> 原文博客:Doi技術團隊
鏈接地址:https://blog.doiduoyi.com/authors/1584446358138
初心:記錄優秀的Doi技術團隊學習經歷
*本篇文章基於 PaddlePaddle 0.10.0、Python 2.7
前言¶
車牌識別的應用場景有很多,比如在停車場。通過車牌識別登記入庫和出庫的車輛的情況,並計算該車停留時間,然後折算費用。還可以在公路上識別來往的車輛,方便交警的檢查等等。接下來我們就是使用PaddlePaddle來做一個車牌識別,我們直接通過段端到端識別,不用分割即可完成識別。在閱讀這篇文章時,你應該先閱讀上一篇驗證碼端到端的識別,在上一篇的很多細節,在本篇中不會很說得很細。
車牌的採集¶
車牌的下載¶
在做車牌識別之前,我們要先數據。這些車牌數據我打算從百度圖片中獲取,所以我先編寫一個程序來幫我們下載車牌圖像。
# -*- coding:utf-8 -*-
import re
import uuid
import requests
import os
class DownloadImages:
def __init__(self, download_max, key_word):
self.download_sum = 0
self.download_max = download_max
self.key_word = key_word
self.save_path = '../images/download/'
def start_download(self):
self.download_sum = 0
gsm = 80
str_gsm = str(gsm)
pn = 0
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
while self.download_sum < self.download_max:
str_pn = str(self.download_sum)
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&' \
'word=' + self.key_word + '&pn=' + str_pn + '&gsm=' + str_gsm + '&ct=&ic=0&lm=-1&width=0&height=0'
print url
result = requests.get(url)
self.downloadImages(result.text)
print '下載完成'
def downloadImages(self, html):
img_urls = re.findall('"objURL":"(.*?)",', html, re.S)
print '找到關鍵詞:' + self.key_word + '的圖片,現在開始下載圖片...'
for img_url in img_urls:
print '正在下載第' + str(self.download_sum + 1) + '張圖片,圖片地址:' + str(img_url)
try:
pic = requests.get(img_url, timeout=50)
pic_name = self.save_path + '/' + str(uuid.uuid1()) + '.jpg'
with open(pic_name, 'wb') as f:
f.write(pic.content)
self.download_sum += 1
if self.download_sum >= self.download_max:
break
except Exception, e:
print '【錯誤】當前圖片無法下載,%s' % e
continue
if __name__ == '__main__':
downloadImages = DownloadImages(100, '車牌')
downloadImages.start_download()
通過上面這個程序,只要給定義下載的數據和“車牌“這個關鍵字,就可以開始下載車牌了,下載好的車牌會放在images/download/這個路徑下。
命名車牌照片¶
我們下載好的圖像還不能直接使用,還有經過幾步的處理。下載好的車牌圖像不是每張都有車牌的,還有很多無效的圖像,我們還有刪除這些照片。
剩下的圖像我們要把它命名爲車牌對應的內容,比如下面的圖像命名爲遼B2723L,並存放在images/src_temp/下

車牌定位¶
原始的圖像包括很多其他的噪聲,會影響到訓練的效果,加上我們的數據集非常小,所以我們要裁剪多餘的地方,纔會使得我們的模型儘可能收斂得更小。
當然這麼費勁的工作不能全部由我們手工去裁剪,我們要編寫一個程序,讓它來幫我們裁剪圖像。
對車牌的裁剪比較複雜,我們把它分成4個部分來做:
1. 首先將彩色的車牌圖像轉換成灰度圖
2. 灰度化的圖像利用高斯平滑處理後,再對其進行中直濾波
3. 使用Sobel算子對圖像進行邊緣檢測
4. 對二值化的圖像進行腐蝕,膨脹,開運算,閉運算的形態學組合變換
5. 對形態學變換後的圖像進行輪廓查找,根據車牌的長寬比提取車牌
一、灰度化
# 轉化成灰度圖
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)

二、高斯平滑和中值濾波
# 高斯平滑
gaussian = cv2.GaussianBlur(gray, (3, 3), 0, 0, cv2.BORDER_DEFAULT)

# 中值濾波
median = cv2.medianBlur(gaussian, 5)

三、Sobel算子對圖像進行邊緣檢測
# Sobel算子,X方向求梯度
sobel = cv2.Sobel(median, cv2.CV_8U, 1, 0, ksize=3)
四、二值化
# 二值化
ret, binary = cv2.threshold(sobel, 170, 255, cv2.THRESH_BINARY)
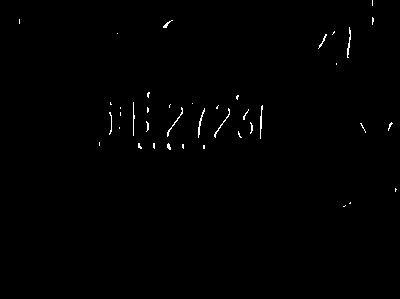
五、形態變換
# 膨脹和腐蝕操作的核函數
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 1))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 7))
# 膨脹一次,讓輪廓突出
dilation = cv2.dilate(binary, element2, iterations=1)
# 腐蝕一次,去掉細節
erosion = cv2.erode(dilation, element1, iterations=1)
# 再次膨脹,讓輪廓明顯一些
dilation2 = cv2.dilate(erosion, element2, iterations=iterations)

最後裁剪
box = region[0]
ys = [box[0, 1], box[1, 1], box[2, 1], box[3, 1]]
xs = [box[0, 0], box[1, 0], box[2, 0], box[3, 0]]
ys_sorted_index = np.argsort(ys)
xs_sorted_index = np.argsort(xs)
x1 = box[xs_sorted_index[0], 0]
x2 = box[xs_sorted_index[3], 0]
y1 = box[ys_sorted_index[0], 1]
y2 = box[ys_sorted_index[3], 1]
img_plate = img[y1:y2, x1:x2]
cv2.imwrite('../data/data_temp/%s.jpg' % self.img_name, img_plate)

在形態變換中,我先是使用了6次迭代膨脹,如果6次迭代膨脹沒能裁剪到圖像,就使用3次迭代膨脹的方式去變換。如果還不能就真的沒有辦法了,只能使用手工裁剪了。還有不得不說的是這個程序雖然優化了很多,但是裁剪的效果還是不太好,剩下沒有成功裁剪的還是要手動裁剪,使用Windows 10 的自帶圖像查看器可以很方便裁剪。在第11章的自定義圖像數據集實現目標檢測中就介紹使用神經網絡定位車牌,可以使用神經網絡預測的結果定位車牌,識別率會高很多。
裁剪後的圖像存放在data/data_temp/,等待分配給訓練和測試的數據集。
灰度化和分配數據集¶
我們裁剪後的圖像還是彩色的,並存放在data/data_temp/,我們現在要把他們灰度化和分配給訓練的data/train_data和測試的data/test_data,所以要編寫一個程序批量處理他們。
# coding=utf-8
import os
from PIL import Image
def Image2GRAY(path):
# 獲取臨時文件夾中的所有圖像路徑
imgs = os.listdir(path)
i = 0
for img in imgs:
# 每10個數據取一個作爲測試數據,剩下的作爲訓練數據
if i % 10 == 0:
# 使圖像灰度化並保存
im = Image.open(path + '/' + img).convert('L')
im = im.resize((180, 80), Image.ANTIALIAS)
im.save('../data/test_data/' + img)
else:
# 使圖像灰度化並保存
im = Image.open(path + '/' + img).convert('L')
im = im.resize((180, 80), Image.ANTIALIAS)
im.save('../data/train_data/' + img)
i = i + 1
if __name__ == '__main__':
# 臨時數據存放路徑
path = '../data/data_temp'
Image2GRAY(path)
現在訓練數據和測試數據都有了,可以開始讀取數據了
數據的讀取¶
生成list文件¶
跟上一篇文章中說的一樣,這次我們還是使用Tab鍵分開圖像路徑和和對應的label,所以我們的程序跟之前一樣
# coding=utf-8
import os
class CreateDataList:
def __init__(self):
pass
def createDataList(self, data_path, isTrain):
# 判斷生成的列表是訓練圖像列表還是測試圖像列表
if isTrain:
list_name = 'trainer.list'
else:
list_name = 'test.list'
list_path = os.path.join(data_path, list_name)
# 判斷該列表是否存在,如果存在就刪除,避免在生成圖像列表時把該路徑也寫進去了
if os.path.exists(list_path):
os.remove(list_path)
# 讀取所有的圖像路徑,此時圖像列表不存在,就不用擔心寫入非圖像文件路徑了
imgs = os.listdir(data_path)
for img in imgs:
name = img.split('.')[0]
with open(list_path, 'a') as f:
# 寫入圖像路徑和label,用Tab隔開
f.write(img + '\t' + name + '\n')
if __name__ == '__main__':
createDataList = CreateDataList()
# 生成訓練圖像列表
createDataList.createDataList('../data/train_data/', True)
# 生成測試圖像列表
createDataList.createDataList('../data/test_data/', False)
同樣會在data/train_data生成圖像列表trainer.list,會在data/test_data生成圖像列表test.list。
讀取數據成list¶
然後通過以下的程序生成對應的list
def get_file_list(image_file_list):
'''
生成用於訓練和測試數據的文件列表。
:param image_file_list: 圖像文件和列表文件的路徑
:type image_file_list: str
'''
dirname = os.path.dirname(image_file_list)
path_list = []
with open(image_file_list) as f:
for line in f:
# 使用Tab鍵分離路徑和label
line_split = line.strip().split('\t')
filename = line_split[0].strip()
path = os.path.join(dirname, filename)
label = line_split[1].strip()
if label:
path_list.append((path, label))
return path_list
通過上一步生成的list文件,再調用這個程序就可以生成圖像路徑和標籤的list了
# 獲取訓練列表
train_file_list = get_file_list(train_file_list_path)
# 獲取測試列表
test_file_list = get_file_list(test_file_list_path)
生成和讀取標籤字典¶
有了list還不行,還要有一個標籤字典,這個標籤字典包括訓練label的所有字符,這個標籤字典是之後訓練和預測都要使用的。我們要生成一個標籤字典格式是:
字符 出現次數
字符 出現次數
字符 出現次數
字符 出現次數
要注意的是,更上次不一樣,這次的label有中文,所以在保存字典的時候要注意中文編碼的問題。
def build_label_dict(file_list, save_path):
"""
從訓練數據建立標籤字典
:param file_list: 包含標籤的訓練數據列表
:type file_list: list
:params save_path: 保存標籤字典的路徑
:type save_path: str
"""
values = defaultdict(int)
for path, label in file_list:
# 加上unicode(label, "utf-8")解決中文編碼問題
for c in unicode(label, "utf-8"):
if c:
values[c] += 1
values['<unk>'] = 0
# 解決寫入文本文件的中文編碼問題
f = codecs.open(save_path,'w','utf-8')
for v, count in sorted(values.iteritems(), key=lambda x: x[1], reverse=True):
content = "%s\t%d\n" % (v, count)
# print content
f.write(content)
然後把訓練數據傳給這個函數就可以生成字典了
build_label_dict(train_file_list, label_dict_path)
然後是讀取字典
def load_dict(dict_path):
"""
從字典路徑加載標籤字典
:param dict_path: 標籤字典的路徑
:type dict_path: str
"""
return dict((line.strip().split("\t")[0], idx)
for idx, line in enumerate(open(dict_path, "r").readlines()))
訓練和測試數據的讀取¶
處理好標籤字典之後,現在就要處理訓練數據和測試數據的讀取問題了,在上幾步我麼拿到了train_file_list,只有這個list是不能直接用了給PaddlePaddle讀取訓練的,我們還有處理一下。
# coding=utf-8
import cv2
import paddle.v2 as paddle
class Reader(object):
def __init__(self, char_dict, image_shape):
'''
:param char_dict: 標籤的字典類
:type char_dict: class
:param image_shape: 圖像的固定形狀
:type image_shape: tuple
'''
self.image_shape = image_shape
self.char_dict = char_dict
def train_reader(self, file_list):
'''
訓練讀取數據
:param file_list: 用預訓練的圖像列表,包含標籤和圖像路徑
:type file_list: list
'''
def reader():
UNK_ID = self.char_dict['<unk>']
for image_path, label in file_list:
# 解決key爲中文問題
label2 = []
for c in unicode(label, "utf-8"):
for dict1 in self.char_dict:
if c == dict1.decode('utf-8'):
label2.append(self.char_dict[dict1])
yield self.load_image(image_path), label2
return reader
def load_image(self, path):
'''
加載圖像並將其轉換爲一維向量
:param path: 圖像數據的路徑
:type path: str
'''
image = paddle.image.load_image(path,is_color=False)
# 將所有圖像調整爲固定形狀
if self.image_shape:
image = cv2.resize(
image, self.image_shape, interpolation=cv2.INTER_CUBIC)
image = image.flatten() / 255.
return image
值得留意的是train_reader(self, file_list)這函數,因爲標籤字典中有中文,所以字典中有的key是中文的,所以要做一些編碼的處理。
然後通過下面的代碼就可以拿到reader了
# 獲取測試數據的reader
test_reader = paddle.batch(
my_reader.train_reader(test_file_list),
batch_size=BATCH_SIZE)
# 獲取訓練數據的reader
train_reader = paddle.batch(
paddle.reader.shuffle(
my_reader.train_reader(train_file_list),
buf_size=1000),
batch_size=BATCH_SIZE)
定義神經網絡¶
有了訓練數據之後,我們就要定義神經網絡了。
下面是數據大小和label的定義
# 獲取字典大小
dict_size = len(char_dict)
以下就是類初始化的數據和定義數據和label的操作:
class Model(object):
def __init__(self, num_classes, shape, is_infer=False):
'''
:param num_classes: 字符字典的大小
:type num_classes: int
:param shape: 輸入圖像的大小
:type shape: tuple of 2 int
:param is_infer: 是否用於預測
:type shape: bool
'''
self.num_classes = num_classes
self.shape = shape
self.is_infer = is_infer
self.image_vector_size = shape[0] * shape[1]
self.__declare_input_layers__()
self.__build_nn__()
def __declare_input_layers__(self):
'''
定義輸入層
'''
# 圖像輸入爲一個浮動向量
self.image = paddle.layer.data(
name='image',
type=paddle.data_type.dense_vector(self.image_vector_size),
# shape是(寬度,高度)
height=self.shape[1],
width=self.shape[0])
# 將標籤輸入爲ID列表
if not self.is_infer:
self.label = paddle.layer.data(
name='label',
type=paddle.data_type.integer_value_sequence(self.num_classes))
定義網絡模型,該網絡模型
首先是通過CNN獲取圖像的特徵,
然後使用這些特徵來輸出展開成一系列特徵向量,
然後使用RNN向前和向後捕獲序列信息,
然後將RNN的輸出映射到字符分佈,
最後使用扭曲CTC來計算CTC任務的成本,獲得了cost和額外層。
def __build_nn__(self):
'''
建立網絡拓撲
'''
# 通過CNN獲取圖像特徵
def conv_block(ipt, num_filter, groups, num_channels=None):
return paddle.networks.img_conv_group(
input=ipt,
num_channels=num_channels,
conv_padding=1,
conv_num_filter=[num_filter] * groups,
conv_filter_size=3,
conv_act=paddle.activation.Relu(),
conv_with_batchnorm=True,
pool_size=2,
pool_stride=2, )
# 因爲是灰度圖所以最後一個參數是1
conv1 = conv_block(self.image, 16, 2, 1)
conv2 = conv_block(conv1, 32, 2)
conv3 = conv_block(conv2, 64, 2)
conv_features = conv_block(conv3, 128, 2)
# 將CNN的輸出展開成一系列特徵向量。
sliced_feature = paddle.layer.block_expand(
input=conv_features,
num_channels=128,
stride_x=1,
stride_y=1,
block_x=1,
block_y=11)
# 使用RNN向前和向後捕獲序列信息。
gru_forward = paddle.networks.simple_gru(
input=sliced_feature, size=128, act=paddle.activation.Relu())
gru_backward = paddle.networks.simple_gru(
input=sliced_feature,
size=128,
act=paddle.activation.Relu(),
reverse=True)
# 將RNN的輸出映射到字符分佈。
self.output = paddle.layer.fc(input=[gru_forward, gru_backward],
size=self.num_classes + 1,
act=paddle.activation.Linear())
self.log_probs = paddle.layer.mixed(
input=paddle.layer.identity_projection(input=self.output),
act=paddle.activation.Softmax())
# 使用扭曲CTC來計算CTC任務的成本。
if not self.is_infer:
# 定義cost
self.cost = paddle.layer.warp_ctc(
input=self.output,
label=self.label,
size=self.num_classes + 1,
norm_by_times=True,
blank=self.num_classes)
# 定義額外層
self.eval = paddle.evaluator.ctc_error(input=self.output, label=self.label)
最後通過調用該類就可以獲取到模型了,傳入的參數是
dict_size是標籤字典的大小,在上面有介紹是用來生成label的
IMAGE_SHAPE這個是圖像的寬度和高度,格式是:(寬度,高度)
model = Model(dict_size, IMAGE_SHAPE, is_infer=False)
開始訓練¶
定義訓練器¶
有了數據和神經網絡,我們就可以開始訓練,在訓練之前,我們先要有一個訓練器,接下來我們要定義一個訓練器
# 初始化PaddlePaddle
paddle.init(use_gpu=True, trainer_count=1)
# 定義網絡拓撲
model = Model(dict_size, IMAGE_SHAPE, is_infer=False)
# 創建優化方法
optimizer = paddle.optimizer.Momentum(momentum=0)
# 創建訓練參數
params = paddle.parameters.create(model.cost)
# 定義訓練器
trainer = paddle.trainer.SGD(cost=model.cost,
parameters=params,
update_equation=optimizer,
extra_layers=model.eval)
啓動訓練¶
有了數據和神經網絡模型,也有了訓練器,現在就可以開始訓練了
# 開始訓練
trainer.train(reader=train_reader,
feeding=feeding,
event_handler=event_handler,
num_passes=5000)
訓練的時候我們要有一個訓練事件來把我們保存訓練好的參數
# 訓練事件
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print("Pass %d, batch %d, Samples %d, Cost %f, Eval %s" %
(event.pass_id, event.batch_id, event.batch_id *
BATCH_SIZE, event.cost, event.metrics))
if isinstance(event, paddle.event.EndPass):
result = trainer.test(reader=test_reader, feeding=feeding)
print("Test %d, Cost %f, Eval %s" % (event.pass_id, result.cost, result.metrics))
# 檢查保存model的路徑是否存在,如果不存在就創建
if not os.path.exists(model_save_dir):
os.mkdir(model_save_dir)
with gzip.open(
os.path.join(model_save_dir, "params_pass.tar.gz"), "w") as f:
trainer.save_parameter_to_tar(f)
這個項目依賴的 warp CTC 只有CUDA的實現,所以只支持 GPU 運行,要運行該項目就要搭建PaddlePaddle的GPU版本。如果你使用百度深度學習的GPU集羣,要看看上一篇安裝libwarpctc.so庫部分。
在訓練時會輸出這樣類似的日誌:
Pass 0, batch 0, Samples 0, Cost 45.893759, Eval {}
Test 0, Cost 27.545489, Eval {}
Pass 1, batch 0, Samples 0, Cost 28.823596, Eval {}
Test 1, Cost 25.830573, Eval {}
Pass 2, batch 0, Samples 0, Cost 26.331317, Eval {}
Test 2, Cost 25.292363, Eval {}
Pass 3, batch 0, Samples 0, Cost 23.742380, Eval {}
Test 3, Cost 24.762170, Eval {}
開始預測¶
經過差不多1000pass之後,我們可以使用保存好的參數來做預測了
def infer(img_path, model_path, image_shape, label_dict_path):
# 獲取標籤字典
char_dict = load_dict(label_dict_path)
# 獲取反轉的標籤字典
reversed_char_dict = load_reverse_dict(label_dict_path)
# 獲取字典大小
dict_size = len(char_dict)
# 獲取reader
my_reader = Reader(char_dict=char_dict, image_shape=image_shape)
# 初始化PaddlePaddle
paddle.init(use_gpu=True, trainer_count=1)
# 獲取網絡模型
model = Model(dict_size, image_shape, is_infer=True)
# 加載訓練好的參數
parameters = paddle.parameters.Parameters.from_tar(gzip.open(model_path))
# 獲取預測器
inferer = paddle.inference.Inference(output_layer=model.log_probs, parameters=parameters)
# 裁剪車牌
cutPlateNumber = CutPlateNumber()
cutPlateNumber.strat_crop(img_path, True)
# 加載裁剪後的車牌
test_batch = [[my_reader.load_image('../images/infer.jpg')]]
# 開始預測
return start_infer(inferer, test_batch, reversed_char_dict)
跟之前的不一樣的是,我們要預測的車牌也要經過裁剪纔可以很好地預測
# 裁剪車牌
cutPlateNumber = CutPlateNumber()
cutPlateNumber.strat_crop(img_path, True)
# 加載裁剪後的車牌
test_batch = [[my_reader.load_image('../images/infer.jpg')]]
在裁剪的時候,我們把要預測的圖像專門保存起來,等待預測的
if is_infer:
# 如果是用於預測的圖像,就給定文件名
cv2.imwrite('../images/infer.jpg', img_plate)
獲得PaddlePaddle的預測器和圖像的一維向量之後,我們就可以開始預測了
def start_infer(inferer, test_batch, reversed_char_dict):
# 獲取初步預測結果
infer_results = inferer.infer(input=test_batch)
num_steps = len(infer_results) // len(test_batch)
probs_split = [
infer_results[i * num_steps:(i + 1) * num_steps]
for i in range(0, len(test_batch))]
# 最佳路徑解碼
result = ''
for i, probs in enumerate(probs_split):
result = ctc_greedy_decoder(
probs_seq=probs, vocabulary=reversed_char_dict)
return result
預測出來的是字典編號,我們要通過這些編號反轉的標籤字典,獲得對應的字符:
def load_reverse_dict(dict_path):
"""
從字典路徑加載反轉的標籤字典
:param dict_path: 標籤字典的路徑
:type dict_path: str
"""
return dict((idx, line.strip().split("\t")[0])
for idx, line in enumerate(open(dict_path, "r").readlines()))
還有我們在預測是要獲得最優的預測路徑,通過下面的代碼獲取最優的解碼
def ctc_greedy_decoder(probs_seq, vocabulary):
"""CTC貪婪(最佳路徑)解碼器。
由最可能的令牌組成的路徑被進一步後處理
刪除連續的重複和所有的空白。
:param probs_seq: 每個詞彙表上概率的二維列表字符。
每個元素都是浮點概率列表爲一個字符。
:type probs_seq: list
:param vocabulary: 詞彙表
:type vocabulary: list
:return: 解碼結果字符串
:rtype: baseline
"""
# 尺寸驗證
for probs in probs_seq:
if not len(probs) == len(vocabulary) + 1:
raise ValueError("probs_seq dimension mismatchedd with vocabulary")
# argmax以獲得每個時間步長的最佳指標
max_index_list = list(np.array(probs_seq).argmax(axis=1))
# 刪除連續的重複索引
index_list = [index_group[0] for index_group in groupby(max_index_list)]
# 刪除空白索引
blank_index = len(vocabulary)
index_list = [index for index in index_list if index != blank_index]
# 將索引列表轉換爲字符串
return ''.join([vocabulary[index] for index in index_list])
最後調用該預測函數就可以預測了
if __name__ == "__main__":
# 要預測的圖像
img_path = '../data/test_data/京CX8888.jpg'
# 模型的路徑
model_path = '../models/params_pass.tar.gz'
# 圖像的大小
image_shape = (180, 80)
# 標籤的路徑
label_dict_path = '../data/label_dict.txt'
# 獲取預測結果
result = infer(img_path, model_path, image_shape, label_dict_path)
print '預測結果:%s' % result
預測的結果輸出的日誌:
預測結果:京CX8888
訓練數據太少了,訓練出來的模型不是很好,存在過擬合現象。這種情況可以通過增加訓練數據,可以避免過擬合。筆者做這些車牌已經很費勁了,雖然只要250多張,但是花了不少時間,如果讀者想提高識別準確率,可以通過增加數據量來訓練更好的模型。
上一章:《我的PaddlePaddle學習之路》筆記六——驗證碼端到端的識別¶
下一章:《我的PaddlePaddle學習之路》筆記八——場景文字識別¶
項目代碼¶
GitHub地址:https://github.com/yeyupiaoling/LearnPaddle
參考資料¶
- http://paddlepaddle.org/
- https://www.jianshu.com/p/fcfbd3131b84
- http://blog.csdn.net/louzhengzhai/article/details/72802978
- http://blog.csdn.net/w1573007/article/details/77199733