Preface¶
The previous article introduced a highly accurate speech recognition framework, but it could only recognize real-time short audio. If you want to recognize a very long audio file, lasting tens of minutes or even hours, the previous framework won’t work. Therefore, this article will show you how to build a long speech recognition service that can process audio and video of arbitrary lengths. Moreover, the recognition results can include the start and end times of each sentence, which can be used for subtitles and other applications.
Video Tutorial: Build a Speech Recognition Service with Three Commands, Easily Recognize Audio/Video of Several Hours!
Start Docker Service¶
First, upload the entire folder to your server and execute the following commands in that directory:
Compile the Docker container:
sudo docker build -t offline_asr .
Modify permissions:
sudo chmod +x run_server.sh
Execute the startup command in the project root directory:
sudo docker run -p 10095:10095 -itd --privileged=true --name offline_asr -v $PWD/:/workspace/websocket offline_asr
To restart the service if it was shut down earlier, run:
sudo docker start offline_asr
For auto-start on boot, add the above command to the /etc/rc.local startup script.
Test the Service¶
After starting the service, run the following command to test if it’s working properly:
python client.py --wav_path=test.wav
The output result will include start and end timestamps (in milliseconds) for each sentence:
【../data/test.wav】Result: [{'text': '近几年,', 'start': '710', 'end': '1569'}, {'text': '不但我用书给女儿压岁,', 'start': '1569', 'end': '3550'}, {'text': '也劝说亲朋不要给女儿压岁钱而改送压岁书。', 'start': '3550', 'end': '7935'}]
Build HTTP Service¶
The above setup uses a WebSocket service, which is inconvenient to use directly. Below is a program to convert WebSocket to HTTP, along with a web page for uploading audio/video to get recognition results. Run the HTTP service with:
python server.py
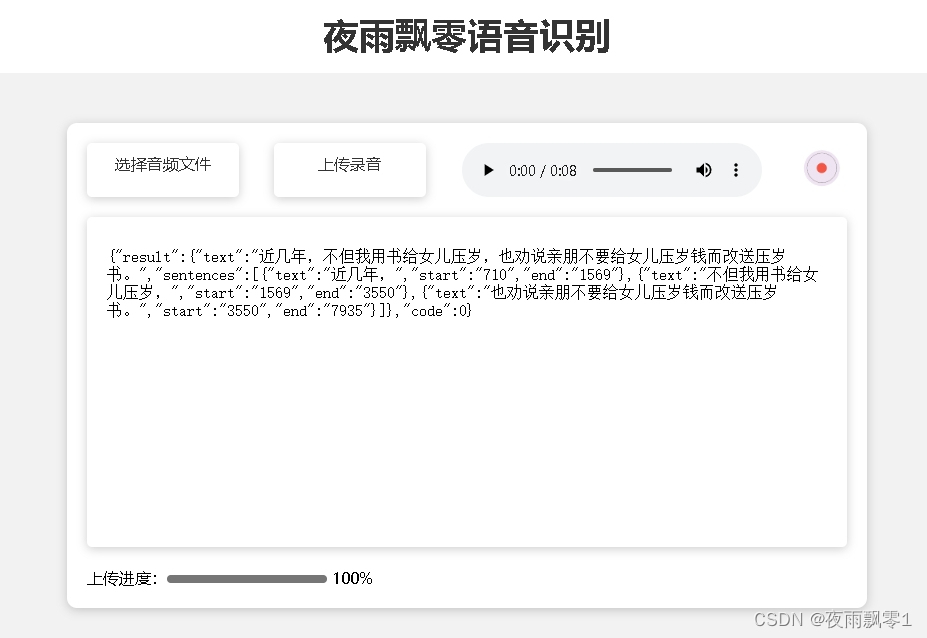
Visit http://192.168.0.100:6060 to open the page. You can upload WAV, MP3, MP4, etc., and it also supports recording for recognition. The returned result includes timestamps for each sentence:
{
"result": {
"text": "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱而改送压岁书。",
"sentences": [
{
"text": "近几年,",
"start": "710",
"end": "1569"
},
{
"text": "不但我用书给女儿压岁,",
"start": "1569",
"end": "3550"
},
{
"text": "也劝说亲朋不要给女儿压岁钱而改送压岁书。",
"start": "3550",
"end": "7935"
}
]
},
"code": 0
}
Page Screenshot:
Scan the QR code to join the knowledge planet and search for “FunASR Long Audio/Video Speech Recognition Service” to obtain the source code.