056.jpg [(171, 200), (365, 144), (306, 155), (451, 204), (436, 252), (600, 235)]
data/train/3a8c1ed636145f23e2c5eafce3863bb2.jpg [(788, 205), (408, 250), (115, 233), (160, 261), (226, 225), (329, 161)]
data/train/075ed038030094f43f5e7b902d41d223.jpg [(892, 646), (826, 763), (845, 75), (896, 260), (773, 752)]
模型的輸入標籤是一個密度圖,那麼如何通過標註數據生成一個密度圖的,下面就來簡單介紹一下。其實就是一些不同核的高斯濾波器生成的,得到的一個比輸入圖像小8倍的密度圖。
import json
import numpy as np
import scipy
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib import cm as CM
import scipy
import scipy.spatial
from PIL import Image
from scipy.ndimage.filters import gaussian_filter
import os
# 圖片預處理
def picture_opt(img, ann):
# 縮放的圖像大小
train_img_size = (640, 480)
gt = []
size_x, size_y = img.size
img = img.resize(train_img_size, Image.ANTIALIAS)
for b_l in range(len(ann)):
x = ann[b_l][0]
y = ann[b_l][1]
x = (x * train_img_size[0] / size_x) / 8
y = (y * train_img_size[1] / size_y) / 8
gt.append((x, y))
img = np.array(img) / 255.0
return img, gt
# 高斯濾波
def gaussian_filter_density(gt):
density = np.zeros(gt.shape, dtype=np.float32)
gt_count = np.count_nonzero(gt)
if gt_count == 0:
return density
pts = np.array(list(zip(np.nonzero(gt)[1].ravel(), np.nonzero(gt)[0].ravel())))
tree = scipy.spatial.KDTree(pts.copy(), leafsize=2048)
distances, locations = tree.query(pts, k=4)
for i, pt in enumerate(pts):
pt2d = np.zeros(gt.shape, dtype=np.float32)
pt2d[pt[1], pt[0]] = 1.
if gt_count > 1:
sigma = (distances[i][1] + distances[i][2] + distances[i][3]) * 0.1
else:
sigma = np.average(np.array(gt.shape)) / 2. / 2.
density += scipy.ndimage.filters.gaussian_filter(pt2d, sigma, mode='constant')
return density
# 密度圖處理
def ground(img, gt):
imgs = img
x = imgs.shape[0] / 8
y = imgs.shape[1] / 8
k = np.zeros((int(x), int(y)))
for i in range(0, len(gt)):
if int(gt[i][1]) < int(x) and int(gt[i][0]) < int(y):
k[int(gt[i][1]), int(gt[i][0])] = 1
img_sum = np.sum(k)
k = gaussian_filter_density(k)
return k, img_sum
讀取一張圖片,並經過縮放預處理,在這裏圖像沒有經過裝置,但是在訓練過程中需要對圖像執行裝置im.transpose()操作,這樣才符合PaddlePaddle的輸入格式。
# 讀取數據列表
with open('data/data_list.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
line = lines[50]
img_path, gt = line.replace('\n', '').split('\t')
gt = eval(gt)
img = Image.open(img_path)
im, gt = picture_opt(img, gt)
print(im.shape)
plt.imshow(im)

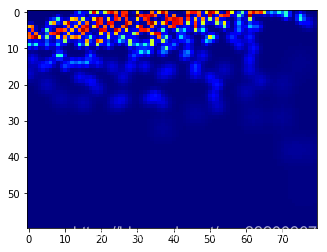
通過ground()函數將上面的圖片生成一個密度圖,密度圖結果如下圖所示。注意在輸入PaddlePaddle的密度圖是要經過裝置的,因爲圖像的數據的輸入是裝置的,所以密度圖也得裝置。
k, img_sum = ground(im, gt)
groundtruth = np.asarray(k)
groundtruth = groundtruth.astype('float32')
print("實際人數:", img_sum)
print("密度圖人數:", np.sum(groundtruth))
print("密度圖大小:", groundtruth.shape)
plt.imshow(groundtruth,cmap=CM.jet)
訓練程序¶
以下爲train.py的代碼,在訓練中使用了平方差損失函數,其中損失值乘以6e5是爲了不讓輸出的損失值太小。
loss = fluid.layers.square_error_cost(input=map_out, label=label) * 6e5
loss = fluid.layers.mean(loss)
爲了加快數據的讀取,這裏使用了異步數據讀取方式,可以一邊訓練一邊讀取下一步batch的數據。
py_reader = fluid.io.PyReader(feed_list=[images, label, img_num],
capacity=32,
iterable=True,
return_list=False)
py_reader.decorate_sample_list_generator(paddle.batch(reader.train_reader(data_list_file), batch_size=BATCH_SIZE),
places=fluid.core.CPUPlace())
在訓練前加上一個加載預訓練模型的方法,如果之前的模型存在,就加載該模型,接着上一次的訓練結果繼續訓練。
if PERSISTABLES_MODEL_PATH is not None and os.path.exists(PERSISTABLES_MODEL_PATH):
def if_exist(var):
if os.path.exists(os.path.join(PERSISTABLES_MODEL_PATH, var.name)):
print('loaded: %s' % var.name)
return os.path.exists(os.path.join(PERSISTABLES_MODEL_PATH, var.name))
fluid.io.load_vars(exe, PERSISTABLES_MODEL_PATH, main_program=fluid.default_main_program(), predicate=if_exist)
在執行訓練前需要留意以下幾個參數,需要根據自己的實際情況修改。當然如果開發者都是按照上面的操作,這裏基本上不需要修改,但是BATCH_SIZE可能要修改一下,因爲這個模型比較大,如何顯存小的可能還有修改,以下是筆者在8G顯存的環境下設置的。
# 是否使用GPU
USE_CUDA = True
# 模型參數保存路徑
PERSISTABLES_MODEL_PATH = 'persistables_model/'
# 預測模型保存路徑
INFER_MODEL = 'infer_model/'
# 訓練輪數
EPOCHS_SUM = 800
# Batch大小
BATCH_SIZE = 6
# 圖像列表路徑
data_list_file = 'data/data_list.txt'
最後執行python train.py開始訓練模型。
預測¶
最通過執行infer.py可以把data/test/目錄下的圖像都進行預測,結果寫入到results.csv文件中。
下面介紹預測的大概方式,通過加載訓練過程中保存的預測模型,得到一個預測程序。
import matplotlib.pyplot as plt
from matplotlib import cm as CM
import os
import numpy as np
import paddle.fluid as fluid
from PIL import Image
# 是否使用GPU
USE_CUDA = True
INFER_MODEL = 'infer_model/'
place = fluid.CUDAPlace(0) if USE_CUDA else fluid.CPUPlace()
exe = fluid.Executor(place)
[inference_program,
feed_target_names,
fetch_targets] = fluid.io.load_inference_model(INFER_MODEL, exe)
讀取一張待預測的圖片。
image_path = "data/test/00bdc7546131db72333c3e0ac9cf5478.jpg"
test_img = Image.open(image_path)
plt.imshow(test_img)

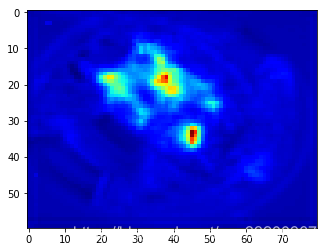
通過對圖像進行預處理,輸入到預測程序中,預測的結果有兩個,第一個是密度圖,第二個是估計人數,因爲輸出的估計是估計人數是一個帶小數的值,所以要進行四捨五入。其實對密度圖求和也是能夠得到估計人數的。因爲PaddlePaddle輸出的密度圖是經過轉置的,所以在顯示時需要再一次執行轉置才能正常顯示。
test_img = test_img.resize((640, 480), Image.ANTIALIAS)
test_im = np.array(test_img) / 255.0
test_im = test_im.transpose().reshape(1, 3, 640, 480).astype('float32')
results = exe.run(program=inference_program,
feed={feed_target_names[0]: test_im},
fetch_list=fetch_targets)
density, quantity = results[0], results[1]
q = int(abs(quantity) + 0.5)
print("預測人數:", q)
plt.imshow(density[0][0].T,cmap=CM.jet)
模型下載¶
| 模型名稱 | 所用數據集 | 下載地址 |
|---|---|---|
| 預訓練模型 | 常規賽-人流密度預測數據集 | 點擊下載 |
| 預測模型 | 常規賽-人流密度預測數據集 | 點擊下載 |