目錄¶
@[toc]
前言¶
在本章中,我們一起來學習下TensorFlow。我們將會學習到TensorFlow的一些基本庫。通過計算一個線性函數來熟悉這些庫。最後還學習使用TensorFlow搭建一個神經網絡來識別手勢。本章用到的一些庫在這裏下載。
TensorFlow的基本庫¶
首先是導入所需的庫,其中最重要的庫就是tensorflow的,我們給它一個別名tf。
import math
import numpy as np
import h5py
import tensorflow as tf
from tensorflow.python.framework import ops
from tf_utils import load_dataset, random_mini_batches, convert_to_one_hot, predict
下面我們使用TensorFlow計算一個損失函數,損失函數公式如下:
\(\(loss = \mathcal{L}(\hat{y}, y) = (\hat y^{(i)} - y^{(i)})^2 \tag{1}\)\)
首先定義兩個變量,對應是公式的y帽和y,如下,同時賦值y_hat是36,y是39:
y_hat = tf.constant(36, name='y_hat')
y = tf.constant(39, name='y')
然後根據上面的公式1來定義創建一個計算,其中計算次方非常方便,直接兩個星號**:
loss = tf.Variable((y - y_hat)**2, name='loss')
在使用TensorFlow之前,還要先初始化TensorFlow。在執行計算在session中完成。
init = tf.global_variables_initializer()
with tf.Session() as session:
session.run(init)
print(session.run(loss))
經過上面執行,最後輸出計算的結果:9
我們通過上面可以看到,TensorFlow定義變量和賦值並不是像我們不同編程一樣賦值的了,而是經過TensorFlow的封裝,同樣計算方式也是一樣,如下定義常量和計算也是一樣:
a = tf.constant(2)
b = tf.constant(10)
c = tf.multiply(a,b)
print(c)
從上面計算loss可以知道,計算要在session中執行。所以我們這裏不會輸出結果20,而是輸出c的張量:Tensor("Mul:0", shape=(), dtype=int32)
要計算它們的值,還有在session中run纔行,如下:
sess = tf.Session()
print(sess.run(c))
最後會輸出正確的結果:20。
上面都是一開始就指定變量的值的,但是有些情況下,我們是一開始是不用指定值的,那麼我們怎麼處理了,這樣就用到了佔位符,如下:
x = tf.placeholder(tf.int64, name = 'x')
print(sess.run(2 * x, feed_dict = {x: 3}))
sess.close()
這裏一開始我們沒有指定x的值,而是在run的時候,使用一個feed_dict字典的方式給x賦值。
常用計算¶
線性函數¶
下面來介紹計算線性函數的方法,下面是線性函數的公式:
\(\(Y = WX + b\tag{2}\)\)
使用的的函數如下:
tf.matmul()做一個矩陣乘法tf.add()做一個加法np.random.randn()隨機初始化
def linear_function():
# 隨機生成一個對應的張量
X = tf.constant(np.random.randn(3,1), name = "X")
W = tf.constant(np.random.randn(4,3), name = "W")
b = tf.constant(np.random.randn(4,1), name = "b")
# 生成線性函數
Y = tf.add(tf.matmul(W, X), b)
# 開始計算線性函數
sess = tf.Session()
result = sess.run(Y)
# 如果沒使用with的話,還要關閉session
sess.close()
return result
計算sigmoid函數¶
這是一個計算sigmoid函數,使用TensorFlow自帶函數,無需自己定義:
def sigmoid(z):
# 給x創建一個佔位符,並指定類型
x = tf.placeholder(tf.float32, name = "x")
# 使用TensorFlow自帶的sigmoid函數
sigmoid = tf.sigmoid(x)
with tf.Session() as sess:
# 使用傳進來的值計算
result = sess.run(sigmoid, feed_dict = {x: z})
return result
計算損失函數¶
損失函數的計算公式如下:
$$ J = - \frac{1}{m} \sum_{i = 1}^m \large ( \small y^{(i)} \log a^{ [2] (i)} + (1-y^{(i)})\log (1-a^{ [2] (i)} )\large )\small\tag{3}$$
可以通過直接調用tf.nn.sigmoid_cross_entropy_with_logits()函數定義完成損失函數的計算:
def cost(logits, labels):
# 定義兩個佔位符
z = tf.placeholder(tf.float32, name = "z")
y = tf.placeholder(tf.float32, name = "y")
# 使用TensorFlow自帶函數計算交叉熵損失
cost = tf.nn.sigmoid_cross_entropy_with_logits(logits = z, labels = y)
# 創建session
sess = tf.Session()
# 開始計算損失值
cost = sess.run(cost, feed_dict = {z: logits, y: labels})
# 關閉session
sess.close
return cost
獨熱編碼¶
獨熱編碼即 One-Hot 編碼,又稱一位有效編碼,其方法是使用N位狀態寄存器來對N個狀態進行編碼,每個狀態都由他獨立的寄存器位,並且在任意時候,其中只有一位有效。如下圖所示:
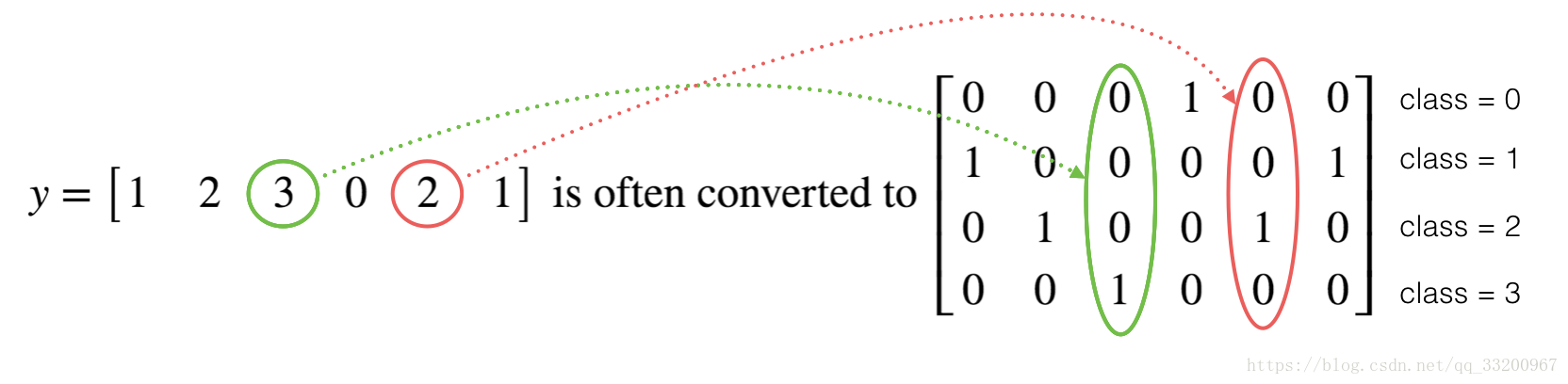
在TensorFlow中可以使用tf.one_hot(標籤,深度,軸)創建獨熱編碼,使用TensorFlow如下:
def one_hot_matrix(labels, C):
# 定義深度常量
C = tf.constant(C, name = "C")
# 創建獨熱編碼矩陣
one_hot_matrix = tf.one_hot(labels, C, axis = 0)
# 創建Session
sess = tf.Session()
# 計算獨熱編碼
one_hot = sess.run(one_hot_matrix)
# 關閉session
sess.close
return one_hot
我們測試一下,看看效果:
labels = np.array([1,2,3,0,2,1])
# 4個深度,也就是4個類別
one_hot = one_hot_matrix(labels, C = 4)
print ("one_hot = " + str(one_hot))
輸出結果如下:
one_hot = [[ 0. 0. 0. 1. 0. 0.]
[ 1. 0. 0. 0. 0. 1.]
[ 0. 1. 0. 0. 1. 0.]
[ 0. 0. 1. 0. 0. 0.]]
初始化矩陣¶
可以使用TensorFlow自帶函數創建1矩陣:
def ones(shape):
# 根據形狀大小傳1矩陣
ones = tf.ones(shape)
# 獲取Session
sess = tf.Session()
# 在session中運行
ones = sess.run(ones)
# 關閉session
sess.close
return ones
TensorFlow創建神經網絡¶
使用TensorFlow創建一個神經網絡,來識別手勢。我們可以使用獨熱編碼當做圖像的標籤。

首先是加載數據:
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
對數據進行扁平化和歸一化:
# 訓練和測試圖像
X_train_flatten = X_train_orig.reshape(X_train_orig.shape[0], -1).T
X_test_flatten = X_test_orig.reshape(X_test_orig.shape[0], -1).T
# 歸一化圖像向量
X_train = X_train_flatten/255.
X_test = X_test_flatten/255.
# 將訓練和測試標籤轉換爲獨熱矩陣
Y_train = convert_to_one_hot(Y_train_orig, 6)
Y_test = convert_to_one_hot(Y_test_orig, 6)
爲輸入數據和輸出結果定義一個佔位符:
def create_placeholders(n_x, n_y):
# 輸入數據佔位符
X = tf.placeholder(dtype=tf.float32,shape=(n_x, None), name = "Placeholder_1")
# 輸出數據佔位符
Y = tf.placeholder(dtype=tf.float32,shape=(n_y, None), name = "Placeholder_2")
return X, Y
初始化參數:
def initialize_parameters():
# 初始化權重和偏置值
W1 = tf.get_variable("W1", [25,12288], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b1 = tf.get_variable("b1", [25,1], initializer = tf.zeros_initializer())
W2 = tf.get_variable("W2", [12,25], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b2 = tf.get_variable("b2", [12,1], initializer = tf.zeros_initializer())
W3 = tf.get_variable("W3", [6,12], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b3 = tf.get_variable("b3", [6,1], initializer = tf.zeros_initializer())
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
return parameters
計算正向傳播:
def forward_propagation(X, parameters):
# 獲取權重和偏差值
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
# 相當於 Z1 = np.dot(W1, X) + b1
Z1 = tf.add(tf.matmul(W1, X), b1)
# 計算RELU A1 = relu(Z1)
A1 = tf.nn.relu(Z1)
# 相當於 Z2 = np.dot(W2, a1) + b2
Z2 = tf.add(tf.matmul(W2, A1), b2)
# 計算RELU A2 = relu(Z2)
A2 = tf.nn.relu(Z2)
# 相當於 Z3 = np.dot(W3,Z2) + b3
Z3 = tf.add(tf.matmul(W3, A2), b3)
return Z3
計算損失:
def compute_cost(Z3, Y):
# 轉置,爲下面計算計算損失做準備
logits = tf.transpose(Z3)
labels = tf.transpose(Y)
# 傳入的值是數據和標籤
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = labels))
return cost
計算反向傳播和更新參數,使用框架的話,只要使用下面兩行代碼就可以了:
optimizer = tf.train.GradientDescentOptimizer(learning_rate = learning_rate).minimize(cost)
_ , c = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})
創建模型¶
def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.0001,
num_epochs = 1500, minibatch_size = 32, print_cost = True):
"""
3層神經網絡: LINEAR->RELU->LINEAR->RELU->LINEAR->SOFTMAX.
Arguments:
X_train -- 訓練數據集,輸入大小爲12288,輸入數量爲1080
Y_train -- 訓練標籤,輸入大小爲6,輸入數量爲1080
X_test -- 訓練數據集,輸入大小爲12288,輸入數量爲120
Y_test -- 訓練標籤,輸入大小爲6,輸入數量爲120
learning_rate -- 學習速率的優化
num_epochs -- 優化循環的週期數
minibatch_size -- minibatch大小
print_cost -- 每100個pass就打印成本
Returns:
parameters -- 由模型學習的參數。他們可以被用來預測。
"""
ops.reset_default_graph()
tf.set_random_seed(1)
seed = 3
# n_x:輸入大小,m:數據集樣本
(n_x, m) = X_train.shape
# 輸出大小
n_y = Y_train.shape[0]
costs = []
# 創建輸入輸出佔位符
X, Y = create_placeholders(n_x, n_y)
# 初始化參數
parameters = initialize_parameters()
# 計算正向傳播
Z3 = forward_propagation(X, parameters)
# 計算損失值
cost = compute_cost(Z3, Y)
# 反向傳播,定義優化方法嗎,使員工Adam作爲優化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate = learning_rate).minimize(cost)
# 初始化所有的變量
init = tf.global_variables_initializer()
# 在Session中計算
with tf.Session() as sess:
# 運行初始化
sess.run(init)
# 在循環中訓練
for epoch in range(num_epochs):
epoch_cost = 0.
# 計算小批量的數量
num_minibatches = int(m / minibatch_size)
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
# 把每個批量的數據拆分
(minibatch_X, minibatch_Y) = minibatch
# 在session中運行優化器和Cost
_ , minibatch_cost = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})
epoch_cost += minibatch_cost / num_minibatches
# 打印cost
if print_cost == True and epoch % 100 == 0:
print ("Cost after epoch %i: %f" % (epoch, epoch_cost))
if print_cost == True and epoch % 5 == 0:
costs.append(epoch_cost)
# 參數保存在一個變量中
parameters = sess.run(parameters)
print ("Parameters have been trained!")
# 計算正確的預測
correct_prediction = tf.equal(tf.argmax(Z3), tf.argmax(Y))
# 計算測試集的準確性。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print ("Train Accuracy:", accuracy.eval({X: X_train, Y: Y_train}))
print ("Test Accuracy:", accuracy.eval({X: X_test, Y: Y_test}))
return parameters
最後通過調用該函數即可完成訓練:
parameters = model(X_train, Y_train, X_test, Y_test)
預測,訓練好的參數就可以用來預測了,如下:
import scipy
from PIL import Image
from scipy import ndimage
my_image = "thumbs_up.jpg"
# 預先處理圖像以適應的算法
fname = "images/" + my_image
image = np.array(ndimage.imread(fname, flatten=False))
my_image = scipy.misc.imresize(image, size=(64,64)).reshape((1, 64*64*3)).T
my_image_prediction = predict(my_image, parameters)
print("Your algorithm predicts: y = " + str(np.squeeze(my_image_prediction)))
參考資料¶
http://deeplearning.ai/
該筆記是學習吳恩達老師的課程寫的。初學者入門,如有理解有誤的,歡迎批評指正!