
《PaddlePaddle从入门到炼丹》六——生成对抗网络

@[TOC]
前言
我们上一章使用MNIST数据集进行训练,获得一个可以分类手写字体的模型。如果我们数据集的数量不够,不足于让模型收敛,最直接的是增加数据集。但是我们收集数据并进行标注是非常消耗时间了,而最近非常火的生成对抗网络就非常方便我们数据的收集。对抗生成网络可以根据之前的图片训练生成更多的图像,已达到以假乱真的目的。
训练并预测
创建一个GAN.py文件。首先导入所需要的Python包,其中matplotlib包是之后用于展示出生成的图片。
import numpy as np
import paddle
import paddle.fluid as fluid
import matplotlib.pyplot as plt
定义网络
生成对抗网络由生成器和判别器组合,下面的代码片段就是一个生成器,生成器的作用是尽可能生成满足判别器条件的图像。随着以上训练的进行,判别器不断增强自身的判别能力,而生成器也不断生成越来越逼真的图片,以欺骗判别器。生成器主要由两组全连接和BN层、两组转置卷积运算组成,其中最后一层的卷积层的卷积核数量是1,因为输出的图像是一个灰度图的手写字体图片。
# 定义生成器
def Generator(y, name="G"):
def deconv(x, num_filters, filter_size=5, stride=2, dilation=1, padding=2, output_size=None, act=None):
return fluid.layers.conv2d_transpose(input=x,
num_filters=num_filters,
output_size=output_size,
filter_size=filter_size,
stride=stride,
dilation=dilation,
padding=padding,
act=act)
with fluid.unique_name.guard(name + "/"):
# 第一组全连接和BN层
y = fluid.layers.fc(y, size=2048)
y = fluid.layers.batch_norm(y)
# 第二组全连接和BN层
y = fluid.layers.fc(y, size=128 * 7 * 7)
y = fluid.layers.batch_norm(y)
# 进行形状变换
y = fluid.layers.reshape(y, shape=(-1, 128, 7, 7))
# 第一组转置卷积运算
y = deconv(x=y, num_filters=128, act='relu', output_size=[14, 14])
# 第二组转置卷积运算
y = deconv(x=y, num_filters=1, act='tanh', output_size=[28, 28])
return y
判别器的作用是训练真实的数据集,然后使用训练真实数据集模型去判别生成器生成的假图片。这一过程可以理解判别器为一个二分类问题,判别器在训练真实数据集时,尽量让其输出概率为1,而训练生成器生成的假图片输出概率为0。这样不断给生成器压力,让其生成的图片尽量逼近真实图片,以至于真实到连判别器也无法判断这是真实图像还是假图片。以下判别器由三组卷积池化层和一个最后全连接层组成,全连接层的大小为1,输入一个二分类的结果。
# 判别器 Discriminator
def Discriminator(images, name="D"):
# 定义一个卷积池化组
def conv_pool(input, num_filters, act=None):
return fluid.nets.simple_img_conv_pool(input=input,
filter_size=5,
num_filters=num_filters,
pool_size=2,
pool_stride=2,
act=act)
with fluid.unique_name.guard(name + "/"):
y = fluid.layers.reshape(x=images, shape=[-1, 1, 28, 28])
# 第一个卷积池化组
y = conv_pool(input=y, num_filters=64, act='leaky_relu')
# 第一个卷积池化加回归层
y = conv_pool(input=y, num_filters=128)
y = fluid.layers.batch_norm(input=y, act='leaky_relu')
# 第二个卷积池化加回归层
y = fluid.layers.fc(input=y, size=1024)
y = fluid.layers.batch_norm(input=y, act='leaky_relu')
# 最后一个分类器输出
y = fluid.layers.fc(input=y, size=1, act='sigmoid')
return y
定义训练程序
定义四个Program和一个噪声维度,其中使用三个Program分别进行训练生成器生成图片、训练判别器识别真实图片、训练判别器识别生成器生成的假图片,还要一个Program是用于初始化参数的。噪声的作用是初始化生成图片。
# 创建判别器D识别生成器G生成的假图片程序
train_d_fake = fluid.Program()
# 创建判别器D识别真实图片程序
train_d_real = fluid.Program()
# 创建生成器G生成符合判别器D的程序
train_g = fluid.Program()
# 创建共同的一个初始化的程序
startup = fluid.Program()
# 噪声维度
z_dim = 100
获取Program中的独立参数,因为我们同时训练3个Program,其中训练生成器或训练判别器时,它们参数的更新不应该互相影响。就是训练判别器识别真实图片时,在更新判别器模型参数时,不要更新生成器模型的参数,同理更新生成器模型参数时,不要更新判别器的模型参数。
# 从Program获取prefix开头的参数名字
def get_params(program, prefix):
all_params = program.global_block().all_parameters()
return [t.name for t in all_params if t.name.startswith(prefix)]
定义一个判别器识别真实图片的程序,这里判别器传入的数据是真实的图片数据。这里使用的损失函数是fluid.layers.sigmoid_cross_entropy_with_logits(),这个损失函数是求它们在任务上的错误率,他们的类别是互不排斥的。所以无论真实图片的标签是什么,都不会影响模型识别为真实图片。这里更新的也只有判别器模型的参数,使用的优化方法是Adam。
# 训练判别器D识别真实图片
with fluid.program_guard(train_d_real, startup):
# 创建读取真实数据集图片的data,并且label为1
real_image = fluid.layers.data('image', shape=[1, 28, 28])
ones = fluid.layers.fill_constant_batch_size_like(real_image, shape=[-1, 1], dtype='float32', value=1)
# 判别器D判断真实图片的概率
p_real = Discriminator(real_image)
# 获取损失函数
real_cost = fluid.layers.sigmoid_cross_entropy_with_logits(p_real, ones)
real_avg_cost = fluid.layers.mean(real_cost)
# 获取判别器D的参数
d_params = get_params(train_d_real, "D")
# 创建优化方法
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=2e-4)
optimizer.minimize(real_avg_cost, parameter_list=d_params)
这里定义一个判别器识别生成器生成的图片的程序,这里是使用噪声的维度进行输入。这里判别器识别的是生成器生成的图片,这里使用的损失函数同样是fluid.layers.sigmoid_cross_entropy_with_logits()。这里更新的参数还是判别器模型的参数,也是使用Adam优化方法。
# 训练判别器D识别生成器G生成的图片为假图片
with fluid.program_guard(train_d_fake, startup):
# 利用创建假的图片data,并且label为0
z = fluid.layers.data(name='z', shape=[z_dim, 1, 1])
zeros = fluid.layers.fill_constant_batch_size_like(z, shape=[-1, 1], dtype='float32', value=0)
# 判别器D判断假图片的概率
p_fake = Discriminator(Generator(z))
# 获取损失函数
fake_cost = fluid.layers.sigmoid_cross_entropy_with_logits(p_fake, zeros)
fake_avg_cost = fluid.layers.mean(fake_cost)
# 获取判别器D的参数
d_params = get_params(train_d_fake, "D")
# 创建优化方法
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=2e-4)
optimizer.minimize(fake_avg_cost, parameter_list=d_params)
最后定义一个训练生成器生成图片的模型,这里也克隆一个预测程序,用于之后在训练的时候输出预测的图片。损失函数和优化方法都一样,但是要更新的参数是生成器的模型参。
# 训练生成器G生成符合判别器D标准的假图片
with fluid.program_guard(train_g, startup):
# 噪声生成图片为真实图片的概率,Label为1
z = fluid.layers.data(name='z', shape=[z_dim, 1, 1])
ones = fluid.layers.fill_constant_batch_size_like(z, shape=[-1, 1], dtype='float32', value=1)
# 生成图片
fake = Generator(z)
# 克隆预测程序
infer_program = train_g.clone(for_test=True)
# 生成符合判别器的假图片
p = Discriminator(fake)
# 获取损失函数
g_cost = fluid.layers.sigmoid_cross_entropy_with_logits(p, ones)
g_avg_cost = fluid.layers.mean(g_cost)
# 获取G的参数
g_params = get_params(train_g, "G")
# 只训练G
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=2e-4)
optimizer.minimize(g_avg_cost, parameter_list=g_params)
训练并预测
通过由噪声来生成假的图片数据输入。
# 噪声生成
def z_reader():
while True:
yield np.random.normal(0.0, 1.0, (z_dim, 1, 1)).astype('float32')
读取真实图片的数据集,这里去除了数据集中的label数据,因为label在这里使用不上,这里不考虑标签分类问题。
# 读取MNIST数据集,不使用label
def mnist_reader(reader):
def r():
for img, label in reader():
yield img.reshape(1, 28, 28)
return r
把预测的图片保存到本地目录上,如果使用jupyter,可用把图片打印到页面上。
# 显示图片
def show_image_grid(images, pass_id=None):
# fig = plt.figure(figsize=(5, 5))
# fig.suptitle("Pass {}".format(pass_id))
# gs = plt.GridSpec(8, 8)
# gs.update(wspace=0.05, hspace=0.05)
for i, image in enumerate(images[:64]):
# 保存生成的图片
plt.imsave("image/test_%d.png" % i, image[0])
# 以下代码在jupyter可用
# ax = plt.subplot(gs[i])
# plt.axis('off')
# ax.set_xticklabels([])
# ax.set_yticklabels([])
# ax.set_aspect('equal')
# plt.imshow(image[0], cmap='Greys_r')
# plt.show()
将真实数据和噪声生成的数据的生成一个reader。
# 生成真实图片reader
mnist_generator = paddle.batch(
paddle.reader.shuffle(mnist_reader(paddle.dataset.mnist.train()), 30000), batch_size=128)
# 生成假图片的reader
z_generator = paddle.batch(z_reader, batch_size=128)()
创建一个执行器,这里使用的GPU进行训练,因为该网络比较大,使用CPU训练速度会非常慢。如果读者没有GPU只有,可以取消注释place = fluid.CPUPlace()这行代码,并注释place = fluid.CUDAPlace(0)这行代码,就可以使用CPU进行训练了。
# 创建执行器
# place = fluid.CPUPlace()
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
# 初始化参数
exe.run(startup)
获取测试需要的噪声数据,使用这些数据进行预测,获取预测的图片。
# 测试噪声数据
test_z = np.array(next(z_generator))
开始训练,这里同时训练了3个程序,分别是训练判别器D识别生成器G生成的假图片、训练判别器D识别真实图片、训练生成器G生成符合判别器D标准的假图片。通过不断更新判别器的参数,使得判别器的识别能力越来越强。不断更新生成器的参数,使得生成器生成的图像越来越逼近真实图像。在每一轮训练结束后,进行一次预测,输入生成器生成的图片并显示出来。
# 开始训练
for pass_id in range(5):
for i, real_image in enumerate(mnist_generator()):
# 训练判别器D识别生成器G生成的假图片
r_fake = exe.run(program=train_d_fake,
fetch_list=[fake_avg_cost],
feed={'z': np.array(next(z_generator))})
# 训练判别器D识别真实图片
r_real = exe.run(program=train_d_real,
fetch_list=[real_avg_cost],
feed={'image': np.array(real_image)})
# 训练生成器G生成符合判别器D标准的假图片
r_g = exe.run(program=train_g,
fetch_list=[g_avg_cost],
feed={'z': np.array(next(z_generator))})
print("Pass:%d,fake_avg_cost:%f, real_avg_cost:%f, g_avg_cost:%f" % (pass_id, r_fake[0][0], r_real[0][0], r_g[0][0]))
# 测试生成的图片
r_i = exe.run(program=infer_program,
fetch_list=[fake],
feed={'z': test_z})
# 显示生成的图片
show_image_grid(r_i[0], pass_id)
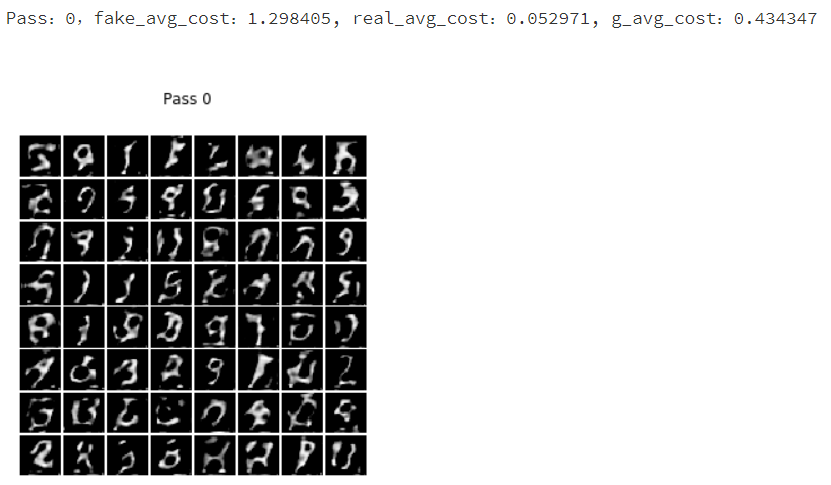
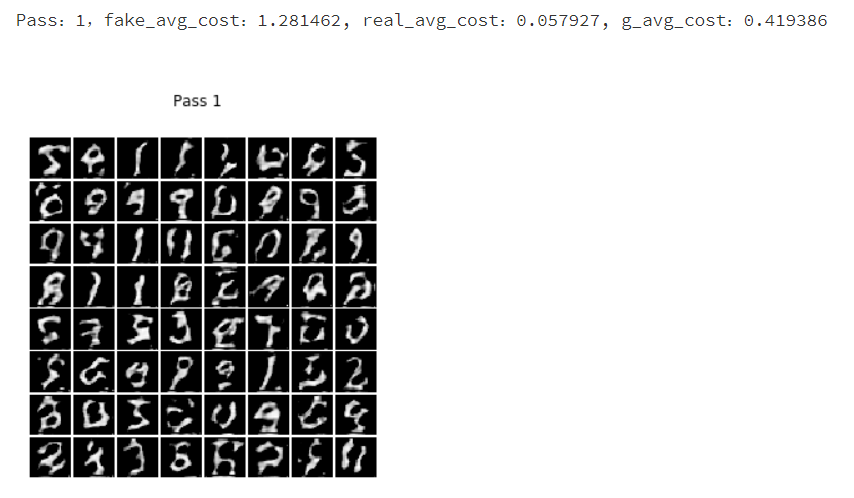
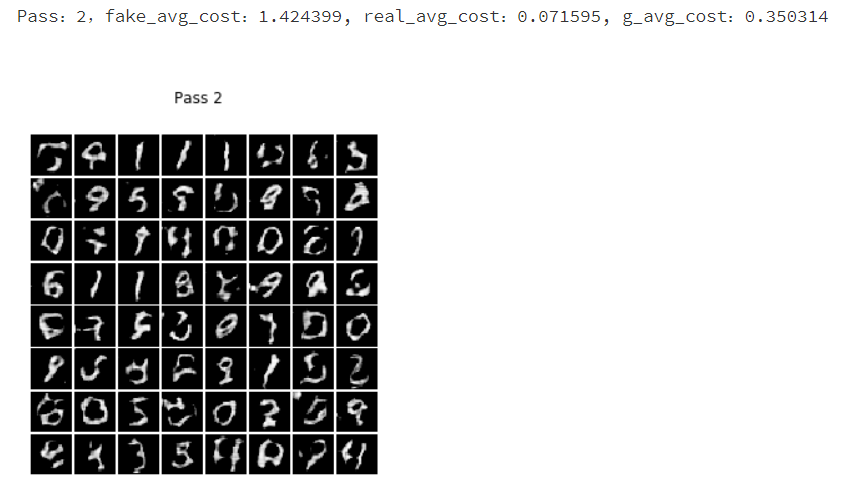
到处为止,本章就结束了。通过学习本章,是不是觉得生成对抗网络非常神奇呢,读者可以参数一下其他的数据,通过生成对抗网络生成更多有趣的图像数据集。从本章可以了解到深度学习的强大,但深度学习远远不止这些,在下一章,我们使用深度学习中的强化学习,通过训练获取模型,使用模型来自己玩一个小游戏。
同步到百度AI Studio平台:http://aistudio.baidu.com/aistudio/projectdetail/29365
同步到科赛网K-Lab平台:https://www.kesci.com/home/project/5bf8cd7c954d6e001066d82e
项目代码GitHub地址:https://github.com/yeyupiaoling/LearnPaddle2/tree/master/note6
注意: 最新代码以GitHub上的为准
参考资料
- https://www.cnblogs.com/max-hu/p/7129188.html
- https://github.com/oraoto/learn_ml/blob/master/paddle/gan-mnist-split.ipynb
- https://blog.csdn.net/somtian/article/details/72126328
- http://www.paddlepaddle.org/documentation/api/zh/1.1/layers.html#sigmoid-cross-entropy-with-logits
标题:《PaddlePaddle从入门到炼丹》六——生成对抗网络
作者:yeyupiaoling
地址:https://yeyupiaoling.cn/articles/1584974661687.html