PaddlePaddle-SSD¶
SSD, short for Single Shot MultiBox Detector, is an object detection algorithm proposed by Wei Liu at ECCV 2016. It has become one of the primary detection frameworks to date. Compared to Faster R-CNN, it offers a significant speed advantage, and compared to YOLO V1, it has a notable mAP advantage. This open-source implementation is based on PaddlePaddle and references the ssd implementation under PaddlePaddle’s models. It includes MobileNetSSD, MobileNetV2SSD, VGGSSD, and ResNetSSD. It uses VOC-formatted datasets and provides pre-trained models and prediction models for VOC data.
Quick Start¶
- Store your image dataset in the
dataset/imagesdirectory and annotation data in thedataset/annotationsdirectory. - Execute the
create_data_list.pyprogram to generate the data list. - Download the pre-trained model from the table below and extract it to the
pretraineddirectory. - Modify the parameters in
config.py, where the most important parameters areclass_num,use_model, andpretrained_model.
-class_numincludes the background category, so for 20 VOC classes, this value should be 21.
-use_modelspecifies the model to use, with options: resnet_ssd, mobilenet_v2_ssd, mobilenet_v1_ssd, vgg_ssd.
-pretrained_modelis the path to the pre-trained model. - Run the
train.pyprogram to start training. The saved model will be updated after each training epoch, and training can be stopped at any time. - Execute
infer.pyto predict images. The path to the prediction model is configured inconfig.py.

Model Download¶
| Model Name | Dataset Used | Pre-trained Model | Prediction Model |
|---|---|---|---|
| VOC Pre-trained Model for VGG_SSD | pascalvoc | Download | Download |
| VOC Pre-trained Model for ResNet_SSD | pascalvoc | Download | Download |
| VOC Pre-trained Model for MobileNet_V1_SSD | pascalvoc | Download | Download |
| VOC Pre-trained Model for MobileNet_V2_SSD | pascalvoc | Download | Download |
SSD Model Introduction¶
SSD, or Single Shot MultiBox Detector, is a one-stage object detection algorithm proposed in 2016. Compared to two-stage detectors like Faster R-CNN, it achieves detection in a single pass, resulting in relatively faster speed.
SSD has the following characteristics:
1. Discretizes the output space of bounding boxes into a series of default boxes with different aspect ratios, allowing box adjustments to better match object shapes.
2. Combines predictions from multiple feature maps with different resolutions to handle objects of varying sizes.
3. Has a simple model structure: SSD places all computations in one network, generally divided into two parts: an image feature extraction network and a classification/detection network.
The following is the SSD architecture diagram. In the original paper, the backbone network is VGG16, followed by 6 convolutional layers to extract 6 feature maps of different scales, enabling detection of objects of various sizes by predicting bounding boxes of different sizes. The backbone network can be replaced with other convolutional networks, leading to SSD variants like MobileNetV2 SSD and ResNet50 SSD. These 6 feature maps are input into the classification/detection network, which predicts on each map sequentially using PaddlePaddle’s fluid.layers.multi_box_head() interface.

A more detailed diagram of the 6 feature maps is shown below:
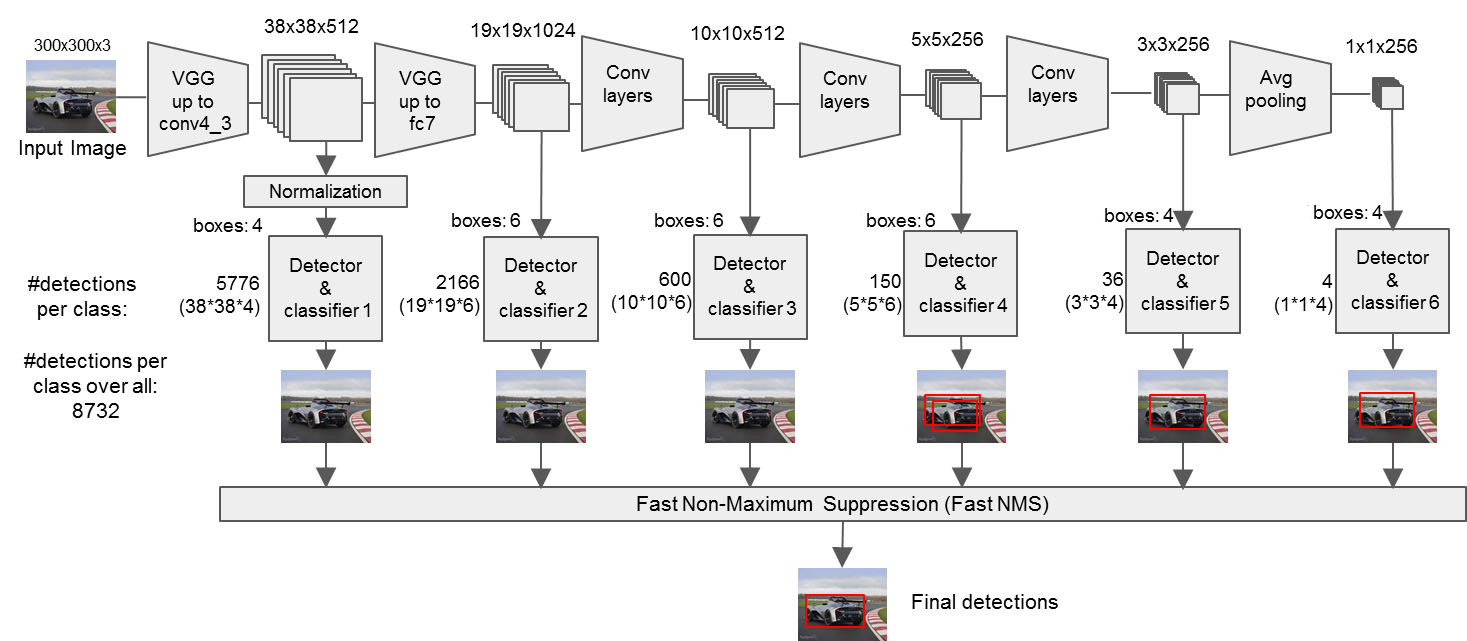
The following is the network model constructed according to the original paper’s parameters, with variations in derived models:
# Backbone network using VGG16 (PaddlePaddle implementation snippet)
conv1 = self.conv_block(self.img, 64, 2)
conv2 = self.conv_block(conv1, 128, 2)
conv3 = self.conv_block(conv2, 256, 3)
Implementation code for the 6 feature maps (as per the paper):
- Feature map 1: 38×38×512
- Feature map 2: 19×19×1024
- Feature map 3: 10×10×512
- Feature map 4: 5×5×256
- Feature map 5: 3×3×256
- Feature map 6: 1×1×256
# 38x38
module11 = self.conv_bn(conv3, 3, 512, 1, 1)
tmp = self.conv_block(module11, 1024, 5)
# 19x19
module13 = fluid.layers.conv2d(tmp, 1024, 1)
# 10x10
module14 = self.extra_block(module13, 256, 512, 1)
# 5x5
module15 = self.extra_block(module14, 128, 256, 1)
# 3x3
module16 = self.extra_block(module15, 128, 256, 1)
# 1x1
module17 = fluid.layers.pool2d(input=module16, pool_type='avg', global_pooling=True)
The classification/detection model is implemented with a single interface in PaddlePaddle. The inputs parameter includes all 6 feature maps. As per the paper, the prior box configuration uses a minimum ratio (min_ratio) of 20% and a maximum ratio (max_ratio) of 90% relative to the input image size (base_size).
mbox_locs, mbox_confs, box, box_var = fluid.layers.multi_box_head(
inputs=[module11, module13, module14, module15, module16, module17],
image=self.img,
num_classes=self.num_classes,
min_ratio=20,
max_ratio=90,
min_sizes=[60.0, 105.0, 150.0, 195.0, 240.0, 285.0],
max_sizes=[[], 150.0, 195.0, 240.0, 285.0, 300.0],
aspect_ratios=[[2.], [2., 3.], [2., 3.], [2., 3.], [2., 3.], [2., 3.]],
base_size=self.img_shape[2],
offset=0.5,
flip=True)
The min_sizes and max_sizes are calculated using:
min_sizes = []
max_sizes = []
step = int(math.floor(((max_ratio - min_ratio)) / (num_layer - 2)))
for ratio in six.moves.range(min_ratio, max_ratio + 1, step):
min_sizes.append(base_size * ratio / 100.)
max_sizes.append(base_size * (ratio + step) / 100.)
min_sizes = [base_size * .10] + min_sizes
max_sizes = [base_size * .20] + max_sizes
PaddlePaddle provides an SSD loss function via fluid.layers.ssd_loss(), which takes location offsets, confidence predictions, candidate boxes, and ground truth boxes/labels to return a weighted sum of regression and classification losses.
loss = fluid.layers.ssd_loss(locs, confs, gt_box, gt_label, box, box_var)
loss = fluid.layers.reduce_sum(loss)
Code Explanation¶
The most critical configuration file in this project is config.py, which contains all training parameters. Key parameters to note when training on your own dataset:
image_shape: Input image dimensions (default: [3, 300, 300]; can also use 512×512).batch_size: Batch size for training (adjust based on hardware).epoc_num: Number of training epochs (saves models after each epoch).lr: Initial learning rate.class_num: Number of classes (including background; e.g., 20 VOC classes → 21).use_model: Model type (resnet_ssd, mobilenet_v2_ssd, mobilenet_v1_ssd, vgg_ssd).label_file: Path to label file (generated bycreate_data_list.py).train_list/test_list: Data lists (generated bycreate_data_list.py).pretrained_model: Path to pre-trained model (from the model download section).use_gpu: Enable GPU training.
The create_data_list.py script generates data lists for dataset classes and labels, supporting only VOC-formatted annotations. If your dataset has the same structure (images/annotations in dataset/images/dataset/annotations with matching filenames), no modifications are needed. The output data list format should be:
dataset/images/00001.jpg dataset/annotations/00001.xml
dataset/images/00002.jpg dataset/annotations/00002.xml
The train.py script uses configurations from config.py. The infer.py script runs standalone prediction, drawing bounding boxes and class names on images. Key parameters here:
- label_file: For class name display.
- score_threshold: Minimum confidence score to display.
- infer_model_path: Path to the prediction model.
The utils/reader.py script processes image/label data into training/test generators, handling image preprocessing and prior box generation via utils/image_util.py (includes data augmentation).
Four model implementations are in the nets folder: mobilenet_v1_ssd.py, mobilenet_v2_ssd.py, vgg_ssd.py, and resnet_ssd.py.
Source Code Repository¶
Open-source repository address: https://github.com/yeyupiaoling/PaddlePaddle-SSD