
PPASR流式与非流式语音识别

前言
本项目将分三个阶段分支,分别是入门级 、进阶级 和最终级 分支,当前为最终级,持续维护版本。PPASR中文名称PaddlePaddle中文语音识别(PaddlePaddle Automatic Speech Recognition),是一款基于PaddlePaddle实现的语音识别框架,PPASR致力于简单,实用的语音识别项目。可部署在服务器,Nvidia Jetson设备,未来还计划支持Android等移动设备。
别忘了star
源码地址:https://github.com/yeyupiaoling/PPASR
在线使用
2. 在线使用Dome
本项目使用的环境:
- Anaconda 3
- Python 3.7
- PaddlePaddle 2.2.0
- Windows 10 or Ubuntu 18.04
模型下载
| 数据集 | 使用模型 | 测试集字错率 | 下载地址 |
|---|---|---|---|
| aishell(179小时) | deepspeech2 | 0.077042 | 点击下载 |
| free_st_chinese_mandarin_corpus(109小时) | deepspeech2 | 0.137442 | 点击下载 |
| thchs_30(34小时) | deepspeech2 | 0.062654 | 点击下载 |
| 超大数据集(1600多小时真实数据)+(1300多小时合成数据) | deepspeech2 | 0.056835 | 点击下载 |
说明:
- 这里字错率是使用
eval.py程序并使用集束搜索解码ctc_beam_search方法计算得到的。 - 除了aishell数据集按照数据集本身划分的训练数据和测试数据,其他的都是按照项目设置的固定比例划分训练数据和测试数据。
- 下载的压缩文件已经包含了
mean_std.npz和vocabulary.txt,需要把解压得到的全部文件复制到项目根目录下。
有问题欢迎提 issue 交流
快速预测
python infer_path.py --wav_path=./dataset/test.wav
输出结果:
----------- Configuration Arguments -----------
alpha: 1.2
beam_size: 10
beta: 0.35
cutoff_prob: 1.0
cutoff_top_n: 40
decoding_method: ctc_greedy
enable_mkldnn: False
is_long_audio: False
lang_model_path: ./lm/zh_giga.no_cna_cmn.prune01244.klm
mean_std_path: ./dataset/mean_std.npz
model_dir: ./models/infer/
to_an: True
use_gpu: True
use_tensorrt: False
vocab_path: ./dataset/zh_vocab.txt
wav_path: ./dataset/test.wav
------------------------------------------------
消耗时间:132, 识别结果: 近几年不但我用书给女儿儿压岁也劝说亲朋不要给女儿压岁钱而改送压岁书, 得分: 94
数据准备
- 在
download_data目录下是公开数据集的下载和制作训练数据列表和词汇表的,本项目提供了下载公开的中文普通话语音数据集,分别是Aishell,Free ST-Chinese-Mandarin-Corpus,THCHS-30 这三个数据集,总大小超过28G。下载这三个数据只需要执行一下代码即可,当然如果想快速训练,也可以只下载其中一个。注意:noise.py可下载可不下载,这是用于训练时数据增强的,如果不想使用噪声数据增强,可以不用下载。
cd download_data/
python aishell.py
python free_st_chinese_mandarin_corpus.py
python thchs_30.py
python noise.py
注意: 以上代码只支持在Linux下执行,如果是Windows的话,可以获取程序中的DATA_URL单独下载,建议用迅雷等下载工具,这样下载速度快很多。然后把download()函数改为文件的绝对路径,如下,我把aishell.py的文件单独下载,然后替换download()函数,再执行该程序,就会自动解压文件文本生成数据列表。
# 把这行代码
filepath = download(url, md5sum, target_dir)
# 修改为
filepath = "D:\\Download\\data_aishell.tgz"
- 如果开发者有自己的数据集,可以使用自己的数据集进行训练,当然也可以跟上面下载的数据集一起训练。自定义的语音数据需要符合以下格式,另外对于音频的采样率,本项目默认使用的是16000Hz,在
create_data.py中也提供了统一音频数据的采样率转换为16000Hz,只要is_change_frame_rate参数设置为True就可以。- 语音文件需要放在
dataset/audio/目录下,例如我们有个wav的文件夹,里面都是语音文件,我们就把这个文件存放在dataset/audio/。 - 然后把数据列表文件存在
dataset/annotation/目录下,程序会遍历这个文件下的所有数据列表文件。例如这个文件下存放一个my_audio.txt,它的内容格式如下。每一行数据包含该语音文件的相对路径和该语音文件对应的中文文本,他们之间用\t隔开。要注意的是该中文文本只能包含纯中文,不能包含标点符号、阿拉伯数字以及英文字母。
- 语音文件需要放在
dataset/audio/wav/0175/H0175A0171.wav 我需要把空调温度调到二十度
dataset/audio/wav/0175/H0175A0377.wav 出彩中国人
dataset/audio/wav/0175/H0175A0470.wav 据克而瑞研究中心监测
dataset/audio/wav/0175/H0175A0180.wav 把温度加大到十八
- 最后执行下面的数据集处理程序,详细参数请查看该程序。这个程序是把我们的数据集生成三个JSON格式的数据列表,分别是
manifest.test、manifest.train、manifest.noise。然后建立词汇表,把所有出现的字符都存放子在vocabulary.txt文件中,一行一个字符。最后计算均值和标准差用于归一化,默认使用全部的语音计算均值和标准差,并将结果保存在mean_std.npz中。以上生成的文件都存放在dataset/目录下。数据划分说明,如果dataset/annotation存在test.txt,那全部测试数据都使用这个数据,否则使用全部数据的1/500的数据,直到指定的最大测试数据量。
python create_data.py
训练模型
- 训练流程,首先是准备数据集,具体看数据准备部分,重点是执行
create_data.py程序,执行完成之后检查是否在dataset目录下生成了manifest.test、manifest.train、mean_std.npz、vocabulary.txt这四个文件,并确定里面已经包含数据。然后才能往下执行开始训练。 - 执行训练脚本,开始训练语音识别模型,详细参数请查看该程序。每训练一轮和每10000个batch都会保存一次模型,模型保存在
models/<use_model>/epoch_*/目录下,默认会使用数据增强训练,如何不想使用数据增强,只需要将参数augment_conf_path设置为None即可。关于数据增强,请查看数据增强部分。如果没有关闭测试,在每一轮训练结果之后,都会执行一次测试计算模型在测试集的准确率,注意为了加快训练速度,默认使用的是ctc_greedy解码器,如果需要使用ctc_beam_search解码器,请设置decoder参数。如果模型文件夹下包含last_model文件夹,在训练的时候会自动加载里面的模型,这是为了方便中断训练的之后继续训练,无需手动指定,如果手动指定了resume_model参数,则以resume_model指定的路径优先加载。如果不是原来的数据集或者模型结构,需要删除last_model这个文件夹。
# 单卡训练
python3 train.py
# 多卡训练
python -m paddle.distributed.launch --gpus '0,1' train.py
训练输出结果如下:
----------- Configuration Arguments -----------
alpha: 2.2
augment_conf_path: conf/augmentation.json
batch_size: 32
beam_size: 300
beta: 4.3
cutoff_prob: 0.99
cutoff_top_n: 40
dataset_vocab: dataset/vocabulary.txt
decoder: ctc_greedy
lang_model_path: lm/zh_giga.no_cna_cmn.prune01244.klm
learning_rate: 5e-05
max_duration: 20
mean_std_path: dataset/mean_std.npz
min_duration: 0.5
num_epoch: 65
num_proc_bsearch: 10
num_workers: 8
pretrained_model: None
resume_model: None
save_model_path: models/
test_manifest: dataset/manifest.test
train_manifest: dataset/manifest.train
use_model: deepspeech2
------------------------------------------------
............
[2021-09-17 08:41:16.135825] Train epoch: [24/50], batch: [5900/6349], loss: 3.84609, learning rate: 0.00000688, eta: 10:38:40
[2021-09-17 08:41:38.698795] Train epoch: [24/50], batch: [6000/6349], loss: 0.92967, learning rate: 0.00000688, eta: 8:42:11
[2021-09-17 08:42:04.166192] Train epoch: [24/50], batch: [6100/6349], loss: 2.05670, learning rate: 0.00000688, eta: 10:59:51
[2021-09-17 08:42:26.471328] Train epoch: [24/50], batch: [6200/6349], loss: 3.03502, learning rate: 0.00000688, eta: 11:51:28
[2021-09-17 08:42:50.002897] Train epoch: [24/50], batch: [6300/6349], loss: 2.49653, learning rate: 0.00000688, eta: 12:01:30
======================================================================
[2021-09-17 08:43:01.954403] Test batch: [0/65], loss: 13.76276, cer: 0.23105
[2021-09-17 08:43:07.817434] Test epoch: 24, time/epoch: 0:24:30.756875, loss: 6.90274, cer: 0.15213
======================================================================
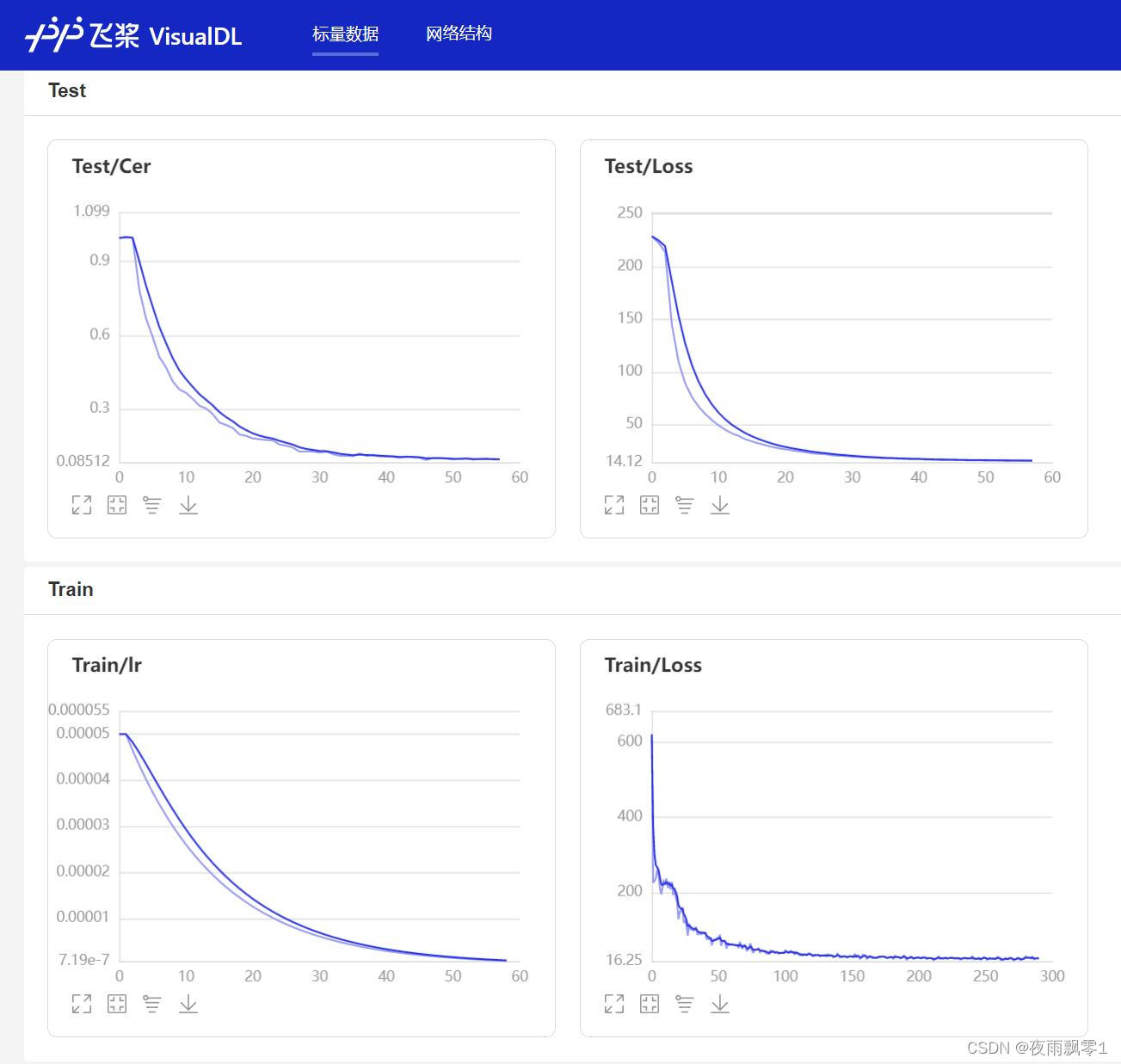
- 在训练过程中,程序会使用VisualDL记录训练结果,可以通过以下的命令启动VisualDL。
visualdl --logdir=log --host=0.0.0.0
- 然后再浏览器上访问
http://localhost:8040可以查看结果显示,如下。
评估
执行下面这个脚本对模型进行评估,通过字符错误率来评价模型的性能,详细参数请查看该程序。
python eval.py --resume_model=models/deepspeech2/best_model
输出结果:
----------- Configuration Arguments -----------
alpha: 2.2
batch_size: 32
beam_size: 300
beta: 4.3
cutoff_prob: 0.99
cutoff_top_n: 40
dataset_vocab: dataset/vocabulary.txt
decoder: ctc_beam_search
lang_model_path: lm/zh_giga.no_cna_cmn.prune01244.klm
mean_std_path: dataset/mean_std.npz
num_proc_bsearch: 10
num_workers: 8
resume_model: models/deepspeech2/best_model/
test_manifest: dataset/manifest.test
use_model: deepspeech2
------------------------------------------------
W0918 10:33:58.960235 16295 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.0, Runtime API Version: 10.2
W0918 10:33:58.963088 16295 device_context.cc:422] device: 0, cuDNN Version: 7.6.
100%|██████████████████████████████| 45/45 [00:09<00:00, 4.50it/s]
评估消耗时间:10s,字错率:0.095808
导出模型
训练保存的或者下载作者提供的模型都是模型参数,我们要将它导出为预测模型,这样可以直接使用模型,不再需要模型结构代码,同时使用Inference接口可以加速预测,详细参数请查看该程序。
python export_model.py --resume_model=models/deepspeech2/epoch_50/
输出结果:
----------- Configuration Arguments -----------
dataset_vocab: dataset/vocabulary.txt
mean_std_path: dataset/mean_std.npz
resume_model: models/deepspeech2/epoch_50
save_model: models/deepspeech2/
use_model: deepspeech2
------------------------------------------------
[2021-09-18 10:23:47.022243] 成功恢复模型参数和优化方法参数:models/deepspeech2/epoch_50/model.pdparams
预测模型已保存:models/deepspeech2/infer
本地预测
我们可以使用这个脚本使用模型进行预测,如果如何还没导出模型,需要执行导出模型操作把模型参数导出为预测模型,通过传递音频文件的路径进行识别,通过参数--wav_path指定需要预测的音频路径。支持中文数字转阿拉伯数字,将参数--to_an设置为True即可,默认为True。
python infer_path.py --wav_path=./dataset/test.wav
输出结果:
----------- Configuration Arguments -----------
alpha: 2.2
beam_size: 300
beta: 4.3
cutoff_prob: 0.99
cutoff_top_n: 40
decoder: ctc_beam_search
is_long_audio: False
lang_model_path: lm/zh_giga.no_cna_cmn.prune01244.klm
model_dir: models/deepspeech2/infer/
real_time_demo: False
to_an: True
use_gpu: True
use_model: deepspeech2
vocab_path: dataset/vocabulary.txt
wav_path: ./dataset/test.wav
------------------------------------------------
消耗时间:101, 识别结果: 近几年不但我用书给女儿儿压岁也劝说亲朋不要给女儿压岁钱而改送压岁书, 得分: 94
长语音预测
通过参数--is_long_audio可以指定使用长语音识别方式,这种方式通过VAD分割音频,再对短音频进行识别,拼接结果,最终得到长语音识别结果。
python infer_path.py --wav_path=./dataset/test_vad.wav --is_long_audio=True
输出结果:
----------- Configuration Arguments -----------
alpha: 2.2
beam_size: 300
beta: 4.3
cutoff_prob: 0.99
cutoff_top_n: 40
decoding_method: ctc_greedy
is_long_audio: 1
lang_model_path: ./lm/zh_giga.no_cna_cmn.prune01244.klm
model_dir: ./models/deepspeech2/infer/
to_an: True
use_gpu: True
vocab_path: ./dataset/zh_vocab.txt
wav_path: dataset/test_vad.wav
------------------------------------------------
第0个分割音频, 得分: 70, 识别结果: 记的12铺地补买上过了矛乱钻吃出满你都着们现上就只有1良解太穷了了臭力量紧不着还绑在大理达高的铁股上
第1个分割音频, 得分: 86, 识别结果: 我们都是骑自行说
第2个分割音频, 得分: 91, 识别结果: 他李达康知不知道党的组织原则
第3个分割音频, 得分: 71, 识别结果: 没是把就都路通着奖了李达方就是请他作现长件2着1把爽他作收记书就是发爽
第4个分割音频, 得分: 76, 识别结果: 那的当了熊掌我还得听她了哈哈他这太快还里生长还那得聊嘛安不乖怎么说
第5个分割音频, 得分: 97, 识别结果: 他老婆总是出事了嘛
第6个分割音频, 得分: 63, 识别结果: 就是前急次
第7个分割音频, 得分: 87, 识别结果: 欧阳箐是他前妻
第8个分割音频, 得分: 0, 识别结果:
第9个分割音频, 得分: 97, 识别结果: 我最后再说1句啊
第10个分割音频, 得分: 84, 识别结果: 能不能帮我个的小忙
第11个分割音频, 得分: 86, 识别结果: 说
第12个分割音频, 得分: 85, 识别结果: 她那陈清泉放了别再追究的
第13个分割音频, 得分: 93, 识别结果: 这陈清泉
第14个分割音频, 得分: 79, 识别结果: 跟你有生我来啊
第15个分割音频, 得分: 87, 识别结果: 我不认识个人
第16个分割音频, 得分: 81, 识别结果: 就是高小琴的人那你管这么宽干嘛啊
第17个分割音频, 得分: 94, 识别结果: 真以天下为己任了
第18个分割音频, 得分: 76, 识别结果: 你天下为竟人那是哪那耍我就是上在上晚上你们再山水张院的人让我照片和宁练个在我整么那不那板法
第19个分割音频, 得分: 67, 识别结果: 你就生涯真说晚啦是长微台过会来决定了
最终结果,消耗时间:1587, 得分: 79, 识别结果: ,记的12铺地补买上过了矛乱钻吃出满你都着们现上就只有1良解太穷了了臭力量紧不着还绑在大理达高的铁股上,我们都是骑自行说,他李达康知不知道党的组织原则,没是把就都路通着奖了李达方就是请他作现长件2着1把爽他作收记书就是发爽,那的当了熊掌我还得听她了哈哈他这太快还里生长还那得聊嘛安不乖怎么说,他老婆总是出事了嘛,就是前急次,欧阳箐是他前妻,,我最后再说1句啊,能不能帮我个的小忙,说,她那陈清泉放了别再追究的,这陈清泉,跟你有生我来啊,我不认识个人,就是高小琴的人那你管这么宽干嘛啊,真以天下为己任了,你天下为竟人那是哪那耍我就是上在上晚上你们再山水张院的人让我照片和宁练个在我整么那不那板法,你就生涯真说晚啦是长微台过会来决定了
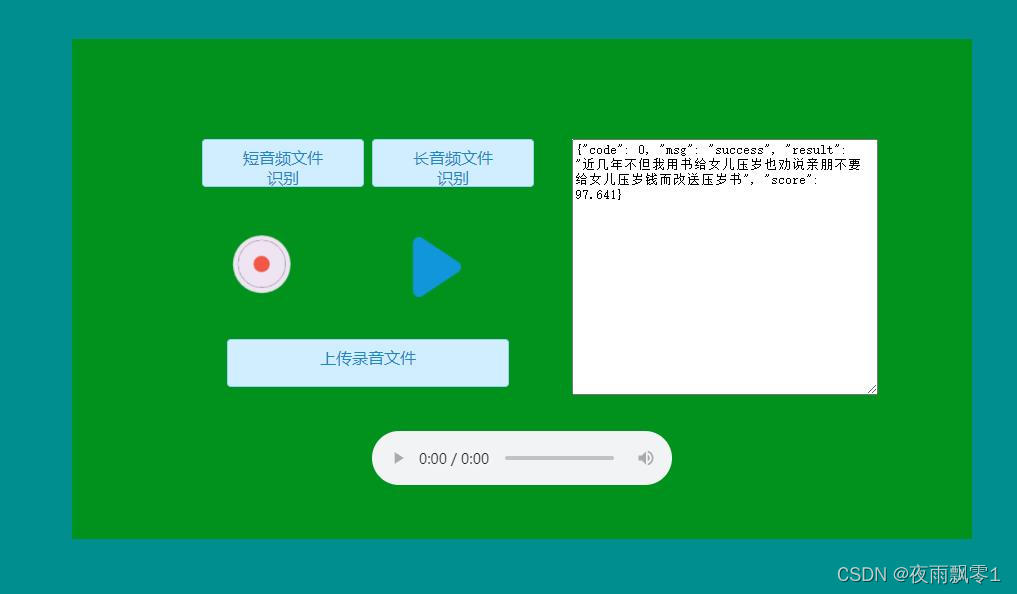
Web部署
在服务器执行下面命令通过创建一个Web服务,通过提供HTTP接口来实现语音识别。启动服务之后,如果在本地运行的话,在浏览器上访问http://localhost:5000,否则修改为对应的 IP地址。打开页面之后可以选择上传长音或者短语音音频文件,也可以在页面上直接录音,录音完成之后点击上传,播放功能只支持录音的音频。支持中文数字转阿拉伯数字,将参数--to_an设置为True即可,默认为True。
python infer_server.py
打开页面如下:
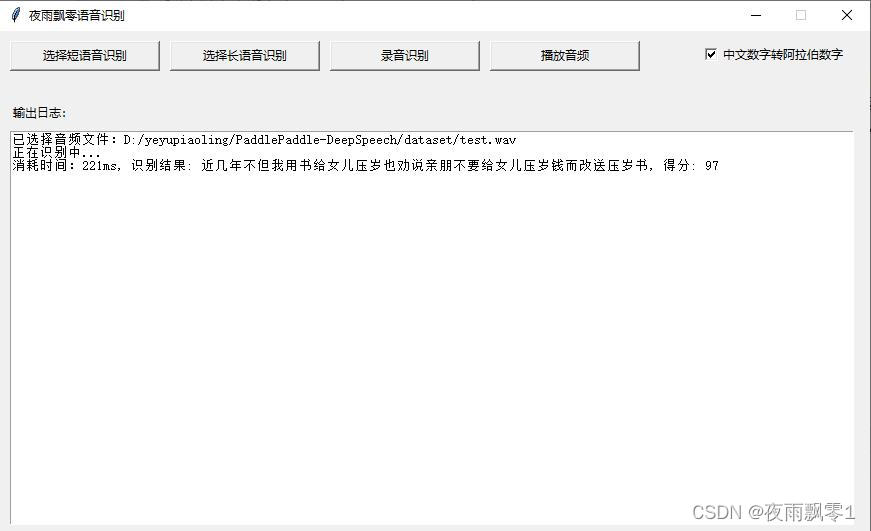
GUI界面部署
通过打开页面,在页面上选择长语音或者短语音进行识别,也支持录音识别,同时播放识别的音频。默认使用的是贪心解码策略,如果需要使用集束搜索方法的话,需要在启动参数的时候指定。
python infer_gui.py
打开界面如下:
相关项目
- 基于PaddlePaddle实现的声纹识别:VoiceprintRecognition-PaddlePaddle
- 基于PaddlePaddle静态图实现的语音识别:PaddlePaddle-DeepSpeech
- 基于Pytorch实现的语音识别:MASR