
Python的Numpy实现深度学习常用的函数

常用的激活函数
我们常用的激活函数有sigmoid,tanh,ReLU这三个函数,我们都来学习学习吧。
sigmoid函数
在深度学习中,我们经常会使用到sigmoid函数作为我们的激活函数,特别是在二分类上,sigmoid函数是比较好的一个选择,以下就是sigmoid函数的公式:
$$
sigmoid(x) = \frac{1}{1+e^{-x}}\tag{1}
$$
sigmoid函数的坐标图是:
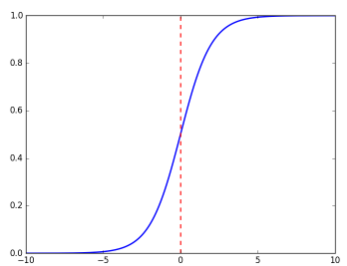
sigmoid函数的代码实现:
import numpy as np
def sigmoid(x):
s = 1 / (1 + np.exp(-x))
return s
因为是使用numpy实现的sigmoid函数的,所以这个sigmoid函数可以计算实数、矢量和矩阵,如下面的就是当x是实数的时候:
if __name__ == '__main__':
x = 3
s = sigmoid(x)
print s
然后会输出:
0.952574126822
当x是矢量或者矩阵是,计算公式如下:
$$
sigmoid(x) = sigmoid\begin{pmatrix}
x_1 \
x_2 \
... \
x_n \
\end{pmatrix} = \begin{pmatrix}
\frac{1}{1+e^{-x_1}} \
\frac{1}{1+e^{-x_2}} \
... \
\frac{1}{1+e^{-x_n}} \
\end{pmatrix}\tag{2}
$$
使用sigmoid函数如下:
if __name__ == '__main__':
x = np.array([2, 3, 4])
s = sigmoid(x)
print s
输出的结果是:
[0.88079708 0.95257413 0.98201379]
sigmoid函数的梯度
为什么要计算sigmoid函数的梯度,比如当我们在使用反向传播来计算梯度,以优化损失函数。当使用的激活函数是sigmoid函数就要计算sigmoid函数的梯度了。计算公式如下:
$$
sigmoid_derivative(x) = \sigma'(x) = \sigma(x) (1 - \sigma(x))\tag{3}
$$
Python你代码实现:
import numpy as np
def sigmoid_derivative(x):
s = 1 / (1 + np.exp(-x))
ds = s * (1 - s)
return ds
当x是实数时,计算如下:
if __name__ == '__main__':
x = 3
s = sigmoid_derivative(x)
print s
输出结果如下:
0.0451766597309
当x是矩阵或者矢量时,计算如下:
if __name__ == '__main__':
x = np.array([2, 3, 4])
s = sigmoid_derivative(x)
print s
输出结果如下:
[0.10499359 0.04517666 0.01766271]
tanh函数
tanh也是一个常用的激活函数,它的公式如下:
$$
tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}}\tag{4}
$$
tanh的坐标图是:
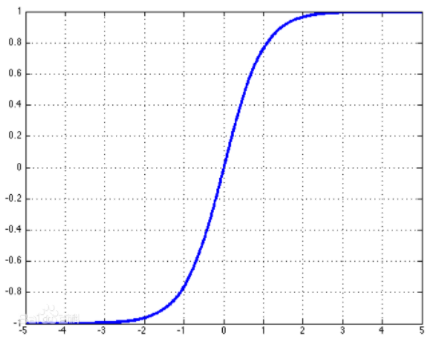
tanh的代码实现:
import numpy as np
def tanh(x):
s1 = np.exp(x) - np.exp(-x)
s2 = np.exp(x) + np.exp(-x)
s = s1 / s2
return s
为了方便,这里把x是实数、矢量或矩阵的情况一起计算了,调用方法如下:
if __name__ == '__main__':
x = 3
s = tanh(x)
print s
x = np.array([2, 3, 4])
s = tanh(x)
print s
以下就是输出结果:
0.995054753687
[0.96402758 0.99505475 0.9993293 ]
tanh函数的梯度
同样在这里我们也要计算tanh函数的梯度,计算公式如下:
$$
tanh_derivative(x) = tanh'(x) = 1 - \tanh^2x = 1- \left(\frac{e^x-e^{-x}}{e^x+e^{-x}}\right)^2\tag{5}
$$
Python代码实现如下:
import numpy as np
def tanh_derivative(x):
s1 = np.exp(x) - np.exp(-x)
s2 = np.exp(x) + np.exp(-x)
tanh = s1 / s2
s = 1 - tanh * tanh
return s
调用方法如下:
if __name__ == '__main__':
x = 3
s = tanh_derivative(x)
print s
x = np.array([2, 3, 4])
s = tanh_derivative(x)
print s
输出结果如下:
0.00986603716544
[0.07065082 0.00986604 0.00134095]
ReLU函数
ReLU是目前深度学习最常用的一个激活函数,数学公式如下:
$$
relu(x) = max(0,x)=\left{\begin{matrix}x,& \text{if} \quad x > 0 \ 0,& \text{if} \quad x \leq0\end{matrix}\right.\tag{6}
$$
其对应的坐标图为:
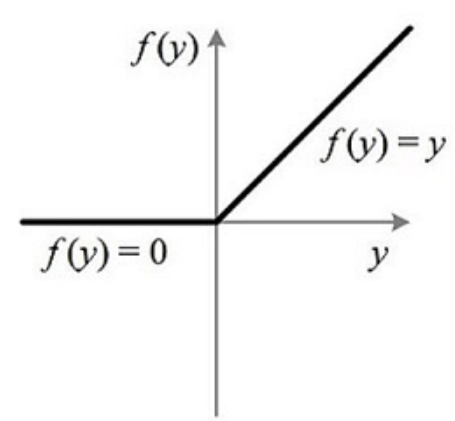
Python代码的实现:
import numpy as np
def relu(x):
s = np.where(x < 0, 0, x)
return s
调用方式如下:
if __name__ == '__main__':
x = -1
s = relu(x)
print s
x = np.array([2, -3, 1])
s = relu(x)
print s
输出结果如下:
0
[2 0 1]
图像转矢量
为了提高训练是的计算速度,一般会把图像转成矢量,一张三通道的图像的格式是$(width, height, 3)$会转成$(widthheight3, 1)$,我们使用Python代码尝试一下:
import numpy as np
def image2vector(image):
v = image.reshape((image.shape[0] * image.shape[1] * image.shape[2], 1))
return v
调用方法如下:
if __name__ == '__main__':
image = np.array([[[0.67826139, 0.29380381],
[0.90714982, 0.52835647],
[0.4215251, 0.45017551]],
[[0.92814219, 0.96677647],
[0.85304703, 0.52351845],
[0.19981397, 0.27417313]],
[[0.60659855, 0.00533165],
[0.10820313, 0.49978937],
[0.34144279, 0.94630077]]])
vector = image2vector(image)
print "image shape is :", image.shape
print "vector shape is :", vector.shape
print "vector is :" + str(image2vector(image))
输出结果如下:
image shape is : (3, 3, 2)
vector shape is : (18, 1)
vector is :[[0.67826139]
[0.29380381]
[0.90714982]
[0.52835647]
[0.4215251 ]
[0.45017551]
[0.92814219]
[0.96677647]
[0.85304703]
[0.52351845]
[0.19981397]
[0.27417313]
[0.60659855]
[0.00533165]
[0.10820313]
[0.49978937]
[0.34144279]
[0.94630077]]
规范化行
在深度学习中通过规范化行,可以使模型收敛得更快。它的计算公式如下:
$$
x = \begin{bmatrix}
0 & 3 & 4 \
2 & 6 & 4 \
\end{bmatrix}\tag{7}
$$
then
$$
| x| = np.linalg.norm(x, axis = 1, keepdims = True) = \begin{bmatrix}
5 \
\sqrt{56} \
\end{bmatrix}\tag{8}
$$
and
$$
x_normalized = \frac{x}{| x|} = \begin{bmatrix}
0 & \frac{3}{5} & \frac{4}{5} \
\frac{2}{\sqrt{56}} & \frac{6}{\sqrt{56}} & \frac{4}{\sqrt{56}} \
\end{bmatrix}\tag{9}
$$
Python代码实现:
import numpy as np
def normalizeRows(x):
x_norm = np.linalg.norm(x, axis=1, keepdims=True)
print "x_norm = ", x_norm
x = x / x_norm
return x
调用该函数:
if __name__ == '__main__':
x = np.array([
[0, 3, 4],
[1, 6, 4]])
print "normalizeRows(x) = " + str(normalizeRows(x))
输出结果如下:
x_norm = [[5. ]
[7.28010989]]
normalizeRows(x) = [[0. 0.6 0.8 ]
[0.13736056 0.82416338 0.54944226]]
广播和softmax函数
广播是将较小的矩阵“广播”到较大矩阵相同的形状尺度上,使它们对等以可以进行数学计算。注意的是较小的矩阵要是较大矩阵的倍数,否则无法使用广播。
以下就是softmax函数,这函数在计算的过程就使用到了广播的性质。softmax函数的公式如下:
$$
x \in \mathbb{R}^{1\times n} \text{, } softmax(x) = softmax(\begin{bmatrix}
x_1 &&
x_2 &&
... &&
x_n
\end{bmatrix}) = \begin{bmatrix}
\frac{e^{x_1}}{\sum_{j}e^{x_j}} &&
\frac{e^{x_2}}{\sum_{j}e^{x_j}} &&
... &&
\frac{e^{x_n}}{\sum_{j}e^{x_j}}
\end{bmatrix} \tag{10}
$$
$$
x \in \mathbb{R}^{m \times n} \text{, }x_{ij} \quad softmax(x) = softmax\begin{bmatrix}
x_{11} & x_{12} & x_{13} & \dots & x_{1n} \
x_{21} & x_{22} & x_{23} & \dots & x_{2n} \
\vdots & \vdots & \vdots & \ddots & \vdots \
x_{m1} & x_{m2} & x_{m3} & \dots & x_{mn}
\end{bmatrix} = \begin{bmatrix}
\frac{e^{x_{11}}}{\sum_{j}e^{x_{1j}}} & \frac{e^{x_{12}}}{\sum_{j}e^{x_{1j}}} & \frac{e^{x_{13}}}{\sum_{j}e^{x_{1j}}} & \dots & \frac{e^{x_{1n}}}{\sum_{j}e^{x_{1j}}} \
\frac{e^{x_{21}}}{\sum_{j}e^{x_{2j}}} & \frac{e^{x_{22}}}{\sum_{j}e^{x_{2j}}} & \frac{e^{x_{23}}}{\sum_{j}e^{x_{2j}}} & \dots & \frac{e^{x_{2n}}}{\sum_{j}e^{x_{2j}}} \
\vdots & \vdots & \vdots & \ddots & \vdots \
\frac{e^{x_{m1}}}{\sum_{j}e^{x_{mj}}} & \frac{e^{x_{m2}}}{\sum_{j}e^{x_{mj}}} & \frac{e^{x_{m3}}}{\sum_{j}e^{x_{mj}}} & \dots & \frac{e^{x_{mn}}}{\sum_{j}e^{x_{mj}}}
\end{bmatrix} = \begin{pmatrix}
softmax\text{(first row of x)} \
softmax\text{(second row of x)} \
... \
softmax\text{(last row of x)} \
\end{pmatrix} \tag{11}
$$
Python代码的实现:
import numpy as np
def softmax(x):
x_exp = np.exp(x)
x_sum = np.sum(x_exp, axis=1, keepdims=True)
print "x_sum = ", x_sum
s = x_exp / x_sum
return s
调用该函数:
if __name__ == '__main__':
x = np.array([
[9, 2, 5, 0, 0],
[7, 5, 0, 0, 0]])
print "softmax(x) = " + str(softmax(x))
输出结果如下:
x_sum = [[8260.88614278]
[1248.04631753]]
softmax(x) = [[9.80897665e-01 8.94462891e-04 1.79657674e-02 1.21052389e-04 1.21052389e-04]
[8.78679856e-01 1.18916387e-01 8.01252314e-04 8.01252314e-04 8.01252314e-04]]
numpy矩阵的运算
numpy计算矩阵的有三种:np.dot(),np.outer(),np.multiply()。它们的运算如下:
# coding=utf-8
import numpy as np
if __name__ == '__main__':
s1 = [[1,2,3],[4,5,6]]
s2 = [[2,2],[3,3],[4,4]]
# 跟线性代数计算矩阵一样,(1*15)*(15*1)=(1*1)
dot = np.dot(s1, s2)
print 'dot = ', dot
# s1第一个元素跟s2的每一个元素相乘作为第一行,s1第二个元素跟s2每一个元素相乘作为第二个元素....
outer = np.outer(s1, s2)
print 'outer = ', outer
x1 = [9, 2, 5, 0, 0, 7, 5, 0, 0, 0, 9, 2, 5, 0, 0]
x2 = [9, 2, 2, 9, 0, 9, 2, 5, 0, 0, 9, 2, 5, 0, 0]
# x1中的元素和x2中的元素一一对应相乘
mul = np.multiply(x1, x2)
print 'mul = ', mul
输出结果如下:
dot = [[20 20]
[47 47]]
outer = [[ 2 2 3 3 4 4]
[ 4 4 6 6 8 8]
[ 6 6 9 9 12 12]
[ 8 8 12 12 16 16]
[10 10 15 15 20 20]
[12 12 18 18 24 24]]
mul = [81 4 10 0 0 63 10 0 0 0 81 4 25 0 0]
损失函数
损失用于评估模型的性能。损失越大,你的预测$\hat{y}$就越不同于真实的值$y$。在深度学习中,您可以使用梯度下降等优化算法来训练模型并最大限度地降低成本。
L1损失函数
L1损失函数的公式如下:
$$
L_1(\hat{y}, y) = \sum_{i=0}^m|y^{(i)} - \hat{y}^{(i)}| \tag{12}
$$
Python代码实现:
import numpy as np
def L1(yhat, y):
loss = np.sum(abs(y - yhat))
return loss
调用该函数:
if __name__ == '__main__':
yhat = np.array([.9, 0.2, 0.1, .4, .9])
y = np.array([1, 0, 0, 1, 1])
print("L1 = " + str(L1(yhat, y)))
输入结果如下:
L1 = 1.1
L2损失函数
L2损失函数的公式如下:
$$
L_2(\hat{y},y) = \sum_{i=0}^m(y^{(i)} - \hat{y}^{(i)})^2 \tag{13}
$$
Python代码实现:
import numpy as np
def L2(yhat, y):
loss = np.sum(np.multiply((y - yhat), (y - yhat)))
return loss
调用该函数:
if __name__ == '__main__':
yhat = np.array([.9, 0.2, 0.1, .4, .9])
y = np.array([1, 0, 0, 1, 1])
print("L2 = " + str(L2(yhat, y)))
输入结果如下:
L2 = 0.43
参考资料
- https://baike.baidu.com/item/tanh
- https://baike.baidu.com/item/Sigmoid%E5%87%BD%E6%95%B0
- http://deeplearning.ai/
该笔记是学习吴恩达老师的课程写的。初学者入门,如有理解有误的,欢迎批评指正!